【Kafka面试演练】那Kafka消费者手动提交、自动提交有什么区别?
嗯嗯Ok。分区的作用主要就是为了提高Kafka处理消息吞吐量。每一个topic会被分为多个分区。假如同一个topic下有n个分区、n个消费者,这样的话每个分区就会发送消息给对应的一个消费者,这样n个消费者负载均衡地处理消息。同时生产者会发送消息给不同分区,每个分区分给不同的brocker处理,让集群平坦压力,这样大大提高了Kafka的吞吐量。面试官思考中…

面试官:听说你精通Kafka,那我就考考你吧
面试官:不用慌尽管说,错了也没关系😊。。。
每日分享【大厂面试演练】,本期是《Kafka系列》,感兴趣就关注我吧❤️
面试官:你先说说Kafka由什么模块组成吧
嗯嗯好的。
主要有:生产者、消费者、Brocker、Topic、消息分区Partition。
面试官思考中…
面试官:那我们先讲讲生产者、消费者?
嗯嗯好的。
面试官思考中…
面试官:消息生产者的异步回调,知道吧
Ok知道的。主要是可以进行异常日志的记录。
是这样的,Kafka的异步提交消息相比同步提交,不需要在brocker响应前阻塞线程。
但是异步提交我们是不知道消费情况的,所以就可以在Kafka消费异常时,通过其回调来告知程序异常情况,从而进行日志记录。
面试官思考中…
面试官:消费者分区呢
嗯嗯。分区的作用主要就是为了提高Kafka处理消息吞吐量。
每一个topic会被分为多个分区。
假如同一个topic下有n个分区、n个消费者,每个分区会发送消息给对应的一个消费者,这样n个消费者就可以负载均衡地处理消息。
同时生产者会发送消息给不同分区,每个分区分给不同的brocker处理,让集群平坦压力,这样大大提高了Kafka的吞吐量。

面试官思考中…
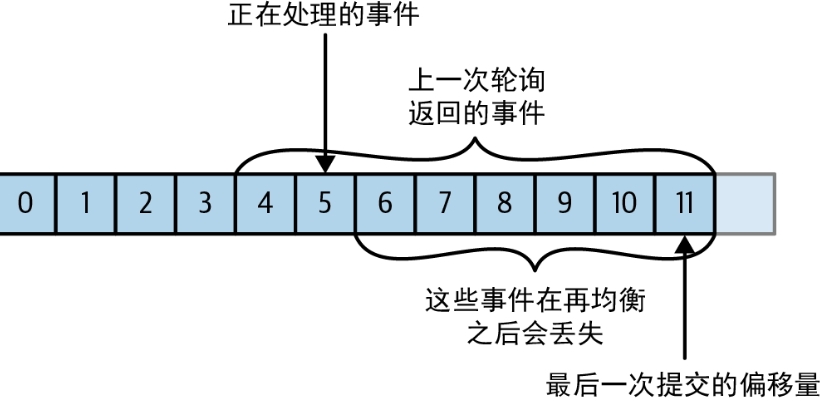
面试官:你说说消费者手动提交和自动提交,有什么区别
其实就是两种不同的客户端提交方式。
- 自动提交的话,通过设置enable.auto.commit为true,每过5秒消费者客户端就会自动提交最大偏移量
- 手动提交的话,通过设置enable.auto.commit为false,让消费者客户端消费程序执行后提交当前的偏移量
面试官思考中…
面试官:那它们都有什么优、缺点
- 自动提交的话,比较方便只需要配置就可以,不过可能会导致消息丢失或重复消费。
- 如果刚好到了5秒时提交了最大偏移量,此时正在消费中的消费者客户端崩溃了,就会导致消息丢失
- 如果成功消费了,下一秒应该自动提交,但此时消费者客户端奔溃了提交不了,就会导致其他分区的消费者重复消费
- 手动提交的话,需要写程序手动提交,要分两种提交方式。
- 手动提交是同步提交的话,在broker对请求做出回应之前,客户端会一直阻塞,这样的话限制应用程序的吞吐量
- 是异步提交的话,不会有吞吐量的问题。不过发送给broker偏移量之后,不会管broker有没有收到消息

面试官抓抓脑袋,继续看你的简历…
得想想考点你不懂的😰
未完待续。。。。。。
好了,今天的分享就先到这,我们下期【大厂面试演练】继续。
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)