一个基于Kafka客户端封装的工具,Kafka开发效率神器
topic列表topic创建topic删除topic的分区列表,分区和副本数删除groupId集群的节点列表消费者列表指定topic的活跃消费者列表生产数据到指定的topic,同步接口{"topic":"RULEa93304e6d844000","partition":1,"offset":681}生产数据到指定的topic,异步接口,默认回调生产数据到指定的topic,异步接口,自定义回调。
GitHub源码https://github.com/zhangchuangiie/SimpleKafka
SimpleKafka(Kafka客户端封装工具类)
一个基于Kafka客户端封装的工具,Kafka开发效率神器
特点:
- 封装了常用的Kafka客户端操作,无需维护配置,无需初始化客户端,真正实现了一行代码调用
- 将连接池的维护封装在工具类里面,多线程使用也无需维护客户端集合
使用方式:
只需要集成1个KafkaUtil.java文件即可,修改里面的kafka服务地址即可
典型示例:
- 同步生产: LinkedHashMap<String, Object> recordMeta = KafkaUtil.sendToKafka("RULEa93304e6d844000","222","aaaa");
- 异步生产: KafkaUtil.sendToKafkaAsync("RULEa93304e6d844000", "222", "aaaa");
- 消费数据: ArrayList<LinkedHashMap<String, Object>> buffer = KafkaUtil.recvFromKafka("RULEa93304e6d844000", "group1");
- 重置偏移: KafkaUtil.resetOffsetToEarliest("RULEa93304e6d844000", "group1");
接口介绍:
- kafkaListTopics: topic列表
- createTopic: topic创建
- delTopic: topic删除
- partitionsTopic: topic的分区列表,分区和副本数
- delGroupId: 删除groupId
- descCluster: 集群的节点列表
- kafkaConsumerGroups: 消费者列表
- kafkaConsumerGroups: 指定topic的活跃消费者列表
- sendToKafka: 生产数据到指定的topic,同步接口{"topic":"RULEa93304e6d844000","partition":1,"offset":681}
- sendToKafkaAsync: 生产数据到指定的topic,异步接口,默认回调
- sendToKafkaAsync: 生产数据到指定的topic,异步接口,自定义回调
- recvFromKafka: 按groupId消费指定topic的数据[{"topic":"RULEa93304e6d844000","key":"222","value":"aaaa","partition":1,"offset":681}]
- recvFromKafkaByOffset: 消费指定topic指定partition对应的offset数据
- recvFromKafkaByTimestamp: 消费指定topic指定partition对应的timestamp以后的数据
- resetOffsetToTimestamp: 重置指定topic的offset到对应的timestamp
- resetOffsetToEarliest: 重置指定topic的offset到最早
- resetOffsetToLatest: 重置指定topic的offset到最晚,一般在跳过测试脏数据时候使用
- consumerPositions: 获取当前消费偏移量情况{"partitionNum":2,"dataNum":1,"lagNum":0,"positions":[{"partition":0,"begin":0,"end":0,"current":0,"current1":0,"size":0,"lag":0},{"partition":1,"begin":681,"end":682,"current":682,"current1":682,"size":1,"lag":0}]}
- topicSize: 获取指定topic数据量详情情况 [{"partition": 0,"begin": 65,"end": 65,"size": 0}]
- topicSizeAll: 获取所有topic数据量详情情况
- topicSizeStatistics: 获取指定topic数据量统计{"partitionNum":5452,"dataNum":41570647}
- topicSizeStatisticsAll: 获取所有topic数据量统计{"topicNum":2550,"partitionNum":5452,"dataNum":41570647}
接口列表:
- kafkaListTopics: List kafkaListTopics()
- createTopic: void createTopic(String topic)
- delTopic: void delTopic(String topic)
- partitionsTopic: List partitionsTopic(String topic)
- delGroupId: void delGroupId(String groupId)
- descCluster: List descCluster()
- kafkaConsumerGroups: List kafkaConsumerGroups()
- kafkaConsumerGroups: List kafkaConsumerGroups(String topic)
- sendToKafka: LinkedHashMap<String, Object> sendToKafka(String topic, String key, String value)
- sendToKafkaAsync: void sendToKafkaAsync(String topic, String key, String value)
- sendToKafkaAsync: void sendToKafkaAsync(String topic, String key, String value,Callback callback)
- recvFromKafka: ArrayList<LinkedHashMap<String, Object>> recvFromKafka(String topic, String groupId)
- recvFromKafkaByOffset: ArrayList<LinkedHashMap<String, Object>> recvFromKafkaByOffset(String topic, String groupId,int partition,long offset)
- recvFromKafkaByTimestamp: ArrayList<LinkedHashMap<String, Object>> recvFromKafkaByTimestamp(String topic, String groupId,int partition,long timestamp)
- resetOffsetToTimestamp: boolean resetOffsetToTimestamp(String topic, String groupId, long timestamp)
- resetOffsetToEarliest: boolean resetOffsetToEarliest(String topic, String groupId)
- resetOffsetToLatest: boolean resetOffsetToLatest(String topic, String groupId)
- consumerPositions: List<LinkedHashMap<String, Object>> consumerPositions(String topic, String groupId)
- topicSize: List<LinkedHashMap<String, Object>> topicSize(String topic)
- topicSizeAll: LinkedHashMap<String, Object> topicSizeAll()
- topicSizeStatistics: LinkedHashMap<String, Object> topicSizeStatistics(String topic)
- topicSizeStatisticsAll: LinkedHashMap<String, Object> topicSizeStatisticsALL()
示范应用:
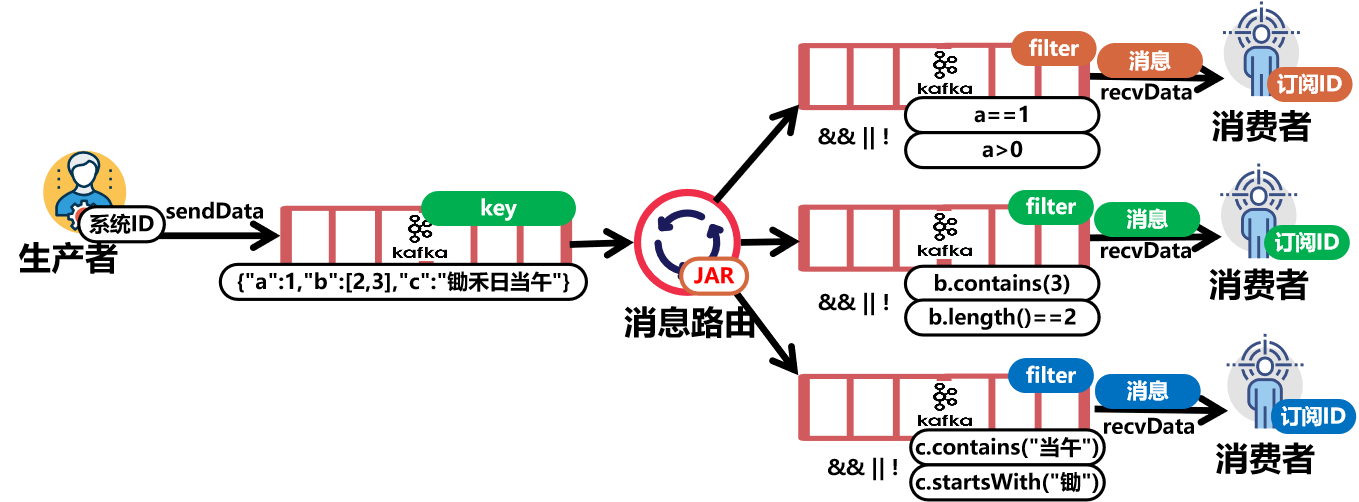
为了说明该工具的效用,基于该工具实现了一个HTTP接口的消息队列服务,该服务只用了几十行代码,就实现了基于标签内容的发布订阅服务,服务见APIKafka.java,客户端示例见ClientKafka.java。
该服务支持生产者任意标注标签,支持消费者按表达式条件订阅数据,表达式支持与或非,支持集合查找,以及字符串子串匹配。
同时也支持消息回溯消费已经消息统计查询。
实现了流式消息检索的基本需求。

APIKafka,支持生产者任意标注标签,标签是开放的,可以是任意JSON,Key无需预先定义和Value也不必是枚举值,支持消费者按表达式条件订阅数据,支持开源表达式语言OGNL,包括支持与或非,支持对象取值,支持数组和集合的访问,也支持Java表达式,常用的有contains,startsWith,endsWith,length等,也支持matches正则匹配。可以满足流式消息检索的各种匹配要求。
联系人:
有问题可以联系:zhangchuang@iie.ac.cn

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)