Spark Streaming消费Kafka,自定义Offset执行报错 No current assignment for partition topicBC-3
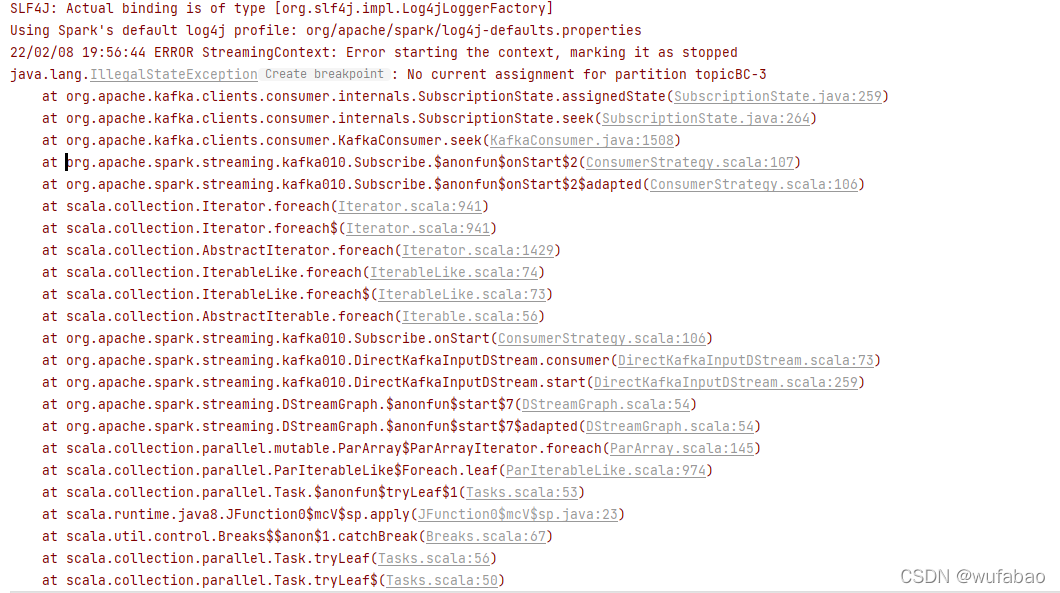
报错内容java.lang.IllegalStateException: No current assignment for partition topicBC-3at org.apache.kafka.clients.consumer.internals.SubscriptionState.assignedState(SubscriptionState.java:259)at org.apach
·
报错内容
java.lang.IllegalStateException: No current assignment for partition topicBC-3
at org.apache.kafka.clients.consumer.internals.SubscriptionState.assignedState(SubscriptionState.java:259)
at org.apache.kafka.clients.consumer.internals.SubscriptionState.seek(SubscriptionState.java:264)
at org.apache.kafka.clients.consumer.KafkaConsumer.seek(KafkaConsumer.java:1508)
at org.apache.spark.streaming.kafka010.Subscribe.$anonfun$onStart$2(ConsumerStrategy.scala:107)
at org.apache.spark.streaming.kafka010.Subscribe.$anonfun$onStart$2$adapted(ConsumerStrategy.scala:106)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.spark.streaming.kafka010.Subscribe.onStart(ConsumerStrategy.scala:106)
at org.apache.spark.streaming.kafka010.DirectKafkaInputDStream.consumer(DirectKafkaInputDStream.scala:73)
at org.apache.spark.streaming.kafka010.DirectKafkaInputDStream.start(DirectKafkaInputDStream.scala:259)
at org.apache.spark.streaming.DStreamGraph.$anonfun$start$7(DStreamGraph.scala:54)
at org.apache.spark.streaming.DStreamGraph.$anonfun$start$7$adapted(DStreamGraph.scala:54)
at scala.collection.parallel.mutable.ParArray$ParArrayIterator.foreach(ParArray.scala:145)
at scala.collection.parallel.ParIterableLike$Foreach.leaf(ParIterableLike.scala:974)
at scala.collection.parallel.Task.$anonfun$tryLeaf$1(Tasks.scala:53)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.util.control.Breaks$$anon$1.catchBreak(Breaks.scala:67)
at scala.collection.parallel.Task.tryLeaf(Tasks.scala:56)
at scala.collection.parallel.Task.tryLeaf$(Tasks.scala:50)
at scala.collection.parallel.ParIterableLike$Foreach.tryLeaf(ParIterableLike.scala:971)
at scala.collection.parallel.AdaptiveWorkStealingTasks$WrappedTask.compute(Tasks.scala:153)
at scala.collection.parallel.AdaptiveWorkStealingTasks$WrappedTask.compute$(Tasks.scala:149)
at scala.collection.parallel.AdaptiveWorkStealingForkJoinTasks$WrappedTask.compute(Tasks.scala:440)
at java.util.concurrent.RecursiveAction.exec(RecursiveAction.java:189)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157)
at ... run in separate thread using org.apache.spark.util.ThreadUtils ... ()
at org.apache.spark.streaming.StreamingContext.liftedTree1$1(StreamingContext.scala:583)
at org.apache.spark.streaming.StreamingContext.start(StreamingContext.scala:575)
at com.wufabao.streaming.kafka.KafkaDStream2$.main(KafkaDStream2.scala:57)
原因:自己指定了消费到三个分区,但是在kafka配置文件中设置的分区数量为一个,导致程序在执行的过程中,同一个 groupID 在同一时刻多次消费同一个 topic,导致了报错的产生。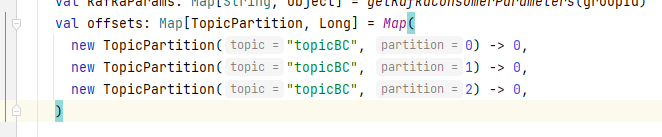
解决方案:把kafka的分区配置文件(kafka_2.12-1.0.2/config/server.properties)设置为三个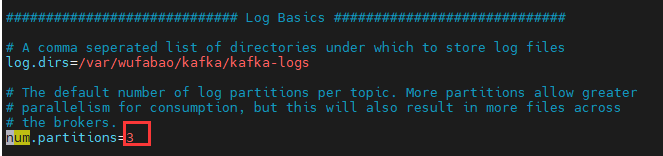

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)