消息系统kafka及其变种Jafka、Metamorphosis (MetaQ)
1、Kafka : 基于scalakafka是一个发布订阅的消息系统,关注于海量数据、性能和吞吐量,不关注可靠性和事务。-------------------- 以下内容来自oschina的介绍kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。高吞吐量
1、Kafka : 基于scala
kafka是一个发布订阅的消息系统,关注于海量数据、性能和吞吐量,不关注可靠性和事务。
-------------------- 以下内容来自oschina的介绍
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
卡夫卡的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
2.Jafka : Kafka的java一直版本
Jafka 是一个高性能的跨语言分布式消息系统。Jafka已经开源,使用github托管。
Jafka是由Apache孵化的Kafka(由LinkedIn捐助给Apache)克隆而来。Jafka 1.0完整遵循Kafka 0.7的规范,几乎是Kafka的克隆版(有一些改进和调整)。
Jafka有几个吸引人的特性:
- 消息持久化非常快,服务端存储消息的开销为O(1),并且基于文件系统,能够持久化TB级的消息而不损失性能
- 吞吐量很大,在我的笔记本DELL E6220、Fedora 16 x86_64下单CPU内核运行,使用Jafka内置的python客户端,吞吐量能够达到300k/s
- 完全的分布式系统,broker、producer、consumer都原生自动支持分布式。自动实现复杂均衡。
- 内核非常小,整个系统(包括服务端和客户端)只有一个272KB的jar包,内部机制也不复杂,适合进行内嵌或者二次开发 。整个服务端加上依赖组件共3.5MB。
- 消息格式以及通信机制非常简单,适合进行跨语言开发。目前自带的Python 3.x的客户端支持发送消息和接收消息。
3.Metamorphosis (MetaQ) : Kafka的java移植和改进版本
Metamorphosis (MetaQ) 是一个高性能、高可用、可扩展的分布式消息中间件,类似于LinkedIn的Kafka,具有消息存储顺序写、吞吐量大和支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景,在淘宝和支付宝有着广泛的应用,现已开源。
总体结构:
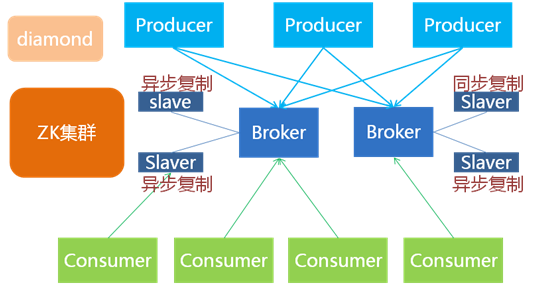
内部结构:

主要特点:
- 生产者、服务器和消费者都可分布
- 消息存储顺序写
- 性能极高,吞吐量大
- 支持消息顺序
- 支持本地和XA事务
- 客户端pull,随机读,利用sendfile系统调用,zero-copy ,批量拉数据
- 支持消费端事务
- 支持消息广播模式
- 支持异步发送消息
- 支持http协议
- 支持消息重试和recover
- 数据迁移、扩容对用户透明
- 消费状态保存在客户端
- 支持同步和异步复制两种HA
- 支持group commit
- 更多……

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)