分布式系列之限流组件
概述、应用场景;限流算法:计数器算法、固定窗口、滑动窗口、漏桶算法、令牌桶算法、漏桶算法和令牌桶算法的区别;限流环节:网关限流、Nginx、ngx_http_limit_conn_module、ngx_http_limit_req_module、服务限流、接口限流;限流框架:Guava RateLimiter、Spring Cloud GateWay、Sentinel、Bucket4j、Resil
概述
在高并发场景下,请求量瞬间到达,后端服务器即使有缓存、集群主备、分库分表、容错降级等措施,也有可能扛不住这请求量,因此可考虑引入限流组件。限流的目的:防止恶意请求流量或流量超出系统承载。
应用场景:
- 网关层校验流量,拦截非法请求,或直接抛弃部分流量(后来的流量,如秒杀系统)
- 实时场景下的数据迁移或复制(如Kafka分区重分配)
本文从限流算法、限流环节、限流框架几个层次加以讲述。
限流算法
主要有两大类:窗口算法(也有叫做计数器算法的,思想其实很类似,包括固定窗口算法和滑动窗口算法)、桶算法(包括漏桶算法、令牌桶算法)。
计数器算法
该算法会维护一个counter,规定在单位时间内counter的大小不能超过最大值,每隔固定时间就将counter的值置零。如果这个counter大于设定的阈值,那么系统就开始拒绝请求以保护系统的负载。
固定窗口
固定窗口就是指定的单位时间,比如一分钟,限制次数为Max,则最大值为Max,超过Max的请求被抛弃。存在临界问题:单位时间的左区间可能有大量请求,直接超过Max。
/**
* 指定过期时间自增计数器,默认每次+1,非滑动窗口
*
* @param key 计数器自增key
* @param expireTime 过期时间
* @param unit 时间单位
*/
public long incrCount(String key, int expireTime, TimeUnit unit);
/**
* 指定过期时间自增计数器,单位时间内超过最大值rateThreshold返回true,否则返回false
*
* @param key 限流key
* @param rateThreshold 限流阈值
* @param expireTime 固定窗口时间
* @param unit 时间单位
*/
public boolean rateLimit(final String key, final int rateThreshold, int expireTime, TimeUnit unit);
滑动窗口
固定窗口可看成是滑动窗口的特例。滑动窗口将固定窗口再等分为多个小的窗口,每一次对一个小的窗口进行流量控制。可解决固定窗口的临界问题。
漏桶算法
Leaky Bucket,水(请求)先进入到漏桶(预先维护的容量固定)里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,漏桶算法能强行限制数据的传输速率。

核心:请求来以后,直接进桶,然后桶根据自己的漏洞大小慢慢往外面漏。使用一个FIFO的队列,一端负责不断的放入请求,另外一端负责吐出请求。
好处:可将系统的处理能力维持在一个比较平稳的水平
缺点:不能应对实际场景,比如突然暴增的流量。
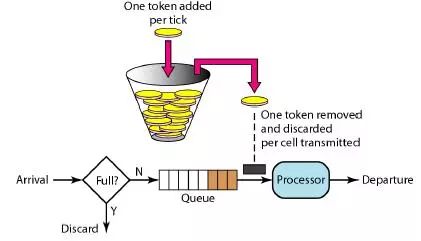
令牌桶算法
Token Bucket Algorithm,用于限制速率。
令牌桶会以一个恒定的速率(预定义)向固定容量(要限制流量的大小)大小桶中放入令牌,当有流量来时则取走一个或多个令牌。当桶中没有令牌则将当前请求丢弃或阻塞等待,直到有足够的令牌为止。可实现平滑突发限流,允许一定的突发请求,但总体速率会保持在设定的限制内。

参考实现:Guava RateLimiter
漏桶算法和令牌桶算法对比
令牌桶算法和漏桶算法的不同之处在于处理瞬间到达的大流量的不同:
- 令牌桶算法由于在令牌桶里攒很多令牌,因此在大流量到达一瞬间可以一次性将队列中所有的请求都处理完,然后按照恒定的速度处理请求;
- 漏桶算法则一直有一个恒等的阈值,在大流量到达时,也会将多余的请求拒绝。
限流环节
限流从环节(也有叫粒度)来分析,有:网关限流,服务限流,接口限流。
网关限流
网关,即接入层,是请求流量的入口,一般可考虑使用Nginx限流。
Nginx自带两个模块:
- 连接数限流模块:ngx_http_limit_conn_module(简称
limit_conn,如果读者们在某些书籍或Blog里看到这个简称,就表示这个模块) - 请求限流模块:基于漏桶算法实现,ngx_http_limit_req_module(简称
limit_req,同上)。
此外,可以使用OpenResty提供的lua限流模块lua-resty-limit-traffic,以及tengine增强版httplimitreqcn。
limit_conn
limit_conn模块用于限制连接数量,特别是来自单个IP地址的连接数量。并非所有的连接都被计数。只有当服务器处理完请求且已经读取整个请求头时,连接才被计数。
官网的示例配置:
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /download/ {
limit_conn addr 1;
}
}
}
配置解读:
limit_conn_zone $binary_remote_addr zone=addr:10m;:为共享内存区域设置参数,该区域将保留各种Key键的状态。状态包含当前的连接数。Key可以包含文本,变量,他们的组合。只能用于http语法块。
$binary_remote_addr:对于IPv4地址,变量的大小始终为4个字节,对于IPv6地址则为16个字节。存储状态在32位平台上始终占用32或64个字节,在64位平台上占用64个字节。一个兆字节的区域可保存大约32000个32字节的状态或大约16000个64字节的状态。如果区域存储耗尽,服务器会将错误返回给所有其他请求。10M可存储160000个状态。
limit_conn addr 1:设置给定键值的共享内存区域和最大允许连接数。超过此限制时,服务器将返回503错误以回复请求。用于http,server,location这些语法块内。
limit_req
用于限制每一个请求的处理速率,即每个IP地址的请求的处理速率。
官网的示例配置:
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=5;
}
}
配置解读:
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;:区域名称为one,大小为10m,平均处理的请求频率不能超过每秒一次。键值是客户端IP,$binary_remote_addr变量,可以将每条状态记录的大小减少到64个字节,这样1M的内存可以保存大约1万6千个64字节的记录。如果限制域的存储空间耗尽,对于后续所有请求,服务器都会返回503错误。
limit_req zone=one burst=5;:平均每秒不超过1个请求,并且突发不超过5个请求。超过处理能力范围的,直接drop,表现为对收到的请求无延时。
服务限流
应用级别,对应用里涉及到的所有的接口类和方法都增加限流机制。
接口限流
接口层次的限流,粒度最小,用于某个Controller类或方法,
限流框架
Guava RateLimiter
Guava提供的抽象类RateLimiter源码很长,略。用于限制方法的调用频率,它基于令牌桶算法
其实现类有两个,对应两种限流模式:
- SmoothBursty:稳定模式,令牌生成速度恒定,平滑突发限流;
- SmoothWarmingUp:渐进模式,令牌生成速度缓慢提升直到维持在一个稳定值,平滑预热限流
两种模式实现思路类似,主要区别在等待时间的计算上。
局限性:
- 仅适用于单体应用
- 不保证公平性访问
Spring Cloud GateWay
需要引入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--基于 reactive stream 的redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
引入spring-cloud-starter-gateway后,则引入子依赖spring-cloud-gateway-server,后者源码里带有request_rate_limiter.lua脚本:

配置:
spring:
cloud:
gateway:
routes:
- id: requestratelimiter_route
uri: lb://gateway-demo
order: 10000
predicates:
- Path = /admin/**
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 1 # 流速每秒1个
redis-rate-limiter.burstCapacity: 3 # 令牌桶容积
key - resolver: "#{@remoteAddrKeyResolver}" # SPEL表达式去的对应的bean
- StripPrefix = 1
配置Bean方法,多维度限流量的入口:
@Bean
KeyResolver remoteAddrKeyResolver() {
return exchange -> Mono.just(exchange.getRequest().getRemoteAddress().getHostName());
}
GateWay提供RateLimiter接口,AbstractRateLimiter抽象类,以及实现类RedisRateLimiter,接口主要有一个方法Mono<Response> isAllowed(String routeId, String id);,RedisRateLimter核心源码:
public Mono<Response> isAllowed(String routeId, String id) {
Config routeConfig = getConfig().getOrDefault(routeId, defaultConfig);
int replenishRate = routeConfig.getReplenishRate();
int burstCapacity = routeConfig.getBurstCapacity();
try {
List<String> keys = getKeys(id);
/* returns unixtime in seconds.*/
List<String> scriptArgs = Arrays.asList(replenishRate + "", burstCapacity + "", Instant.now().getEpochSecond() + "", "1");
// 核心,执行redis LUA脚本
Flux<List<Long>> flux = this.redisTemplate.execute(this.script, keys, scriptArgs);
return flux.onErrorResume(throwable -> Flux.just(Arrays.asList(1L, -1L))).reduce(new ArrayList<Long>(), (longs, l) -> {
longs.addAll(l);
return longs;
}).map(results -> {
boolean allowed = results.get(0) == 1L;
Long tokensLeft = results.get(1);
Response response = new Response(allowed, getHeaders(routeConfig, tokensLeft));
if (log.isDebugEnabled()) {
log.debug("response: " + response);
}
return response;
});
} catch (Exception e) {
log.error("Error determining if user allowed from redis", e);
}
return Mono.just(new Response(true, getHeaders(routeConfig, -1L)));
}
Sentinel
另起一篇,参考服务容错框架Sentinel入门。
Bucket4j
Bucket4j是一个基于令牌桶算法实现的强大的限流库,支持单机限流,还支持通过诸如Hazelcast、Ignite、Coherence、Infinispan或其他兼容 JCache API(JSR 107)规范的分布式缓存实现分布式限流。
3个核心概念:Bucket、Bandwidth、Refill。
Bucket:接口,代表令牌桶的具体实现,操作的入口。提供诸如tryConsume和tryConsumeAndReturnRemaining方法用于消费令牌。可通过下面的构造方法来创建Bucket:
Bucket bucket = Bucket4j.builder().addLimit(limit).build();
if (bucket.tryConsume(1)) {
log.info("ok");
} else {
log.info("error");
}
Bandwidth:带宽,可理解为限流规则。Bucket4j提供两种方法来创建Bandwidth:
- simple:桶大小和填充速度是一样的,表示桶大小为10,填充速度为每分钟10个令牌:
Bandwidth limit = Bandwidth.simple(10, Duration.ofMinutes(1));
- classic:更灵活,可自定义填充速度:
// 贪婪策略:桶大小为10,填充速度为每分钟5个令牌;
Refill filler = Refill.greedy(5, Duration.ofMinutes(1));
Bandwidth limit = Bandwidth.classic(10, filler);
Refill:用于填充令牌桶,可以通过它定义填充速度,Bucket4j有两种填充令牌的策略:
- intervally:间隔策略。间隔策略创建Refill:
Refill filler = Refill.intervally(5, Duration.ofMinutes(1));// 每隔一分钟,填充 5 个令牌
所谓间隔策略指的是每隔一段时间,一次性的填充所有令牌。 - greedy:贪婪策略,参考上面的简单例子
Resilience4j
Resilience4j是一款轻量级、易使用的高可用框架,设计灵感就来自于Netflix Hystrix。自从Hystrix停止维护之后,官方也推荐使用Resilience4j来代替Hystrix。
Resilience4j的底层采用Vavr(一个非常轻量级的Java函数式库),以装饰器模式提供对函数式接口或lambda表达式的封装,提供高可用机制:重试(Retry)、熔断(Circuit Breaker)、限流(RateLimiter)、限时(Timer Limiter)、隔离(Bulkhead)、缓存(Cache)和降级(Fallback)。
其中,RateLimiter是请求频率限流,Bulkhead是并发量限流。
Resilience4j提供两种限流的实现:SemaphoreBasedRateLimiter和AtomicRateLimiter。SemaphoreBasedRateLimiter基于信号量实现,用户的每次请求都会申请一个信号量,并记录申请的时间,申请通过则允许请求,申请失败则限流,另外有一个内部线程会定期扫描过期的信号量并释放,很显然这是令牌桶的算法。AtomicRateLimiter和上面的经典实现类似,不需要额外的线程,在处理每次请求时,根据距离上次请求的时间和生成令牌的速度自动填充。
Resilience4j也提供两种隔离的实现:SemaphoreBulkhead和ThreadPoolBulkhead,通过信号量或线程池控制请求的并发数。
同时使用限流和隔离的例子:
// 创建一个Bulkhead,最大并发量为150
BulkheadConfig bulkheadConfig = BulkheadConfig.custom()
.maxConcurrentCalls(150)
.maxWaitTime(100)
.build();
Bulkhead bulkhead = Bulkhead.of("backendName", bulkheadConfig);
// 创建RateLimiter,每秒允许一次请求
RateLimiterConfig rateLimiterConfig = RateLimiterConfig.custom()
.timeoutDuration(Duration.ofMillis(100))
.limitRefreshPeriod(Duration.ofSeconds(1))
.limitForPeriod(1)
.build();
RateLimiter rateLimiter = RateLimiter.of("backendName", rateLimiterConfig);
// 使用Bulkhead和RateLimiter装饰业务逻辑
Supplier<String> supplier = () -> backendService.doSomething();
Supplier<String> decoratedSupplier = Decorators.ofSupplier(supplier)
.withBulkhead(bulkhead)
.withRateLimiter(rateLimiter)
.decorate();
// 调用业务逻辑
Try<String> try = Try.ofSupplier(decoratedSupplier);
assertThat(try.isSuccess()).isTrue();
Resilience4j在功能特性上比Bucket4j强大不少,而且还支持并发量限流,但不支持分布式限流。
拓展
TimeLimiter和RateLimiter
除了RateLimiter,在Guava包里还有个TimeLimiter接口:
@DoNotMock("Use FakeTimeLimiter")
@ElementTypesAreNonnullByDefault
@J2ktIncompatible
@GwtIncompatible
public interface TimeLimiter {
<T> T newProxy(T target, Class<T> interfaceType, long timeoutDuration, TimeUnit timeoutUnit);
default <T> T newProxy(T target, Class<T> interfaceType, Duration timeout) {
return this.newProxy(target, interfaceType, Internal.toNanosSaturated(timeout), TimeUnit.NANOSECONDS);
}
@ParametricNullness
@CanIgnoreReturnValue
<T> T callWithTimeout(Callable<T> callable, long timeoutDuration, TimeUnit timeoutUnit) throws TimeoutException, InterruptedException, ExecutionException;
@ParametricNullness
@CanIgnoreReturnValue
default <T> T callWithTimeout(Callable<T> callable, Duration timeout) throws TimeoutException, InterruptedException, ExecutionException {
return this.callWithTimeout(callable, Internal.toNanosSaturated(timeout), TimeUnit.NANOSECONDS);
}
@ParametricNullness
@CanIgnoreReturnValue
<T> T callUninterruptiblyWithTimeout(Callable<T> callable, long timeoutDuration, TimeUnit timeoutUnit) throws TimeoutException, ExecutionException;
@ParametricNullness
@CanIgnoreReturnValue
default <T> T callUninterruptiblyWithTimeout(Callable<T> callable, Duration timeout) throws TimeoutException, ExecutionException {
return this.callUninterruptiblyWithTimeout(callable, Internal.toNanosSaturated(timeout), TimeUnit.NANOSECONDS);
}
void runWithTimeout(Runnable runnable, long timeoutDuration, TimeUnit timeoutUnit) throws TimeoutException, InterruptedException;
default void runWithTimeout(Runnable runnable, Duration timeout) throws TimeoutException, InterruptedException {
this.runWithTimeout(runnable, Internal.toNanosSaturated(timeout), TimeUnit.NANOSECONDS);
}
void runUninterruptiblyWithTimeout(Runnable runnable, long timeoutDuration, TimeUnit timeoutUnit) throws TimeoutException;
default void runUninterruptiblyWithTimeout(Runnable runnable, Duration timeout) throws TimeoutException {
this.runUninterruptiblyWithTimeout(runnable, Internal.toNanosSaturated(timeout), TimeUnit.NANOSECONDS);
}
}
其实现类有:
- SimpleTimeLimiter:
- FakeTimeLimiter:
TimeLimiter用于限制方法的执行时间,原理:
- 创建代理对象:为指定的对象创建一个代理对象
- 方法拦截:当调用代理对象的方法时,TimeLimiter会拦截调用,并在一个单独的线程中执行实际方法
- 超时监控:使用定时器来监控方法的执行时间。如果方法执行超过指定的时间限制,TimeLimiter会中断该线程,并抛出一个TimeoutException
TimeLimiter可确保方法不会因为执行时间过长而阻塞其他操作。有如下使用场景:
- 网络调用:限制网络请求的最大时间,防止由于网络延迟导致的长时间阻塞
- 复杂计算:在后台执行复杂计算任务时,设置一个时间限制以确保任务不会无限期地运行
- 资源获取:限制资源获取操作的时间,如数据库连接、文件读写等。
TimeLimiter的一个简单实例:
public void test() {
TimeLimiter timeLimiter = SimpleTimeLimiter.create();
Callable<String> callable = () -> {
// Simulate long running task
Thread.sleep(2000);
return "Task Completed";
};
try {
String result = timeLimiter.callWithTimeout(callable, 1, TimeUnit.SECONDS);
System.out.println(result);
} catch (UncheckedTimeoutException e) {
// just logging or handle exception
} catch (Exception e) {
// just logging or handle exception
}
}
TimeLimiter和RateLimiter的区别
- 用途:TimeLimiter用于限制方法的执行时间,防止长时间运行的操作阻塞程序。RateLimiter用于限制方法的调用频率,控制流量,防止系统过载
- 实现机制:TimeLimiter基于创建代理对象和超时监控,通过定时器中断执行时间过长的任务。RateLimiter基于令牌桶算法,通过生成和消耗令牌来控制请求的执行频率。
- 使用场景:TimeLimiter适用于需要对单个任务的执行时间进行严格控制的场景。RateLimiter适用于需要对系统整体调用频率进行控制的场景。
Kafka
Kafka在时使用到复制限流技术,防止集群中某个主题或某个分区的流量在某段时间内特别大,分区数据复制造成数据丢失或分区节点异常。
ZooKeeper
ZK也提供一个RateLimiter的简易实现版本。
分布式限流
参考
- 亿级流量网站架构核心技术
- 实战Spring Cloud Gateway之限流篇

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 34
34 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)