
canal 连接kafka (docker),如何才能更容易拿到大厂Offer
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
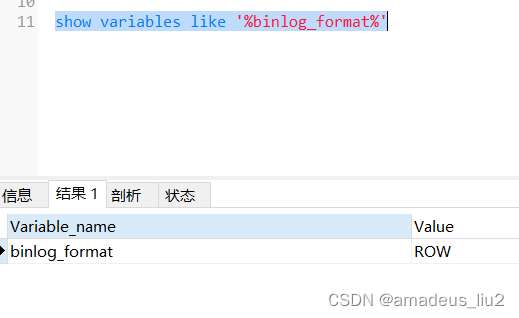

一定要确保上述两个值一个为ROW,一个为ON
二、下载canal的run.sh
https://github.com/alibaba/canal/blob/master/docker/run.sh
三、启动canal容器,其中配置了mysql的信息和kafka的信息:
./run.sh -e canal.auto.scan=false -e canal.destinations=me -e canal.instance.master.address=xx.xx.xx.xx:3306 -e canal.instance.dbUsername=root -e canal.instance.dbPassword=yourpassword -e canal.instance.connectionCharset=UTF-8 -e canal.instance.tsdb.enable=true -e canal.instance.gtidon=false -e canal.instance.topic=me -e canal.mq.partition=0 -e canal.mq.topic=me
四、通过docker exec -it canal-server /bin/bash进入canal容器,编辑容器中的
/home/admin/canal-server/conf/canal.properties
其中要修改两处,一是工作模式改为kafka(canal.serverMode),二是改MQ的地址(canal.mq.servers),完整配置类似如下:
#################################################
######### common argument #############
#################################################
canal.id = 1
canal.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
canal.zkServers =
flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
tcp, kafka, RocketMQ
canal.serverMode = kafka
flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
binlog ddl isolation
canal.instance.get.ddl.isolation = false
parallel parser config
canal.instance.parser.parallel = true
concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir =
c
a
n
a
l
.
f
i
l
e
.
d
a
t
a
.
d
i
r
:
.
.
/
c
o
n
f
/
{canal.file.data.dir:../conf}/
canal.file.data.dir:../conf/{canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
purge snapshot expire , default 360 hour(15 days)
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ip1024b (备注运维)**
[外链图片转存中…(img-vVHrVMPq-1713304348330)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)