Kafka消费者重平衡
kafka消费者重平衡
「(重平衡)Rebalance本质上是一种协议,规定了一个Consumer Group下的所有Consumer如何达成一致,来分配订阅Topic的每个分区」。
比如某个Group下有20个Consumer实例,它订阅了一个具有100个分区的Topic。
正常情况下,Kafka平均会为每个Consumer分配5个分区。这个分配的过程就叫Rebalance。
「Rebalance的触发条件有3个。」
- 组成员数发生变更。比如有新的Consumer实例加入组或者离开组,或是有Consumer实例崩溃被踢出组。
- 订阅主题数发生变更。Consumer Group可以使用正则表达式的方式订阅主题,比如
consumer.subscribe(Pattern.compile(“t.*c”))就表明该Group订阅所有以字母t开头、字母c结尾的主题,在Consumer Group的运行过程中,你新创建了一个满足这样条件的主题,那么该Group就会发生Rebalance。 - 订阅主题的分区数发生变更。Kafka当前只能允许增加一个主题的分区数,当分区数增加时,就会触发订阅该主题的所有Group开启Rebalance。
Rebalance发生时,Group下所有的Consumer实例都会协调在一起共同参与。
「分配策略」
当前Kafka默认提供了3种分配策略,每种策略都有一定的优势和劣势,社区会不断地完善这些策略,保证提供最公平的分配策略,即每个Consumer实例都能够得到较为平均的分区数。
比如一个Group内有10个Consumer实例,要消费100个分区,理想的分配策略自然是每个实例平均得到10个分区。
这就叫公平的分配策略。
举个简单的例子来说明一下Consumer Group发生Rebalance的过程。
假设目前某个Consumer Group下有两个Consumer,比如A和B,当第三个成员C加入时,Kafka会触发Rebalance,并根据默认的分配策略重新为A、B和C分配分区
Rebalance之后的分配依然是公平的,即每个Consumer实例都获得了2个分区的消费权。
在Rebalance过程中,所有Consumer实例都会停止消费,等待Rebalance完成,这是Rebalance为人诟病的一个方面。
目前Rebalance的设计是所有Consumer实例共同参与,全部重新分配所有分区。
「Coordinator会在什么情况下认为某个Consumer实例已挂从而要退组呢?」
当Consumer Group完成Rebalance之后,每个Consumer实例都会定期地向Coordinator发送心跳请求,表明它还存活着。
如果某个Consumer实例不能及时地发送这些心跳请求,Coordinator就会认为该Consumer已经死了,从而将其从Group中移除,然后开启新一轮Rebalance。
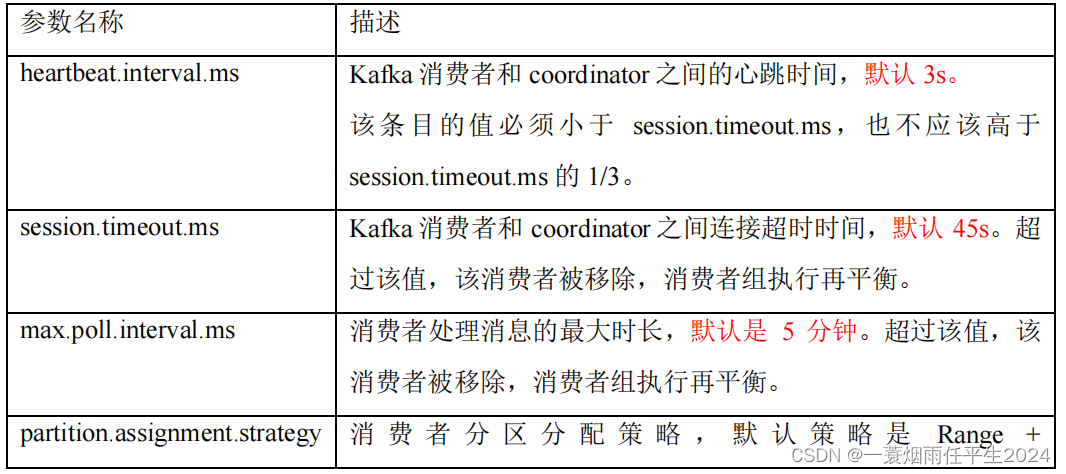
Consumer端有个参数,叫session.timeout.ms(默认10s)。
该参数的默认值是10秒,即如果Coordinator在10秒之内没有收到Group下某Consumer实例的心跳,它就会认为这个Consumer实例已经挂了。
除了这个参数,Consumer还提供了一个允许你控制发送心跳请求频率的参数,就是heartbeat.interval.ms(默认3s)。
这个值设置得越小,Consumer实例发送心跳请求的频率就越高。
频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启Rebalance,因为,目前Coordinator通知各个Consumer实例开启Rebalance的方法,就是将REBALANCE_NEEDED标志封装进心跳请求的响应体中。
除了以上两个参数,Consumer端还有一个参数,用于控制Consumer实际消费能力对Rebalance的影响,即max.poll.interval.ms(默认5min)参数。
它限定了Consumer端应用程序两次调用poll方法的最大时间间隔。
它的默认值是5分钟,表示你的Consumer程序如果在5分钟之内无法消费完poll方法返回的消息,那么Consumer会主动发起离开组的请求,Coordinator也会开启新一轮Rebalance。
「可避免Rebalance的配置」
第一类Rebalance是因为未能及时发送心跳,导致Consumer被踢出Group而引发的
- 设置
session.timeout.ms= 6s。 - 设置
heartbeat.interval.ms= 2s。 - 要保证Consumer实例在被判定为dead之前,能够发送至少3轮的心跳请求,即
session.timeout.ms >= 3 * heartbeat.interval.ms。
将session.timeout.ms设置成6s主要是为了让Coordinator能够更快地定位已经挂掉的Consumer。
「第二类Rebalance是Consumer消费时间过长导致的」。
你要为你的业务处理逻辑留下充足的时间,这样Consumer就不会因为处理这些消息的时间太长而引发Rebalance了。

参考案例:
一次 kafka 消息堆积问题排查如题 https://mp.weixin.qq.com/s/VgXukc39tFBXrR0yKg7vdA
https://mp.weixin.qq.com/s/VgXukc39tFBXrR0yKg7vdA
max.poll.interval.ms 表示消费者处理消息逻辑的最大时间,对于某些业务来说,处理消息可能需要很长时间,比如需要 1 分钟,那么该参数就需要设置成大于 1分钟的值,否则就会被 Coordinator 剔除消息组然后重平衡, 默认值为 300000ms(即:5min);
max.poll.records 表示每次默认拉取消息条数,默认值为 500。
我们来计算一下:
200 * 500 = 100000 < max.poll.interval.ms =300000,
前面我也讲了,当每条消息处理时间大概率会超过 200ms。
结论:
本次出现的问题是由于客户端的消息消费逻辑耗时太长,如果生产端出现消息发送增多,消费端每次都拉取了 500 条消息进行消费,这时就很容易导致消费时间过长,如果超过了 max.poll.interval.ms 所设置的时间,就会被消费组所在的 coordinator 剔除掉,从而导致重平衡,Kafka 重平衡过程中是不能消费的,会导致消费组处于类似 stop the world 的状态下,重平衡过程中也不能提交位移,这会导致消息重复消费从而使得消费组的消费速度下降,导致消息堆积。
解决办法:
根据业务逻辑调整 max.poll.records 与 max.poll.interval.ms 之间的平衡点,避免出现消费者被频繁踢出消费组导致重平衡。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)