大数据导论(3)---大数据技术
大数据技术主要包括数据采集与预处理、数据存储、数据处理与分析、数据可视化、数据安全和隐私保护等几个层面的内容。技术层面功能数据采集与预处理利用ETL工具将分布的、异构数据源中的数据,如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;利用日志采集工具(如 Flume、Kafka 等)把实时采集的数据作为流计算系统的输
文章目录
1. 大数据技术概述
大数据技术主要包括数据采集与预处理、数据存储、数据处理与分析、数据可视化、数据安全和隐私保护等几个层面的内容。
| 技术层面 | 功能 |
|---|---|
| 数据采集与预处理 | 利用ETL工具将分布的、异构数据源中的数据,如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;利用日志采集工具(如 Flume、Kafka 等)把实时采集的数据作为流计算系统的输入,进行实时处理分析;利用网页爬虫程序到互联网网站中爬取数据 |
| 数据存储和管理 | 利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等,实现对结构化、半结构化和非结构化海量数据的存储和管理 |
| 数据处理与分析 | 利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理与分析 |
| 数据可视化 | 对并行结果进行可视化呈现,帮助人们更好地理解数据、分析数据 |
| 数据安全和隐私保护 | 在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全 |
2. 数据采集与预处理
2.1 数据采集
1. 数据采集,又称 “数据获取”,是数据分析的入口,也是数据分析过程中相当重要的一个环节,它通过各种技术手段把外部各种数据源产生的数据实时或非实时地采集并加以利用。
2. 数据采集的3大特点:① 全面性。 ② 多维性。 ③ 高效性。
3. 数据采集的主要数据源包括传感器数据、互联网数据、日志文件、企业业务系统数据。
4. 传统的数据采集与大数据采集区别:
| 传统的数据采集 | 大数据采集 | |
|---|---|---|
| 数据源 | 来源单一、数据量相对较少 | 来源广泛、数据量巨大 |
| 数据类型 | 结构单一 | 数据类型丰富,包括结构化、半结构化、非结构化 |
| 数据存储 | 关系数据库和并行数据库 | 分布式数据库、分布式文件系统 |
2.2 预处理
1. 数据清洗(预处理)是将大量原始数据中的 “脏” 数据 “洗掉”,它是发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
2. 需要清洗的数据的主要类型:① 残缺数据。 ② 错误数据。 ③ 重复数据。
3.数据清洗主要包括以下内容:
- 一致性检查。
- 无效值和缺失值的处理。常用方法有:估算、整例删除、变量删除、成对删除。
3. 数据存储和管理
存储与管理贯穿大数据处理过程的始终,数据非结构化的特征明显,需要依靠分布式文件系统、分布式数据库、NoSQL 数据库、云数据库等技术来实现。
- 分布式基础架构Hadoop
- 分布式文件系统HDFS
- 分布式数据库HBase
- 非关系型数据库NoSQL
3.1 分布式基础架构Hadoop
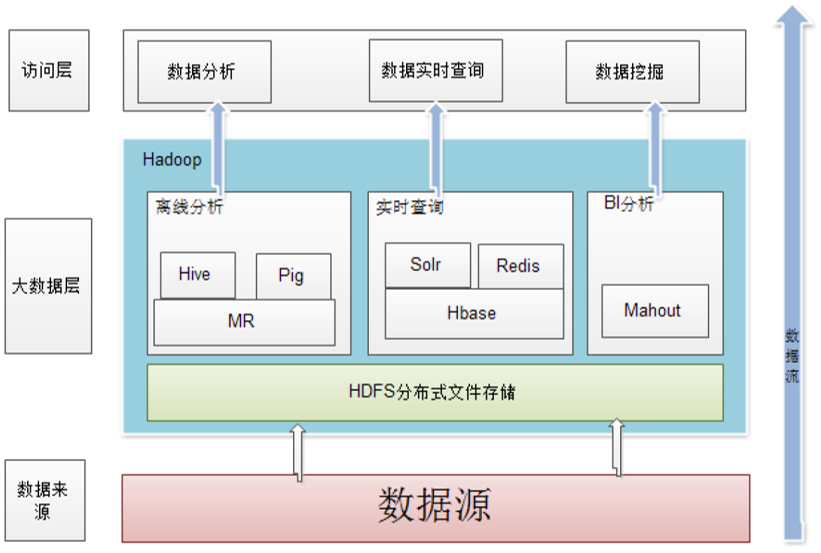
1. Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。

2. Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop在企业中的应用架构如下图所示。

3.2 分布式文件系统HDFS
1. 分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
2. 分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫 “主节点”(Master Node)或者也被称为 “名称结点”(NameNode),另一类叫 “从节点”(Slave Node)或者也被称为 “数据节点”(DataNode)。
- 在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间,名称节点记录了每个文件中各个块所在的数据节点的位置信息。
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据
客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期
发送自己所存储的块的列表。

3. HDFS默认一个块128MB,一个文件被分成多个块,以块作为存储单位(块存储)块的大小远远大于普通文件系统,可以最小化寻址开销。
3.3 分布式数据库HBase
1. HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。

2. 最基本的存储单位是列(Column),一个或者多个列构成一行(row)。若干个列组成一个列族(Column family)。传统关系数据库中行的结构是相同的。在HBase中两行的结构可以不同,甚至可以完全不同。

3.4 非关系型数据库NoSQL
1. 通常,NoSQL数据库具有以下几个特点:(1)灵活的可扩展性。(2)灵活的数据模型。(3)与云计算紧密融合。

2. NoSQL与关系数据库的比较总结:
(1) 关系数据库
优势:以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持。
劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等。
(2) NoSQL数据库
优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等。
劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等。
3. NoSQL数据库虽然数量众多,但是归结起来,典型的NoSQL数据库通常包括键值数据库、列族数据库、文档数据库和图形数据库。

4. 数据可视化与保护
1. 数据可视化的作用:让 “茫茫数据” 以可视化的方式呈现,让枯燥的数据以简单友好的图表形式展现出来,可以让数据变得更加通俗易懂,有助于用户更加方便快捷地理解数据的深层含义,有效参与复杂的数据分析过程,提升数据分析效率,改善数据分析效果。
2. 数据安全技术:(1) 身份认证技术。 (2) 防火墙技术。 (3) 访问控制技术。 (4) 人脸检测技术。 (5) 加密技术。
参考资源:林子雨编著的《大数据导论》

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)