Kafka原理
Kafka启动时,会在所有的broker中选择一个controller前面leader和follower是针对partition,而controller是针对broker的创建topic、或者添加分区、修改副本数量之类的管理任务都是由controller完成的Kafka分区leader的选举,也是由controller决定的。
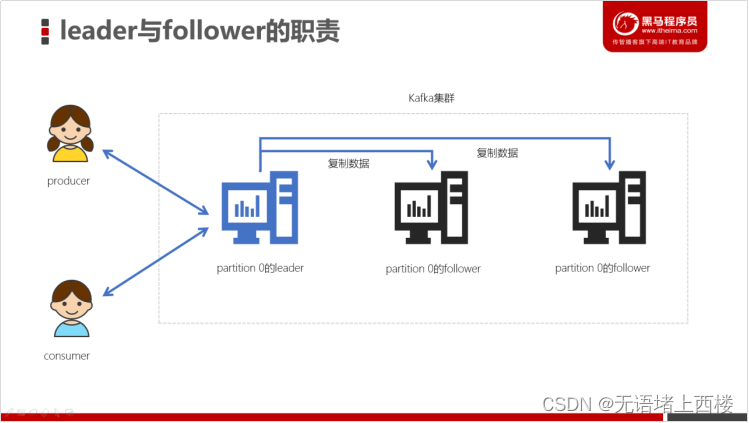
分区的leader与follower
Leader和Follower
在Kafka中,每个topic都可以配置多个分区以及多个副本。每个分区都有一个leader以及0个或者多个follower,在创建topic时,Kafka会将每个分区的leader均匀地分配在每个broker上。我们正常使用kafka是感觉不到leader、follower的存在的。但其实,所有的读写操作都是由leader处理,而所有的follower都复制leader的日志数据文件,如果leader出现故障时,follower就会被选举为leader。所以,可以这样说:
- Kafka中的leader负责处理读写操作,而follower只负责副本数据的同步
- 如果leader出现故障,其他follower会被重新选举为leader
- follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中
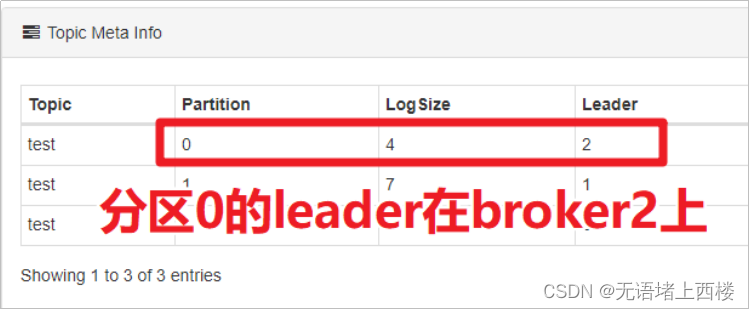
查看某个partition的leader
使用Kafka-eagle查看某个topic的partition的leader在哪个服务器中。为了方便观察,我们创建一个名为test的3个分区、3个副本的topic。
1.点击「Topic」菜单下的「List」
2.任意点击选择一个Topic
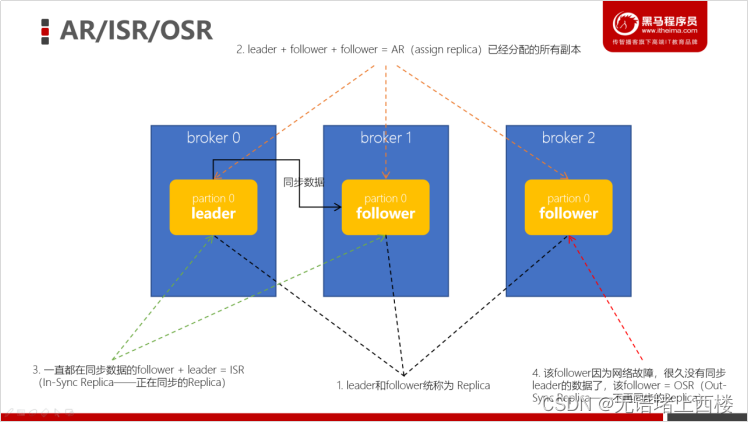
AR、ISR、OSR
在实际环境中,leader有可能会出现一些故障,所以Kafka一定会选举出新的leader。在讲解leader选举之前,我们先要明确几个概念。Kafka中,把follower可以按照不同状态分为三类——AR、ISR、OSR。
- 分区的所有副本称为 「AR」(Assigned Replicas——已分配的副本)
- 所有与leader副本保持一定程度同步的副本(包括 leader 副本在内)组成 「ISR」(In-Sync Replicas——在同步中的副本)
- 由于follower副本同步滞后过多的副本(不包括 leader 副本)组成 「OSR」(Out-of-Sync Replias)
- AR = ISR + OSR
- 正常情况下,所有的follower副本都应该与leader副本保持同步,即AR = ISR,OSR集合为空。
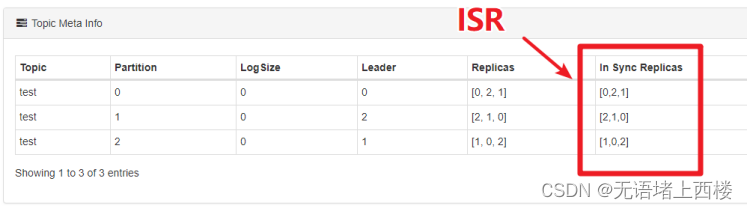
查看分区的ISR
1.使用Kafka Eagle查看某个Topic的partition的ISR有哪几个节点。
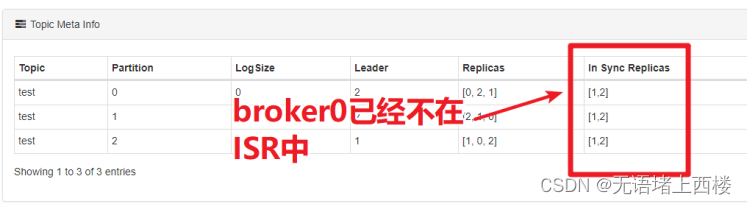
2.尝试关闭id为0的broker(杀掉该broker的进程),参看topic的ISR情况。
Leader选举
leader对于消息的写入以及读取是非常关键的,此时有两个疑问:
- Kafka如何确定某个partition是leader、哪个partition是follower呢?
- 某个leader崩溃了,如何快速确定另外一个leader呢?因为Kafka的吞吐量很高、延迟很低,所以选举leader必须非常快
如果leader崩溃,Kafka会如何
使用Kafka Eagle找到某个partition的leader,再找到leader所在的broker。在Linux中强制杀掉该Kafka的进程,然后观察leader的情况。
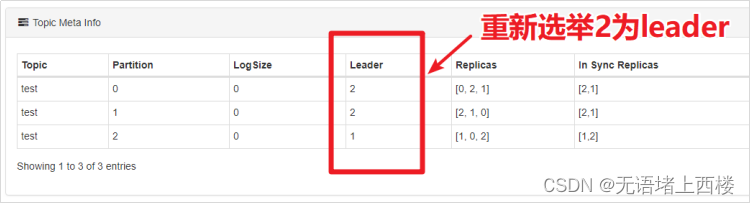
通过观察,我们发现,leader在崩溃后,Kafka又从其他的follower中快速选举出来了leader。
Controller介绍
- Kafka启动时,会在所有的broker中选择一个controller
- 前面leader和follower是针对partition,而controller是针对broker的
- 创建topic、或者添加分区、修改副本数量之类的管理任务都是由controller完成的
- Kafka分区leader的选举,也是由controller决定的
Controller的选举
- 在Kafka集群启动的时候,每个broker都会尝试去ZooKeeper上注册成为Controller(ZK临时节点)
- 但只有一个竞争成功,其他的broker会注册该节点的监视器
- 一点该临时节点状态发生变化,就可以进行相应的处理
- Controller也是高可用的,一旦某个broker崩溃,其他的broker会重新注册为Controller
找到当前Kafka集群的controller
1.点击Kafka Tools的「Tools」菜单,找到「ZooKeeper Brower...」
2.点击左侧树形结构的controller节点,就可以查看到哪个broker是controller了。
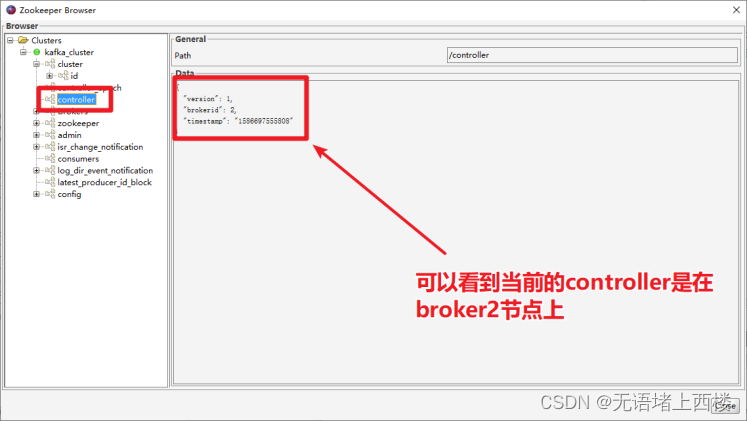
测试controller选举
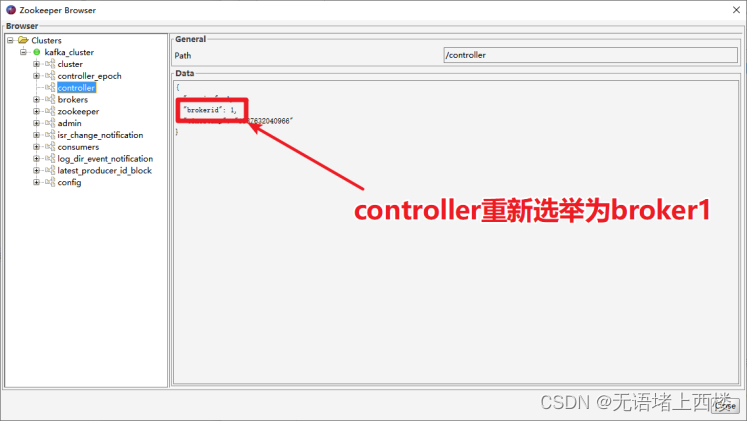
通过kafka tools找到controller所在的broker对应的kafka进程,杀掉该进程,重新打开ZooKeeper brower,观察kafka是否能够选举出来新的Controller。
Controller选举partition leader
- 所有Partition的leader选举都由controller决定
- controller会将leader的改变直接通过RPC的方式通知需为此作出响应的Broker
- controller读取到当前分区的ISR,只要有一个Replica还幸存,就选择其中一个作为leader否则,则任意选这个一个Replica作为leader
- 如果该partition的所有Replica都已经宕机,则新的leader为-1
为什么不能通过ZK的方式来选举partition的leader?
- Kafka集群如果业务很多的情况下,会有很多的partition
- 假设某个broker宕机,就会出现很多的partiton都需要重新选举leader
- 如果使用zookeeper选举leader,会给zookeeper带来巨大的压力。所以,kafka中leader的选举不能使用ZK来实现
leader负载均衡
Preferred Replica
- Kafka中引入了一个叫做「preferred-replica」的概念,意思就是:优先的Replica
- 在ISR列表中,第一个replica就是preferred-replica
- 第一个分区存放的broker,肯定就是preferred-replica
-
执行以下脚本可以将preferred-replica设置为leader,均匀分配每个分区的leader。
./kafka-leader-election.sh --bootstrap-server node1.itcast.cn:9092 --topic 主题 --partition=1 --election-type preferred确保leader在broker中负载均衡
杀掉test主题的某个broker,这样kafka会重新分配leader。等到Kafka重新分配leader之后,再次启动kafka进程。此时:观察test主题各个分区leader的分配情况。
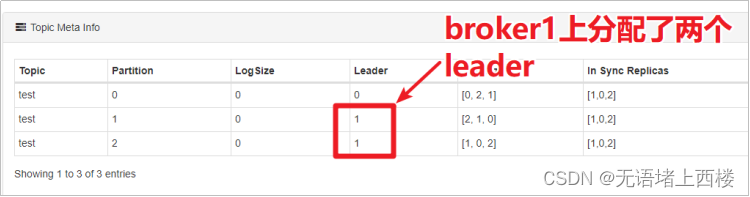
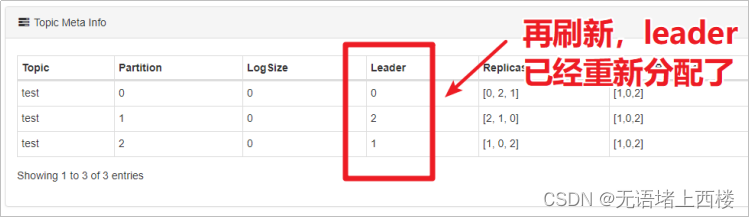
此时,会造成leader分配是不均匀的,所以可以执行以下脚本来重新分配leader:
bin/kafka-leader-election.sh --bootstrap-server node1.itcast.cn:9092 --topic test --partition=2 --election-type preferred--partition:指定需要重新分配leader的partition编号
Kafka生产、消费数据工作流程
Kafka数据写入流程
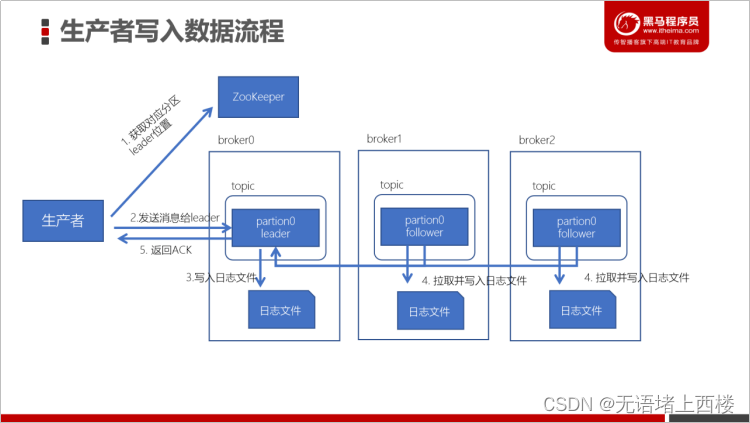
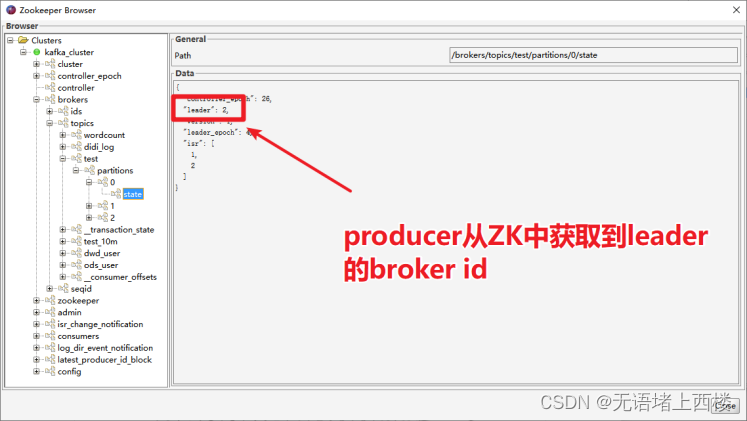
生产者先从 zookeeper 的 "/brokers/topics/主题名/partitions/分区名/state"节点找到该 partition 的leader
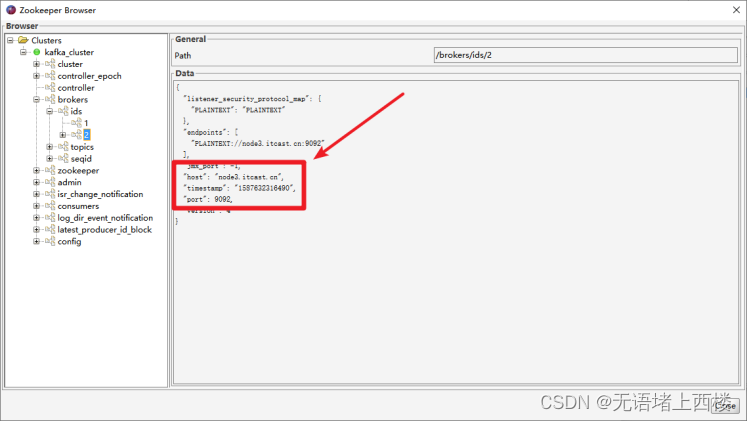
生产者在ZK中找到该ID找到对应的broker
- broker进程上的leader将消息写入到本地log中
- follower从leader上拉取消息,写入到本地log,并向leader发送ACK
- leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK。
Kafka数据消费流程
两种消费模式
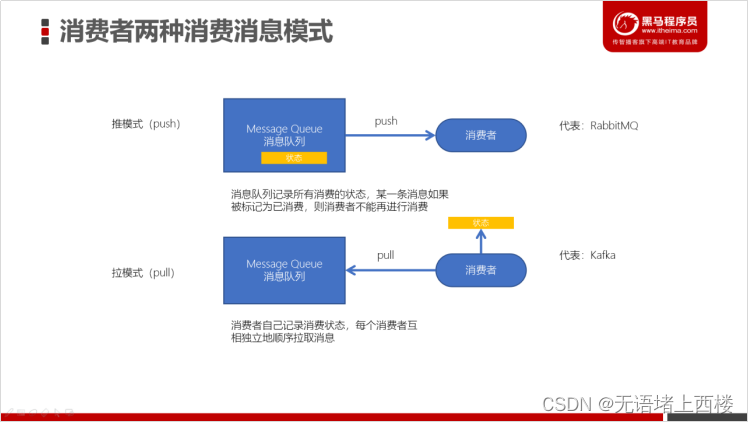
- kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息
- 消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
Kafka消费数据流程
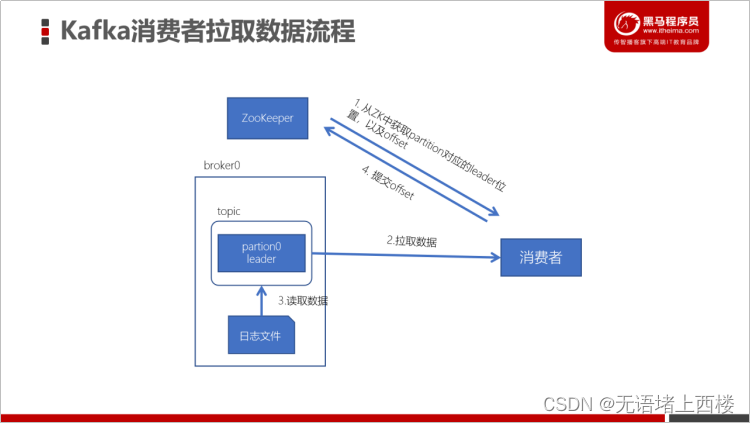
- 每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区
- 获取到consumer对应的offset(默认从ZK中获取上一次消费的offset)
- 找到该分区的leader,拉取数据
- 消费者提交offset
Kafka的数据存储形式

- 一个topic由多个分区组成
- 一个分区(partition)由多个segment(段)组成
- 一个segment(段)由多个文件组成(log、index、timeindex)
存储日志
接下来,我们来看一下Kafka中的数据到底是如何在磁盘中存储的。
- Kafka中的数据是保存在 /export/server/kafka_2.12-2.4.1/data中
- 消息是保存在以:「主题名-分区ID」的文件夹中的
- 数据文件夹中包含以下内容:
 这些分别对应:
这些分别对应:
|
文件名 |
说明 |
|
00000000000000000000.index |
索引文件,根据offset查找数据就是通过该索引文件来操作的 |
|
00000000000000000000.log |
日志数据文件 |
|
00000000000000000000.timeindex |
时间索引 |
|
leader-epoch-checkpoint |
持久化每个partition leader对应的LEO (log end offset、日志文件中下一条待写入消息的offset) |
- 每个日志文件的文件名为起始偏移量,因为每个分区的起始偏移量是0,所以,分区的日志文件都以0000000000000000000.log开始
- 默认的每个日志文件最大为「log.segment.bytes =1024*1024*1024」1G
- 为了简化根据offset查找消息,Kafka日志文件名设计为开始的偏移量
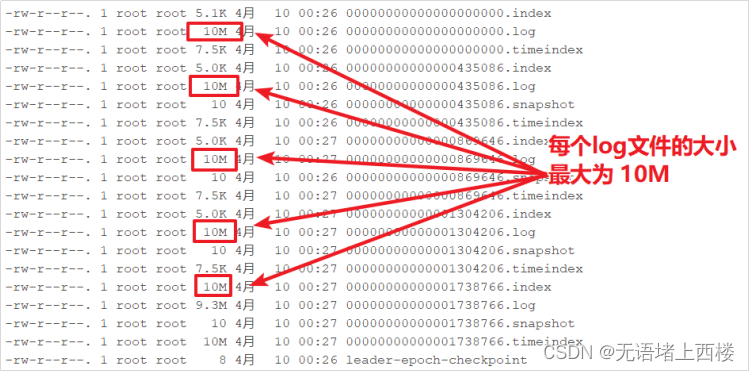
观察测试
为了方便测试观察,新创建一个topic:「test_10m」,该topic每个日志数据文件最大为10M
bin/kafka-topics.sh --create --zookeeper node1.itcast.cn --topic test_10m --replication-factor 2 --partitions 3 --config segment.bytes=10485760使用之前的生产者程序往「test_10m」主题中生产数据,可以观察到如下:
 写入消息
写入消息
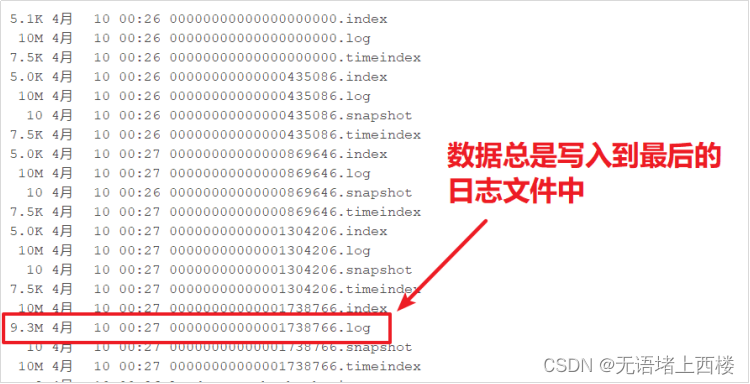
- 新的消息总是写入到最后的一个日志文件中
- 该文件如果到达指定的大小(默认为:1GB)时,将滚动到一个新的文件中
 读取消息
读取消息
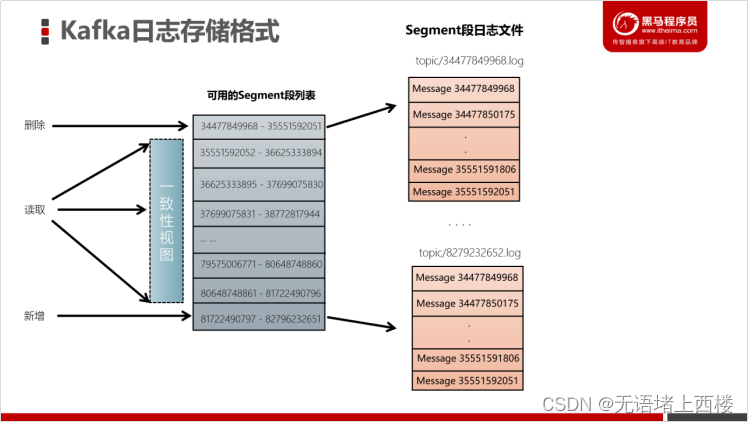
- 根据「offset」首先需要找到存储数据的 segment 段(注意:offset指定分区的全局偏移量)
- 然后根据这个「全局分区offset」找到相对于文件的「segment段offset」

- 最后再根据 「segment段offset」读取消息
- 为了提高查询效率,每个文件都会维护对应的范围内存,查找的时候就是使用简单的二分查找
删除消息
- 在Kafka中,消息是会被定期清理的。一次删除一个segment段的日志文件
- Kafka的日志管理器,会根据Kafka的配置,来决定哪些文件可以被删除

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)