二百零七、Flume——Flume实时采集5分钟频率的Kafka数据直接写入ODS层表的HDFS文件路径下
Flume实时采集5分钟频率的Kafka数据直接写入ODS层表的HDFS文件路径下
一、目的
在离线数仓中,需要用Flume去采集Kafka中的数据,然后写入HDFS中。
由于每种数据类型的频率、数据大小、数据规模不同,因此每种数据的采集需要不同的Flume配置文件。玩了几天Flume,感觉Flume的使用难点就是配置文件
二、使用场景
转向比数据是数据频率为5分钟的数据类型代表,数据量很小、频率不高,因此搞定了转向比数据的采集就搞定了这一类低频率数据的实时采集问题
1台设备每日的转向比数据规模是30KB,25台设备的数据规模则是750KB
三、转向比数据ODS层建表
create external table if not exists ods_turnratio(
turnratio_json string
)
comment '转向比数据外部表——静态分区'
partitioned by (day string)
stored as SequenceFile
;
注意:不需要剪裁,不需要row format和lines terminated,否则可能会出问题
--row format delimited fields terminated by '\x001'
--lines terminated by '\n'
--tblproperties("skip.header.line.count"="1") ; 不需要裁掉第一行
四、转向比数据的配置文件
## agent a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
## configure source s1
a1.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.s1.kafka.bootstrap.servers = 192.168.0.27:9092
a1.sources.s1.kafka.topics = topic_b_turnratio
a1.sources.s1.kafka.consumer.group.id = turnratio_group
a1.sources.s1.kafka.consumer.auto.offset.reset = latest
a1.sources.s1.batchSize = 1000
## configure channel c1
## a1.channels.c1.type = memory
## a1.channels.c1.capacity = 10000
## a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/data/flumeData/checkpoint/turnratio
a1.channels.c1.dataDirs = /home/data/flumeData/flumedata/turnratio
## configure sink k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hurys23:8020/user/hive/warehouse/hurys_dc_ods.db/ods_turnratio/day=%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = turnratio
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.rollSize = 1200000000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 600
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = SequenceFile
a1.sinks.k1.hdfs.codeC = gzip
## Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
注意:1200000000约为1150MB,Gzip压缩后一个HDFS文件大小为120MB左右
五、Flume写入HDFS结果
Flume根据时间戳按照ODS层表的分区,将数据写入对应HDFS文件
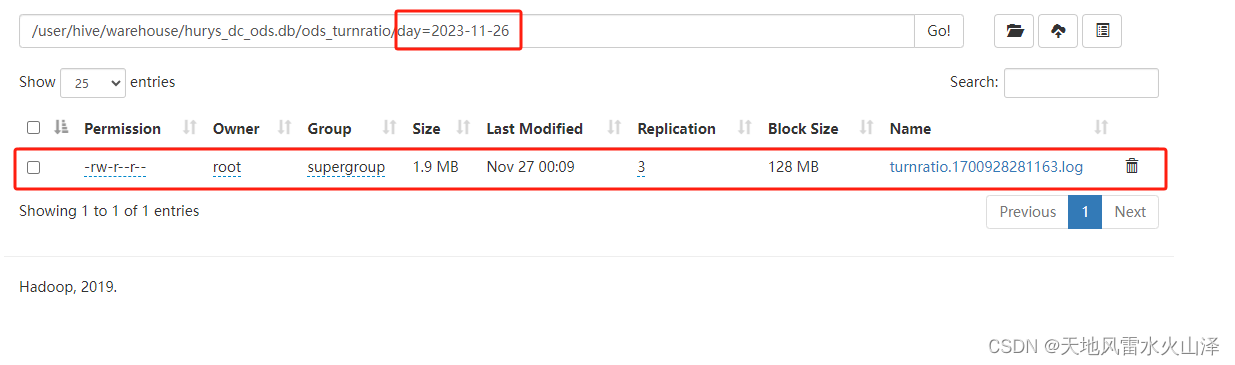
25台设备,1天1个文件,文件大小1.9 MB
六、ODS表刷新分区后查验数据
(一)刷新表分区
MSCK REPAIR TABLE ods_turnratio;
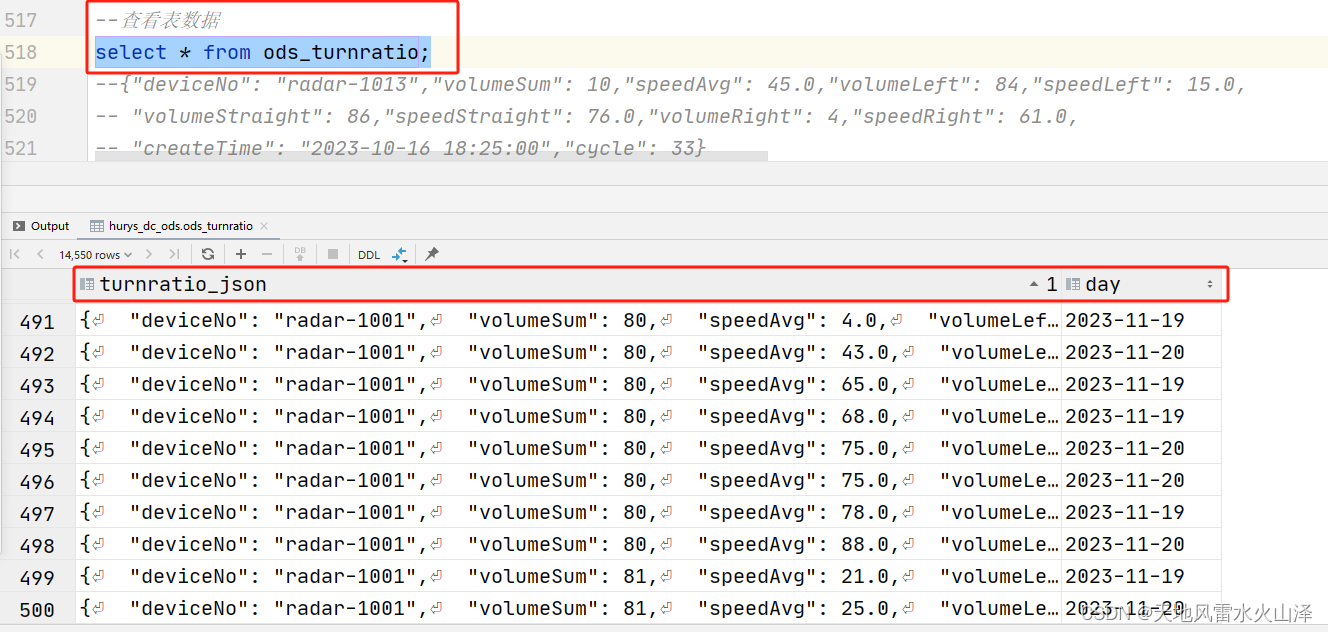
(二)查看表数据
select * from ods_turnratio;
(三)验证数据完整性
--2023-11-26 数据完整 22时、23时都是300条 标准300
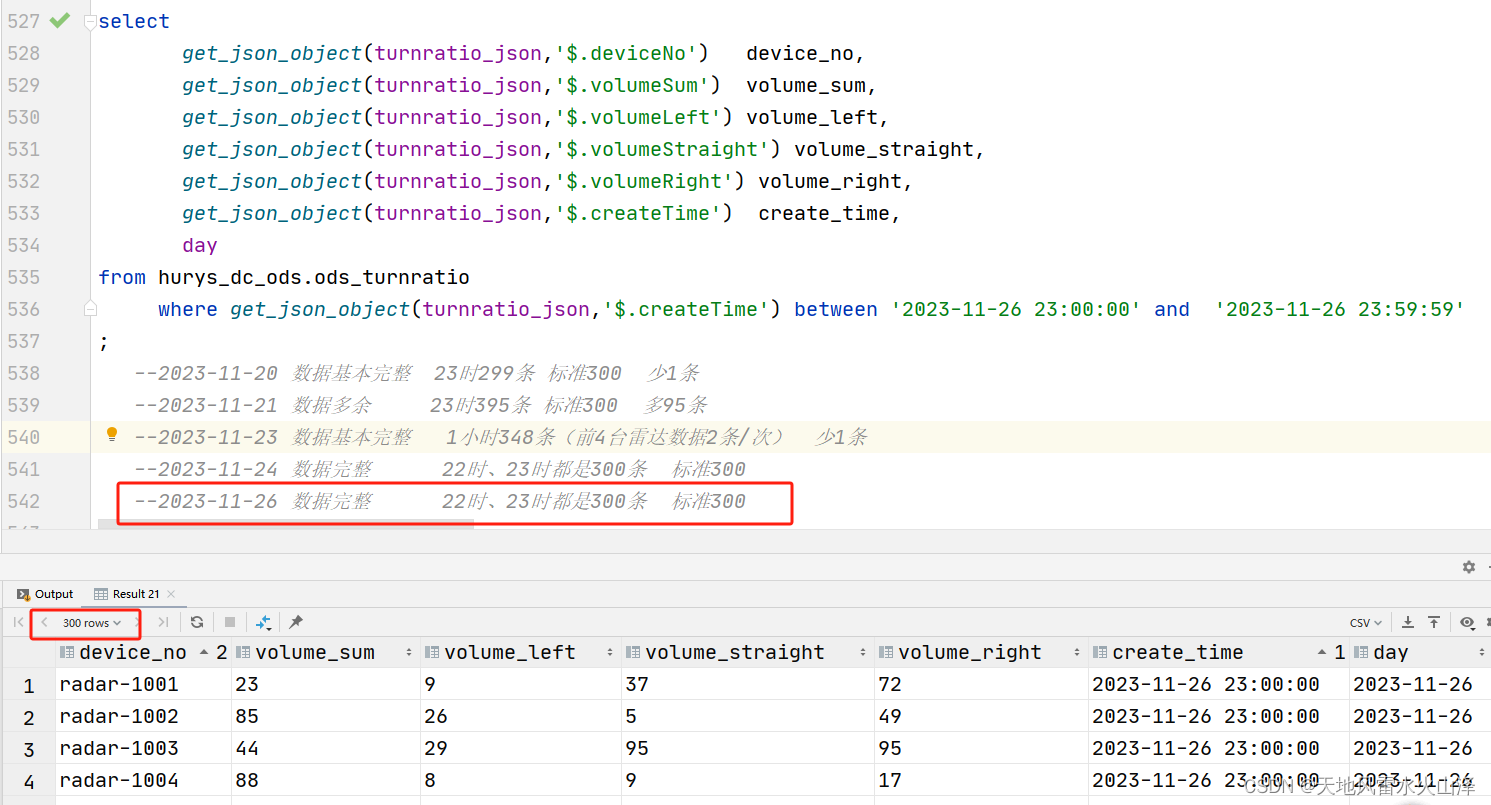
数据完整、及时,只要配置文件大小参数设的大一些,基本就没问题。之前参数设置的小就出现数据丢失的问题!
七、注意点
(一)配置文件中的重点是红色标记的几点
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.rollSize = 1200000000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 600
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = SequenceFile
a1.sinks.k1.hdfs.codeC = gzip
(二)任务配置文件中rollSize参数设置可大不可小
rollSize参数小的话数据会丢失,大的话没问题。对于数据量少的数据,尽量一天一个文件,否则浪费NameNode宝贵资源!
配置文件的参数还是不断调试中,争取调到最优的状态。能够及时、完整的消费Kafka数据,并且能够最大化的利用HDFS资源。
目前就先这样,如果有问题的话后面再更新!!!
2023-12-4完善一次,Flume文件配置添加gzip文件压缩、调整文件大小参数,Gzip压缩率大概是10%
a1.sinks.k1.hdfs.fileType = SequenceFile
a1.sinks.k1.hdfs.codeC = gzip
同是文件大小参数为130000000,压缩前一个HDFS文件是126.24 MB,压缩后一个HDFS文件是12.72 MB,所以压缩率为10%。
为了节省服务器资源,Flume配置文件里添加压缩,还是很有必要的!

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)