Kafka系统介绍及高性能原理
一、Kafka介绍二、消息队列的分类至多一次,常见的rabbitmq,rocketmq都是这种方式,通过ACK机制确认消息已被消费者消费,此时会将消息删除;没有限制则主要是通过消费者上传的offset(偏移量)来确认消费消息的初始位置,同一消息可以被反复多次消费,一直到达到指定条件,比如kafka是默认保留7天,7天后则会被删除。三、kafka基础架构Kafka集群以Topic形式负责分类集群中的
一、Kafka介绍

kafka有两个版本号,前面是scale的版本号,后面是kafka的版本号,scale语言依赖jvm,最终也是编译成class文件,
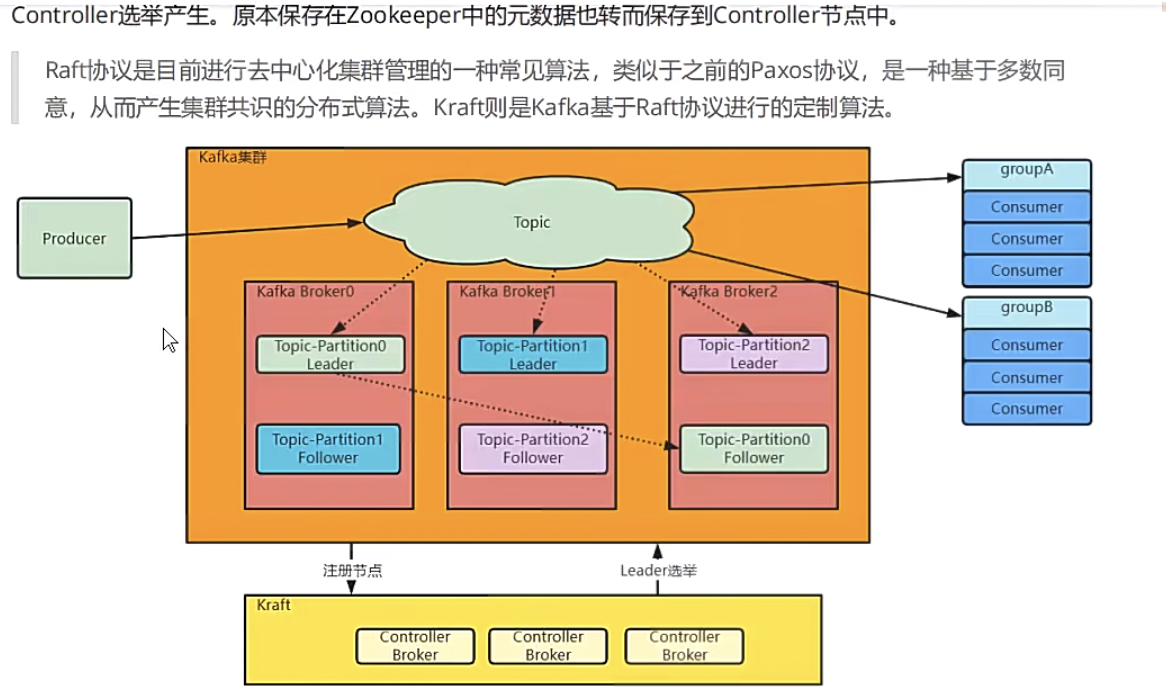
kafka4.0之前的版本内置了zookpeer,但是生产环境一般不会用,会替换成自己neizhi,4.0之后抛弃zookpeer,自己内部基于raft协议实现了一套。
二、消息队列的分类

至多一次,常见的rabbitmq,rocketmq都是这种方式,通过ACK机制确认消息已被消费者消费,此时会将消息删除;没有限制则主要是通过消费者上传的offset(偏移量)来确认消费消息的初始位置,同一消息可以被反复多次消费,一直到达到指定条件,比如kafka是默认保留7天,7天后则会被删除。
三、kafka基础架构
每个partition在磁盘上,其实是一个文件,理论上partition没有数量的上限,但是不建议数量过多。因为partition过多,意味着磁盘上对应的文件也越多,反而影响性能。
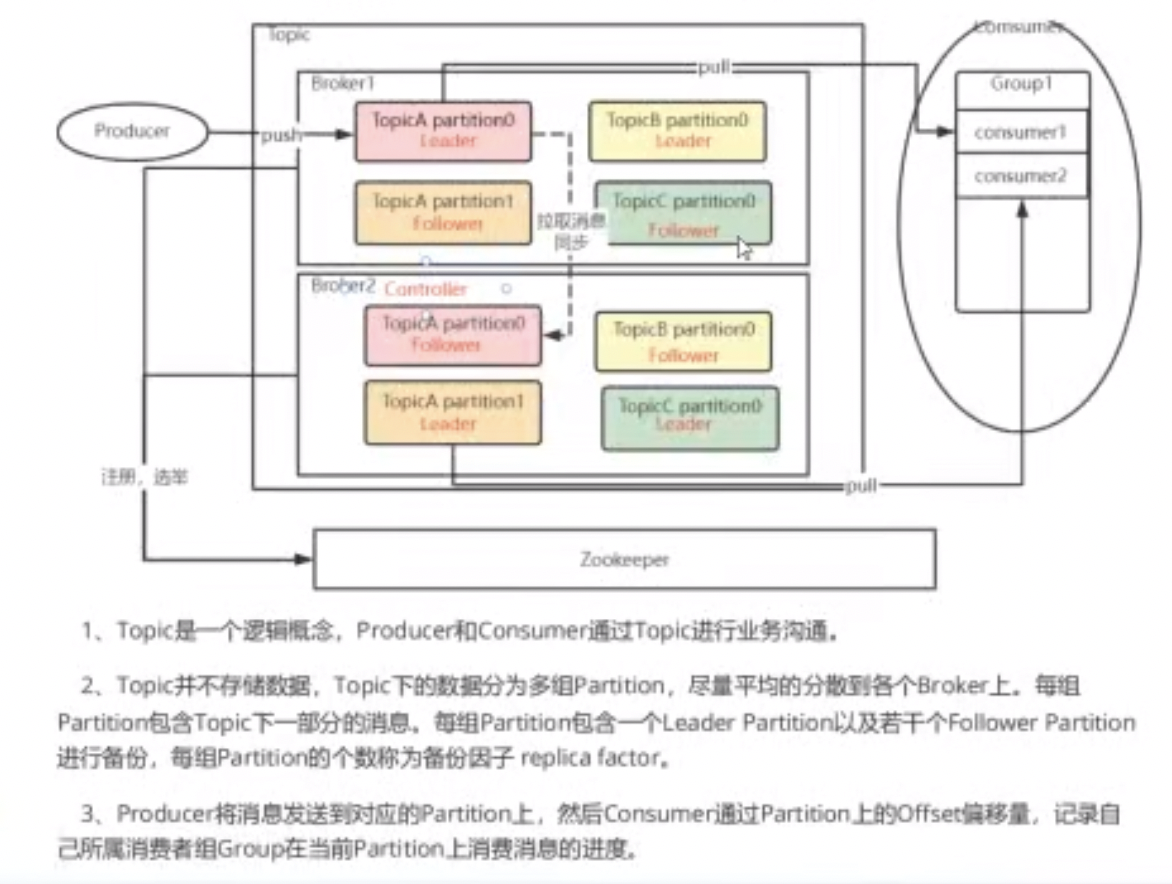
Kafka集群以Topic形式负责分类集群中的Record,每一个Record属于一个Topic,每个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志分区都一定会有一个Broker担当该分区的Leader,其他的Broker担当该分区的follower。Leader负责分区数据的读写操作,follower负责同步该分区的数据。这样如果分区的Leader宕机,该分区的其他follower会选取新的Leader继续负责该分区数据的读写,其中集群中的Leader的监控和Topic的部分元数据是存储在Zookeeper中。

分区越大,理论上可以处理的并发读写也越大。
四、kafka消费者和消费者组

消费者组

注意:消费者组内消费者的数量大于topic中分区的数量,多出的消费者正常情况下无法消费消息,但是当其他消费者无法正常工作时,它可以充当备份,顶上去。
每个消费组会记录一个独立的消费进度offset,在服务端通过命令可以查看。
五、kafka高性能之道
1.顺序IO和MMap

2.Zero copy
常规的IO

DMA协处理器

Zero copy

由图可知:所谓0拷贝,主要是省去了,从内核缓冲区copy到用户缓冲区和用户缓冲区copy到内核与socket相关的缓冲区这两步,而是直接从内核缓冲区copy到内核与socket相关的缓冲区。总结如下:
kraft版本的架构
自定义序列化类

需要被序列化的对象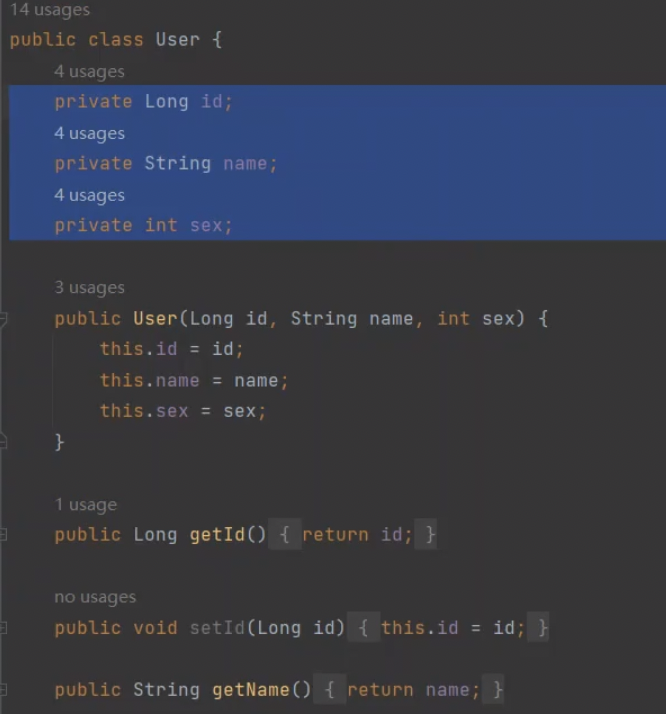
序列化实现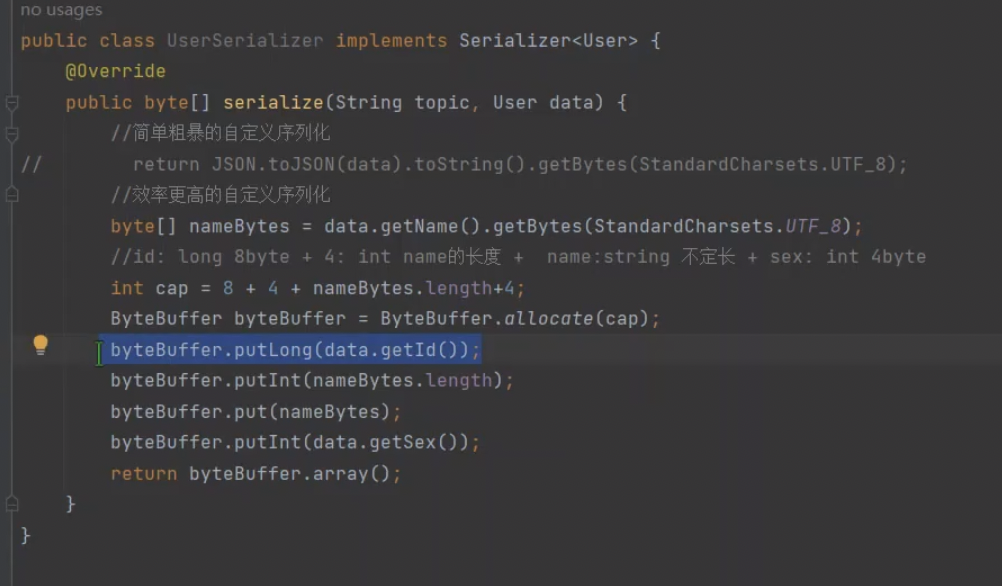
反序列化实现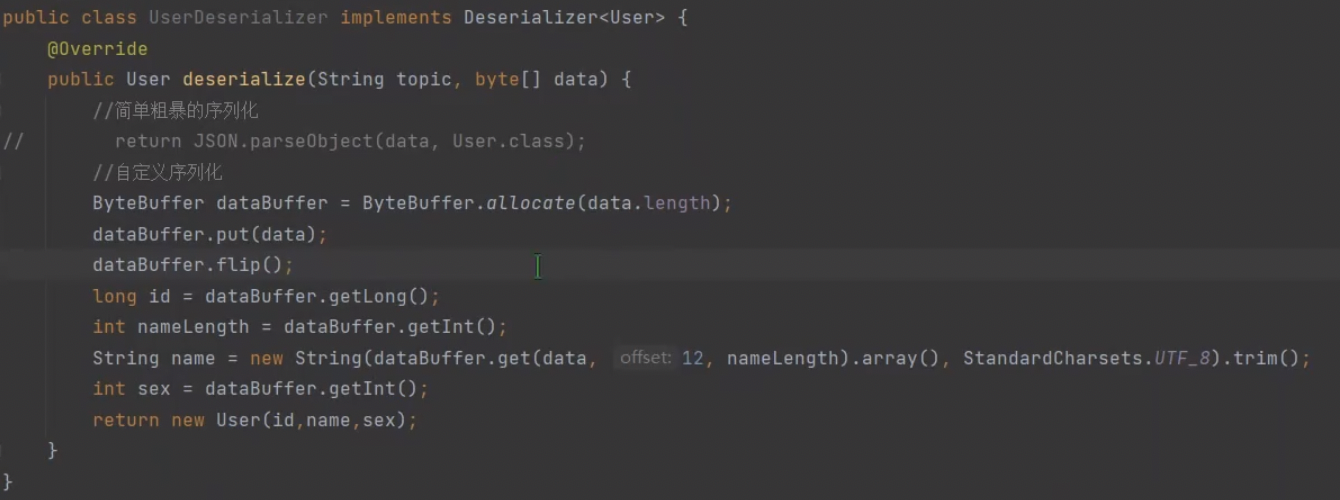
其他序列化的方法:
生产者消息缓存机制

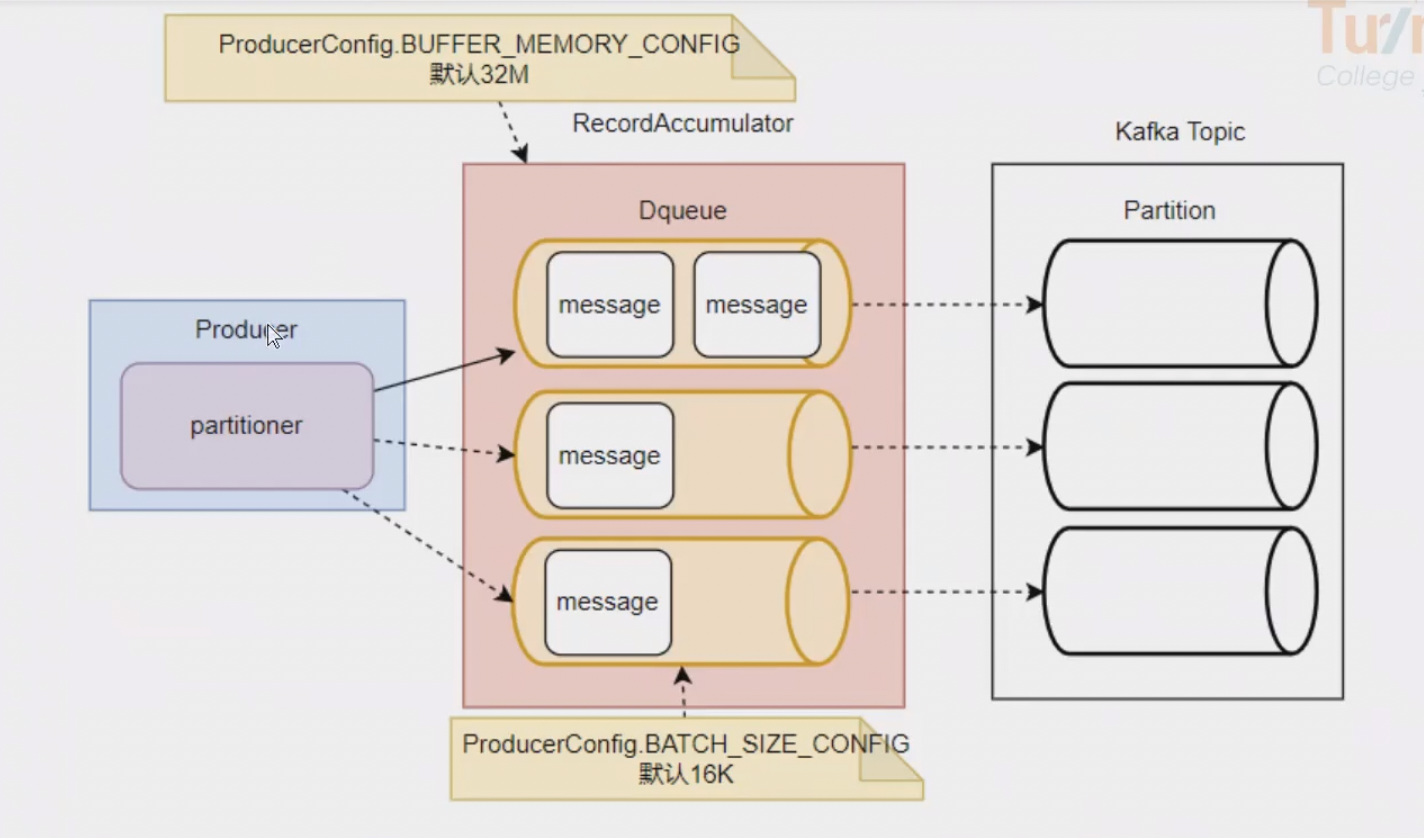
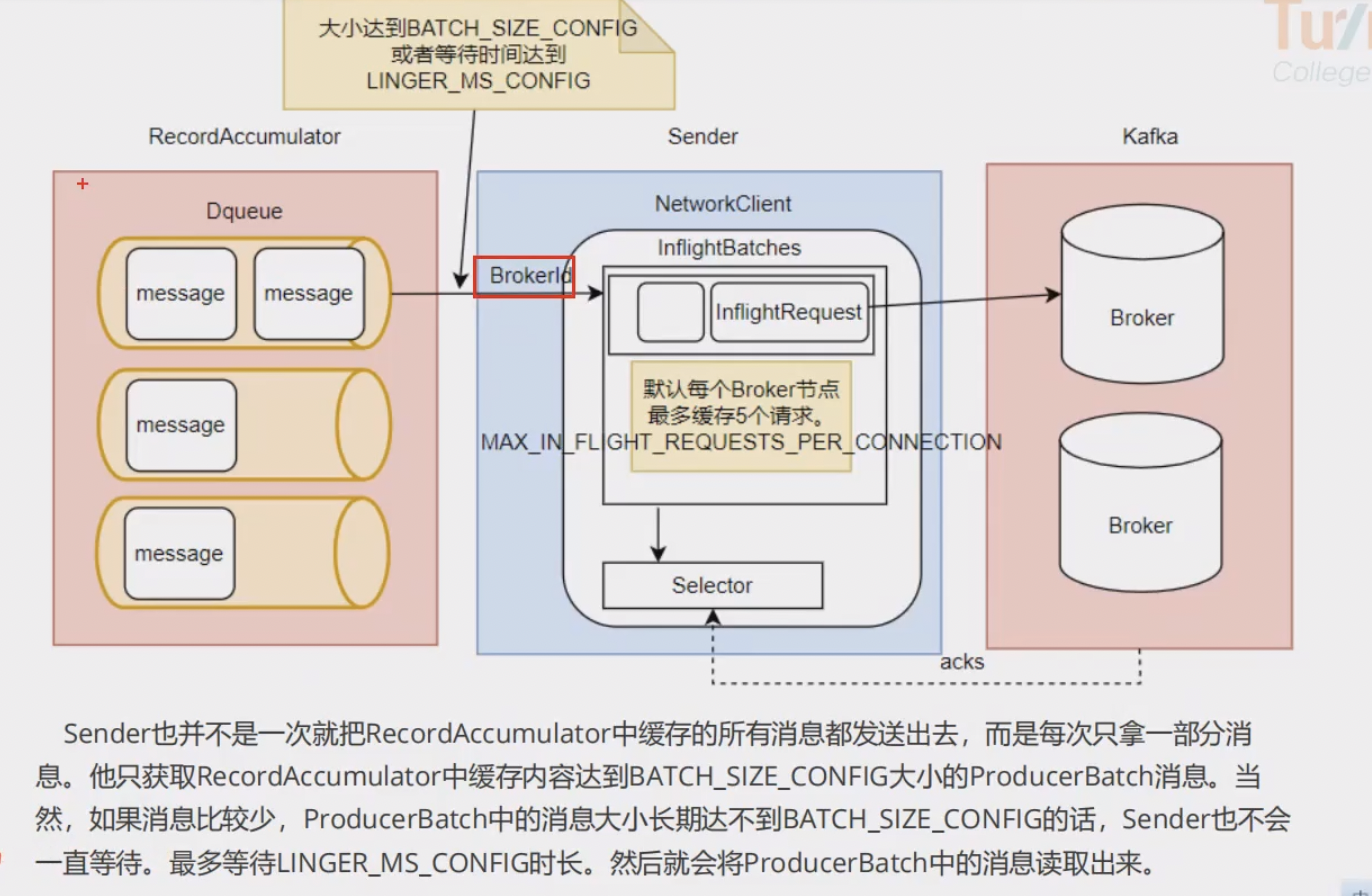
发送应答机制
1. acks=0
含义:生产者发送消息后,不等待任何 broker 的确认,直接认为消息发送成功。
特点:
速度最快(无网络等待开销),但可靠性最低。
消息可能因 broker 崩溃、网络故障等丢失,且生产者无法感知。
适用场景:对可靠性要求极低,追求极致吞吐量的场景(如日志采集的非核心数据)。
2. acks=1(默认值)
含义:生产者发送消息后,只需等待分区的 leader 副本确认接收并写入本地日志,就认为消息发送成功,无需等待 follower 副本同步。
特点:
平衡了速度和可靠性。
若 leader 副本在消息同步到 follower 前崩溃,消息可能丢失(此时 follower 未同步,新 leader 无该消息)。
适用场景:大多数普通业务场景,如常规的业务数据上报。
3. acks=all(或acks=-1)
含义:生产者发送消息后,需要等待分区的 leader 副本和所有 ISR(In-Sync Replicas,同步副本集)中的 follower 副本都确认接收并写入日志,才认为消息发送成功。
特点:
可靠性最高,消息几乎不可能丢失(除非所有 ISR 副本同时崩溃)。
速度最慢(需等待多个副本同步确认)。
适用场景:对数据可靠性要求极高的场景(如金融交易、支付记录等核心数据)。
生产者消息幂等性


kafka生产者打开幂等性需要打开以下配置: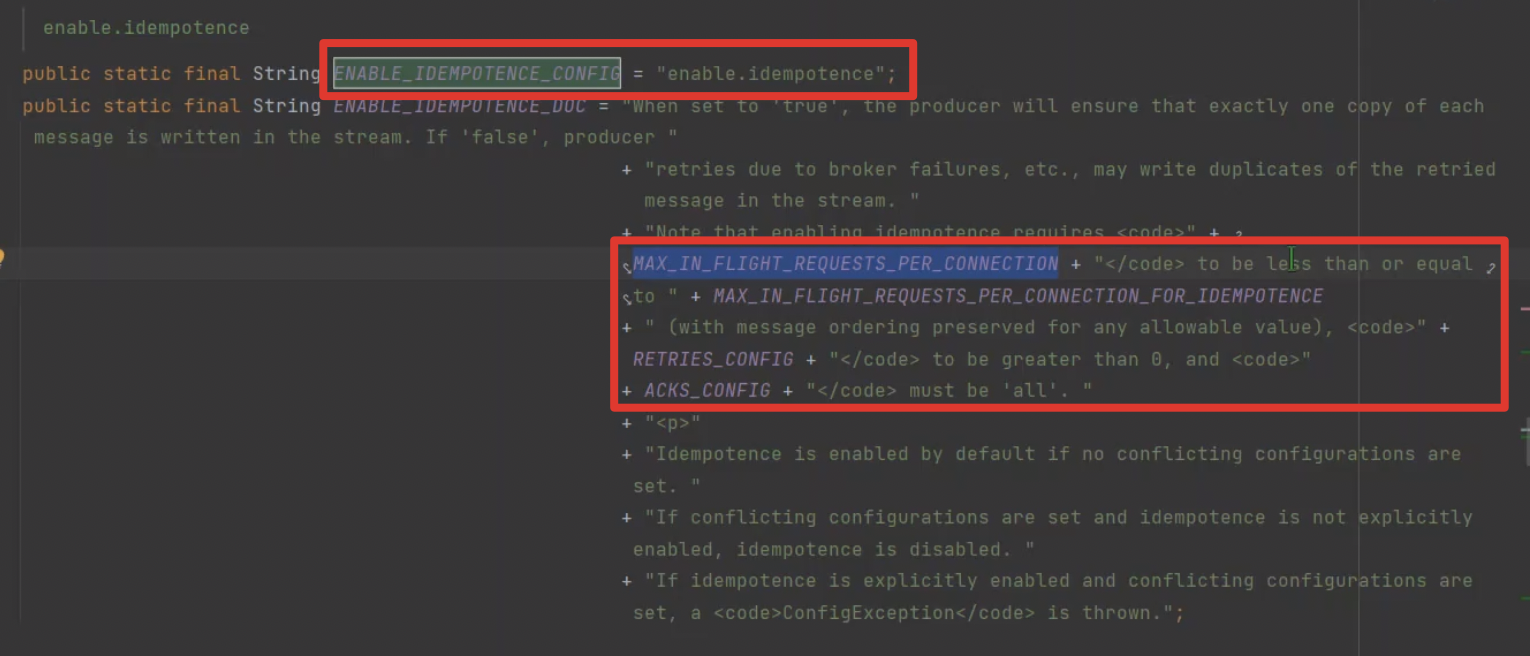
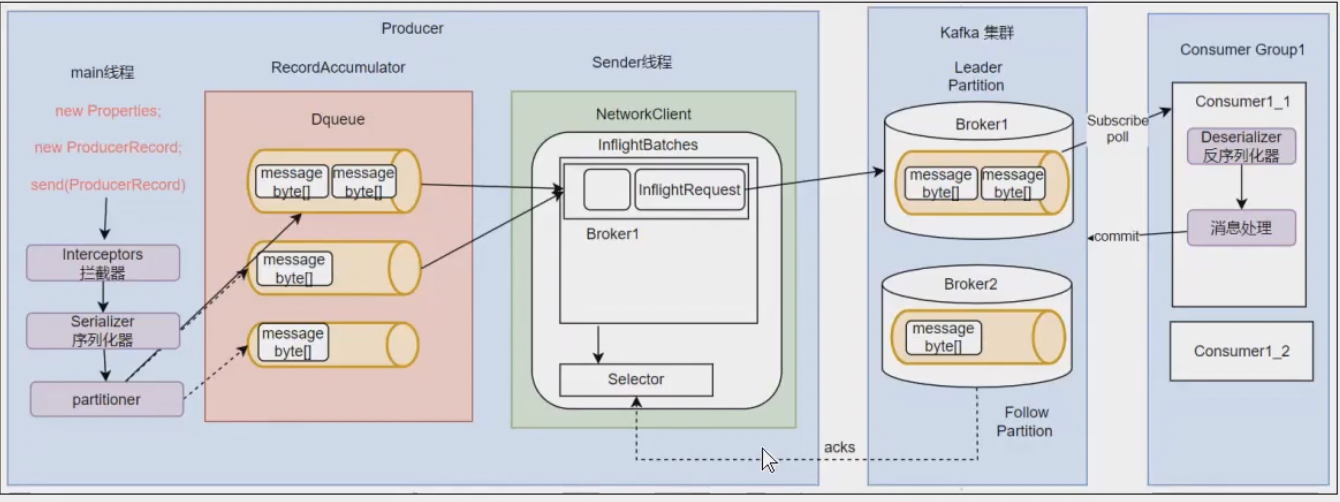
kafka消息发送流程
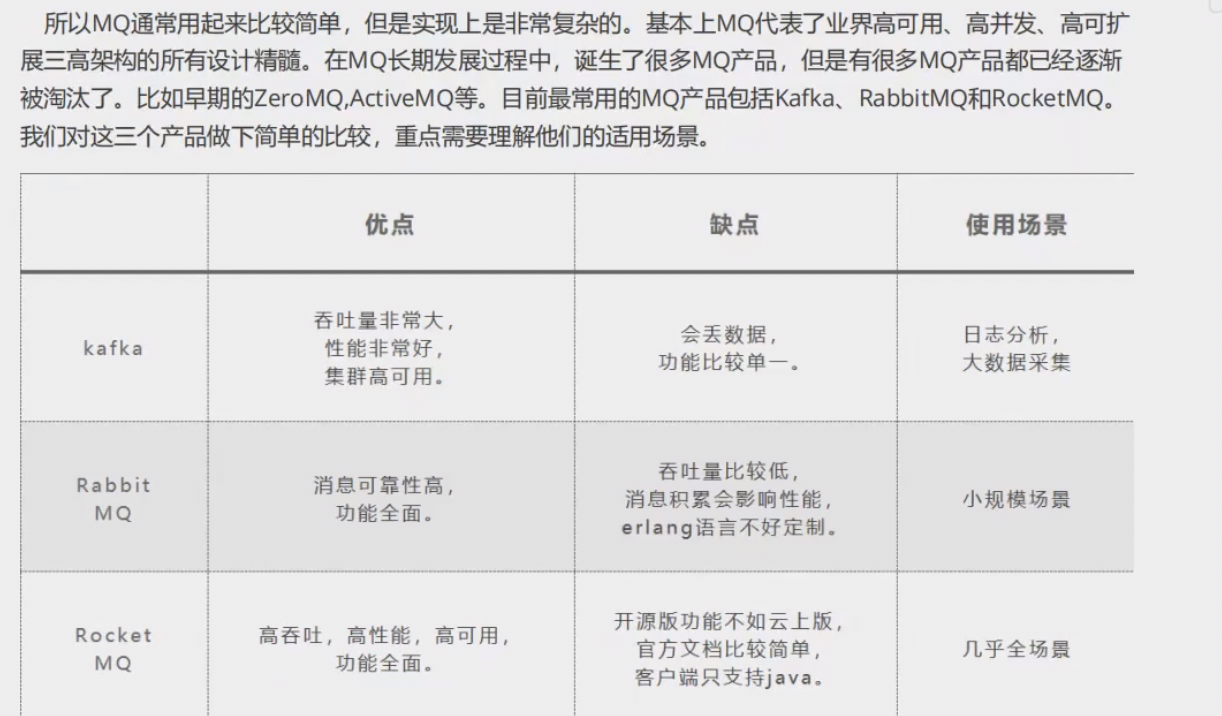
主流mq的对比
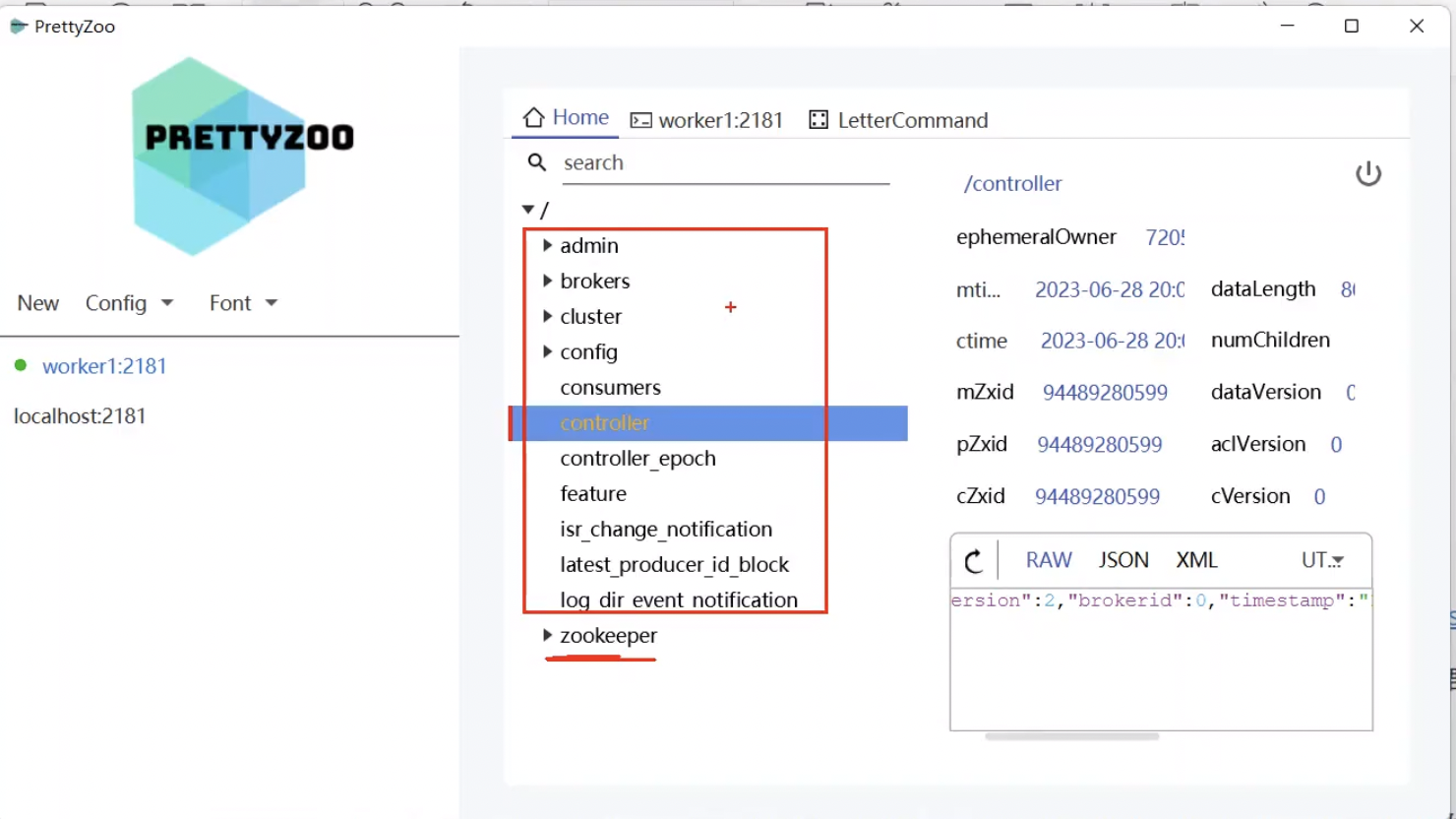
zookeeper在kafka中的作用
1.zookeeper整体数据
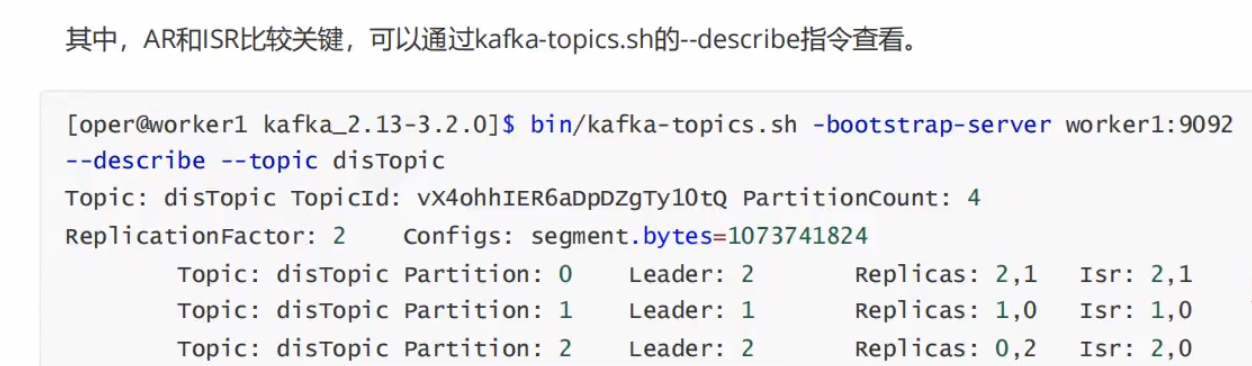
2.Controller Broker选举机制


3.Leader Partition选举机制

4.leader Partition的自平衡机制


5.Partition的故障恢复机制

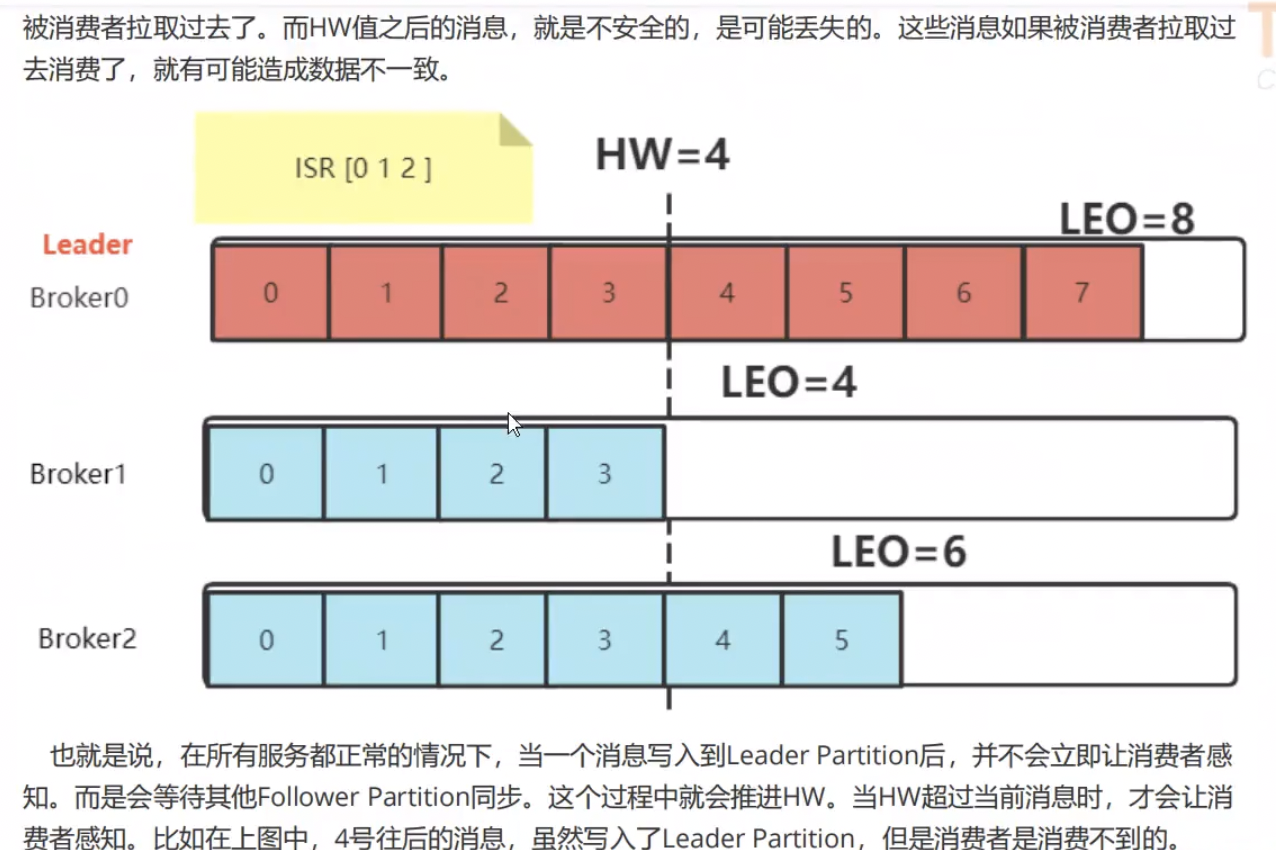
如果leader挂了,新的leader选举前,该partion服务不可用,流程如下,如下: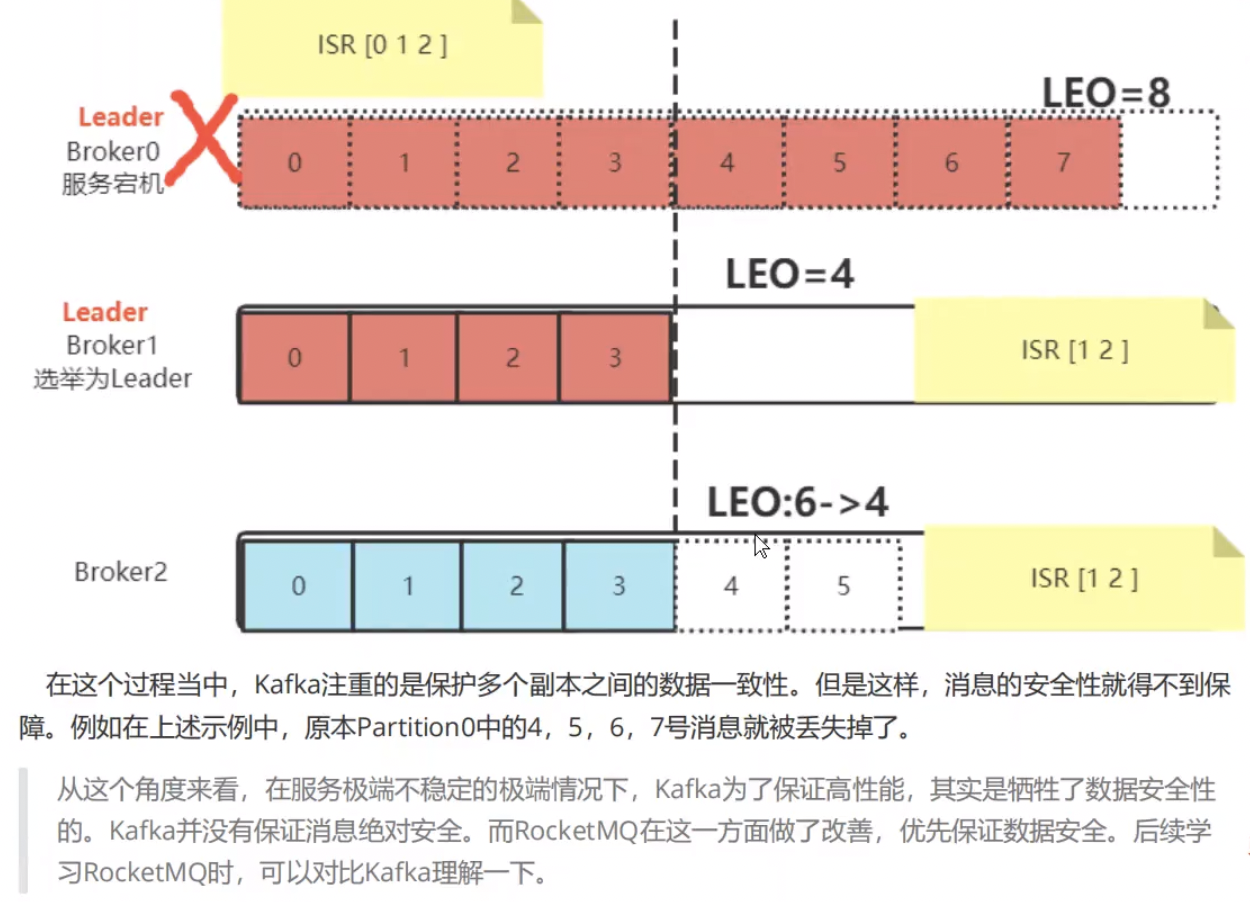
6.HW一致性保障-Epoch更新机制

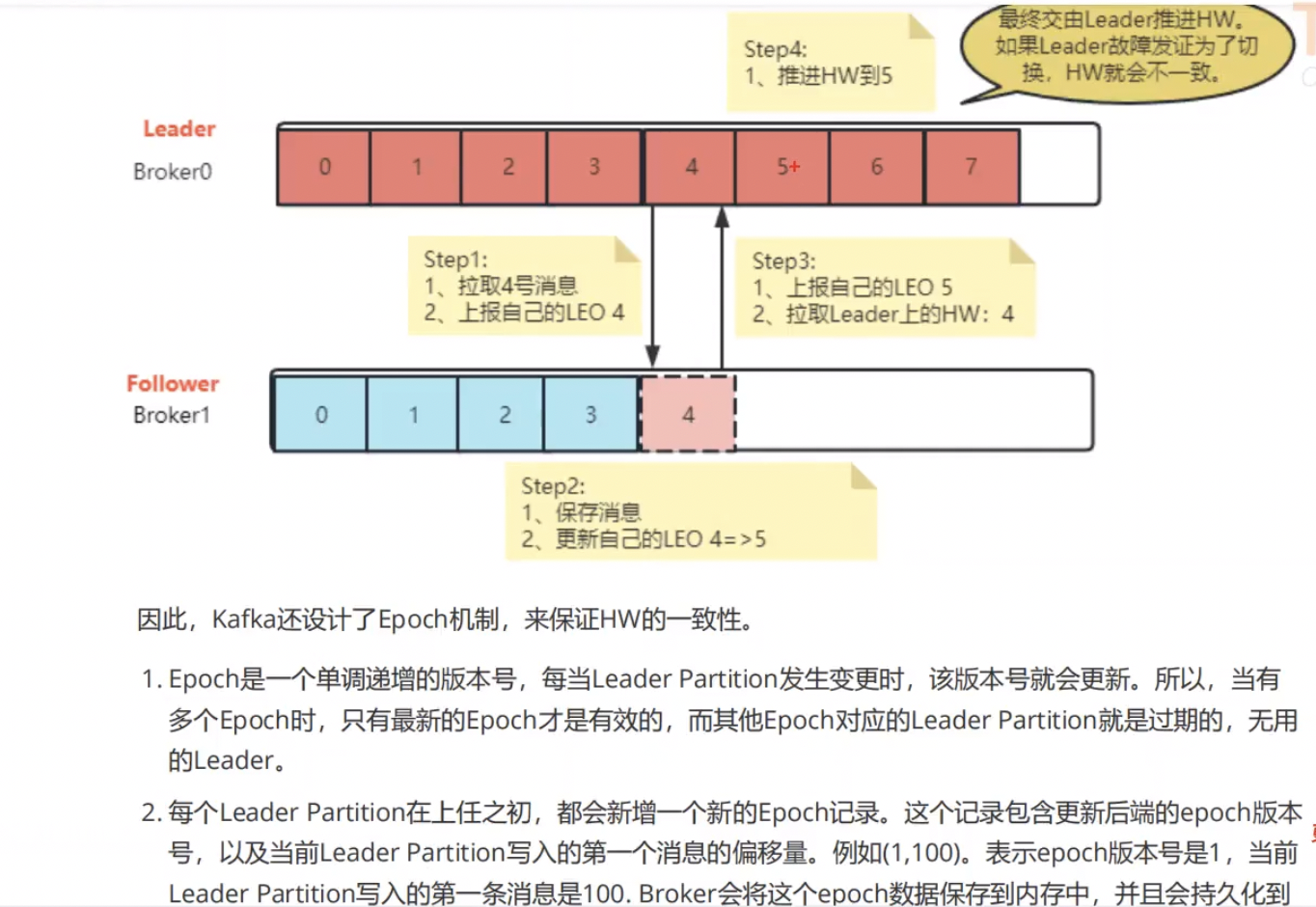


Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)