NIO中Buffer常用flip()方法
手绘了下图所示的kafka知识大纲流程图(xmind文件不能上传,导出图片展现),但都可提供源文件给每位爱学习的朋友《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!图片展现),但都可提供源文件给每位爱学习的朋友[外链图片转存中…(img-WzZsh4sQ-1712657457282)]《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、
- 缓冲区本质上是一个可以写入数据的内存块,之后可以读取数据。 Buffer 对象包装了此内存块,提供了一组方法,可以更轻松地使用内存块。
Buffer通常的操作
-
将数据写入缓冲区
-
调用 buffer.flip() 反转读写模式
-
从缓冲区读取数据
-
调用 buffer.clear() 或 buffer.compact() 清除缓冲区内容
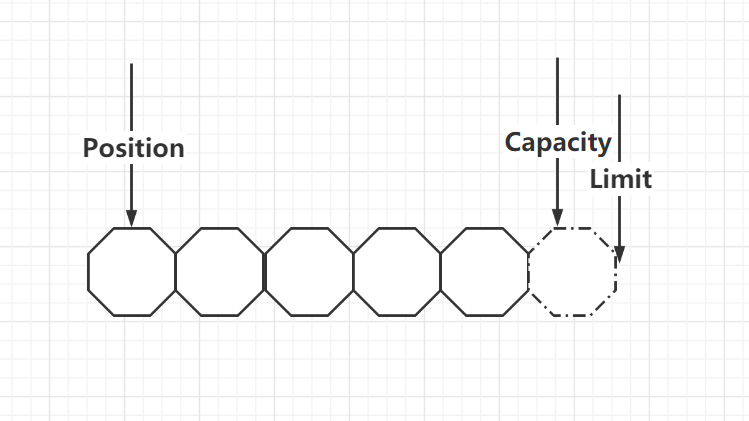
Buffer的重要属性
-
capacity : 容量缓冲区的容量,是它所包含的元素的数量。不能为负并且不能更改。
-
position :缓冲区的位置 是下一个要读取或写入的元素的索引。不能为负,并且不能大于 limit
-
limit : 缓冲区的限制,缓冲区的限制不能为负,并且不能大于 capacity

flip():Buffer有两种模式,写模式和读模式。在写模式下调用flip()之后,Buffer从写模式变成读模式。
那么limit就设置成了position当前的值(即当前写了多少数据),postion会被置为0,以表示读操作从缓存的头开始读,mark置为-1。
调用flip()方法之前,往缓冲区写数据

调用flip()方法后,从写模式变成读模式

让我们一起看一段代码:src/test/resources/index.html中的index.html的数据为abcdefg

首先,我们设置的缓冲区的大小为 4 个字节的大小,当我们运行结果为:

在buffer.flip()方法执行之前,一直在写数据,在buffer.flip()方法执行完之后,Buffer从写模式变成读模式,然后通过这句代码System.out.println(decoder.decode(buffer));打印出了数据为:abcd
1.flip调用之前,一直往缓冲区写数据,由于缓冲区的大小为4个字节,所以只能写abcd,也就是代码中的结果
- S1 : Pos: 4 Limit:4

2.flip调用之后,转换为读模式。Position变为0。
- 运行结果S2 : Pos: 0 Limit:4

3.Decode调用后,打印出结果abcd
- S3 : Pos: 3 Limit:3

4.Clear 调用后
- Position回到0的位置,但是Buffer没有被清空(可以理解为abcd还存在)

- 由于我们有7个数据,但是缓冲区的大小为4,所以我们需要执行两遍代码
5.第二次read后(由于Buffer没有被清空,所以d还存在)
- S1 : Pos: 3 Limit:4

6. 第二次 flip调用之后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
手绘了下图所示的kafka知识大纲流程图(xmind文件不能上传,导出图片展现),但都可提供源文件给每位爱学习的朋友

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
图片展现),但都可提供源文件给每位爱学习的朋友
[外链图片转存中…(img-WzZsh4sQ-1712657457282)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)