Redis 高阶应用
虽然市面上有很多优秀的消息中间件如 RocketMQ、Kafka 等,但对于应用场景较为简单,只需要简单的消息传递,比如任务调度、简单的通知系统等,不需要复杂的消息路由、事务支持的业务来说,用那些专门的消息中间件成本就显得过高。Redis 本身就是就是以性能著称,因此完全符合高性能的要求,其次使用 Redis 的 incr 命令可以保证递增性,配合相应的分布式 ID 生成算法便可以实现唯一性和安全
生成全局唯一 ID
-
全局唯一 ID 需要满足以下要求:
-
唯一性:在分布式环境中,要全局唯一
-
高可用:在高并发情况下保证可用性
-
高性能:在高并发情况下生成 ID 的速度必须要快,不能花费太长时间
-
递增性:要确保整体递增的,以便于数据库创建索引
-
安全性:ID 的规律性不能太明显,以免信息泄露
从上面的要求可以看出,全局 ID 生成器的条件还是比较苛刻的,而 Redis 恰巧可以满足以上要求。
Redis 本身就是就是以性能著称,因此完全符合高性能的要求,其次使用 Redis 的 incr 命令可以保证递增性,配合相应的分布式 ID 生成算法便可以实现唯一性和安全性,Redis 可以通过哨兵、主从等集群方案来保证可用性。因此 Redis 是一个不错的选择。
下面我们就写一个简单的示例,来让大家感受一下,实际工作中大家可以根据需要进行调整:
@Component
public class IDUtil{
//开始时间戳(单位:秒) 2000-01-01 00:00:00
private static final long START_TIMESTAMP = 946656000L;
//Spring Data Redis 提供的 Redis 操作模板
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* 获取 ID 格式:时间戳+序列号
* @param keyPrefix Redis 序列号前缀
* @return 生成的 ID
*/
public long getNextId(String keyPrefix){
//获取当前时间戳
LocalDateTime now = LocalDateTime.now();
long nowTimestamp = now.toEpochSecond(ZoneOffset.UTC);
//获取 ID 时间戳
long timestamp = nowSecond - START_TIMESTAMP;
//获取当前日期
String date = now.format(DateTimeFormatter.ofPattern("yyyyMMdd"));
//生成 key
String key = "incr:" + keyPrefix + ":" + date;
//获取序列号
long count = stringRedisTemplate.opsForValue().increment(key);
//生成 ID 并返回
return timestamp << 32 | count;
}
}
分布式锁
在 JVM 内部会有一个锁监视器来控制线程间的互斥,但在分布式的环境下会有多台机器部署同样的服务,也就是说每台机器都会有自己的锁监视器。而 JVM 的锁监视器只能保证自己内部线程的安全执行,并不能保证不同机器间的线程安全执行,因此也很难避免高并发带来的线程安全问题。因此就需要分布式锁来保证整个集群的线程的安全,而分布式锁需要满足 5 点要求:多进程可见、互斥性、高可用、高性能、安全性
其中核心要求就是多进程之间互斥,而满足这一点的方式有很多,最常见的有三种:mysql、Redis、Zookeeper。

通过对比我们发现,其中 Redis 的效果最理想,所以下面就用 Redis 来实现一个简单的分布式锁。
public class DistributedLockUtil {
//分布式锁前缀
private static final String KEY_PREFIX = "distributed:lock:";
//业务名
private String business;
//分布式锁的值
private String value;
//Spring Data Redis 提供的 Redis 操作模板
private StringRedisTemplate stringRedisTemplate;
//私有化无参构造
private DistributedLockUtil(){}
//有参构造
public DistributedLockUtil(String business,StringRedisTemplate stringRedisTemplate){
this.business = business;
this.stringRedisTemplate = stringRedisTemplate;
this.value = UUID.randomUUID().toString();
}
/**
* 尝试获取锁
* @param timeout 超时时间(单位:秒)
* @return 锁是否获取成功
*/
public boolean tryLock(long timeout){
//生成分布式锁的 key
StringBuffer keyBuffer = new StringBuffer(KEY_PREFIX);
keyBuffer.append(business);
Boolean success = stringRedisTemplate.opsForValue().setIsAbsent(keyBuffer.toString(),value,timeout, TimeUnit.SECONDS);
//返回结果 注意:为了防止自动拆箱时出现空指针,所以这里用了 equals 判断
return Boolean.TRUE.equals(success);
}
/**
* 释放锁(不安全版)
*/
public void unLock(){
//生成分布式锁的 key
StringBuffer keyBuffer = new StringBuffer(KEY_PREFIX);
keyBuffer.append(business);
//获取分布式锁的值
String redisValue = stringRedisTemplate.opsForValue().get(keyBuffer.toString());
//判断值是否一致,防止误删
if (value.equals(redisValue)) {
//当代码执行到这里时,如果 JVM 恰巧执行了垃圾回收(虽然几率极低),就会导致所有线程阻塞等待,因此这里仍然会有线程安全的问题
stringRedisTemplate.delete(keyBuffer.toString());
}
}
/**
* 通过脚本释放锁(彻底解决线程安全问题)
*/
public void unLockWithScript(){
//加载 lua 脚本,实际工作中我们可以将脚本设置为常量,并在静态代码块中初始化(脚本内容在下文)
DefaultRedisScript<Long> script = new DefaultRedisScript<>();
script.setLocation(new ClassPathResource("unlock.lua"));
script.setResultType(Long.class);
//生成分布式锁的 key
StringBuffer keyBuffer = new StringBuffer(KEY_PREFIX);
keyBuffer.append(business);
//调用 lua 脚本释放锁
stringRedisTemplate.execute(script,
Collections.singletonList(keyBuffer.toString()),
value);
}
}
lua 脚本内容如下:
-- 判断值是否一致,防止误删
if(redis.call('get',KEYS[1]) == VRGV[1]) then
-- 判断通过,释放锁
return redis.call('del',KEYS[1])
end
-- 判断不通过,返回 0
return 0
虽然通过 lua 脚本解决了线程不安全的问题,但是仍然存在以下问题:
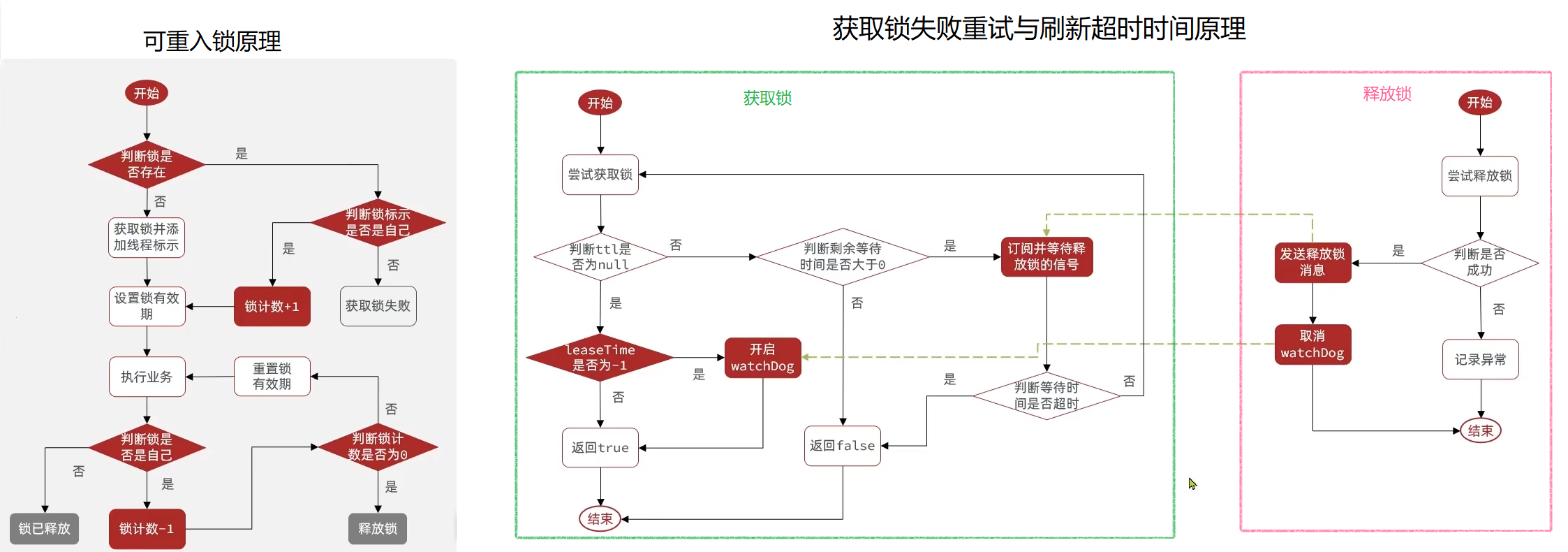
- 不可重入:同一个线程无法多次获取同一把锁
- 不可重试:获取锁只能尝试一次,失败就返回 false,没有重试机制
- 超时释放:锁超时释放虽然可以避免死锁,但如果业务执行耗时较长,也会导致锁释放,存在安全隐患
- 主从一致性:如果 Redis 提供了主从集群,主从同步存在延迟,当主机宕机时,如果从机还没来得及同步主机的锁数据,则会出现锁失效。
要解决以上问题也非常简单,只需要利用 Redis 的 hash 结构记录线程标识和重入次数就可以解决不可重入的问题。利用信号量和 PubSub 功能实现等待、唤醒,获取锁失败的重试机制即可解决不可重试的问题。而超时释放的问题则可以通过获取锁时为锁添加一个定时任务(俗称看门狗),定期刷新锁的超时时间即可。至于主从一致性问题,我们只需要利用多个独立的 Redis 节点(非主从),必须在所有节点都获取重入锁,才算获取锁成功。

有的人可能说了,虽然说起来简单,但真正实现起来也不是很容易呀。对于这种问题,大家不用担心,俗话说得好想要看的更远,需要站在巨人的肩膀上。对于上述的需求,早就有了成熟的开源方案 Redisson ,我们直接拿来用就可以了,无需重复造轮子,具体使用方法可以查看官方文档。
轻量化消息队列
虽然市面上有很多优秀的消息中间件如 RocketMQ、Kafka 等,但对于应用场景较为简单,只需要简单的消息传递,比如任务调度、简单的通知系统等,不需要复杂的消息路由、事务支持的业务来说,用那些专门的消息中间件成本就显得过高。因此我们就可以使用 Redis 来做消息队列。
Redis 提供了三种不同的方式来实现消息队列:
- list 结构:可以使用 list 来模拟消息队列,可以使用 BRPOP 或 BLPOP 命令来实现类似 JVM 阻塞队列的消息队列。
- PubSub:基于发布/订阅的消息模型,但不支持数据持久化,且消息堆积有上限,超出时数据丢失。
- Stream:Redis 5.0 新增的数据类型,可以实现一个功能非常完善的消息队列,也是我们实现消息队列的首选。

下面我就采用 Redis 的 Stream 实现一个简单的案例来让大家感受一下,实际工作中大家可以根据需要进行调整:
public class RedisQueueUtil{
//Spring Data Redis 提供的 Redis 操作模板
private StringRedisTemplate stringRedisTemplate;
/**
* 获取消息队列中的数据,执行该方法前,一定要确保消费者组已经创建
* @param queueName 队列名
* @param groupName 消费者组名
* @param consumerName 消费者名
* @param type 返回值类型
* @return 消息队列中的数据
*/
public <T> T getQueueData(String queueName, String groupName, String consumerName, Class<T> type){
while (true){
try {
//获取消息队列中的信息
List<MapRecord<String,Object,Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from(groupName,consumerName),
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create(queueName, ReadOffset.lastConsumed())
);
//判断消息是否获取成功
if (list == null || list.isEmpty()){
//如果获取失败,说明没有消息,继续下一次循环
continue;
}
//如果获取成功,则解析消息中的数据
MapRecord<String,Object,Object> record = list.get(0);
Map<Object,Object> values = record.getValue();
String jsonString = JSON.toJSONString(values);
T result = JSON.parseObject(jsonString, type);
// ACK
stringRedisTemplate.opsForStream().acknowledge(queueName,groupName,record.getId());
//返回结果
return result;
}catch (Exception e){
while (true){
try {
//获取 pending-list 队列中的信息
List<MapRecord<String,Object,Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from(groupName,consumerName),
StreamReadOptions.empty().count(1)),
StreamOffset.create(queueName,ReadOffset.from("0")
);
//判断消息是否获取成功
if (list == null || list.isEmpty()){
//如果获取失败,说明 pending-list 没有异常消息,结束循环
break;
}
//如果获取成功,则解析消息中的数据
MapRecord<String,Object,Object> record = list.get(0);
Map<Object,Object> values = record.getValue();
String jsonString = JSON.toJSONString(values);
T result = JSON.parseObject(jsonString, type);
// ACK
stringRedisTemplate.opsForStream().acknowledge(queueName,groupName,record.getId());
//返回结果
return result;
}catch (Exception ex){
log.error("处理 pending-list 订单异常",ex);
try {
Thread.sleep(50);
}catch (InterruptedException err){
err.printStackTrace();
}
}
}
}
}
}
/**
* 向消息队列中发送数据
* @param queueName 消息队列名
* @param map 要发送数据的集合
*/
public void sendQueueData(String queueName, Map<String,Object> map){
StringBuilder builder = new StringBuilder("redis.call('xadd','");
builder.append(queueName).append("','*','");
Set<String> keys = map.keySet();
for(String key:keys){
builder.append(key).append("','").append(map.get(key)).append("','");
}
String script = builder.substring(0, builder.length() - 2);
script += ")";
stringRedisTemplate.execute(new DefaultRedisScript<Long>(script,Long.class),Collections.emptyList());
}
}

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)