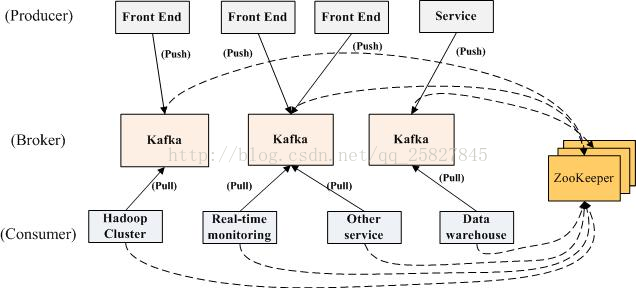
动态从zookeeper中读取kafka集群
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为bro
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/56049022冷血之心的博客)
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
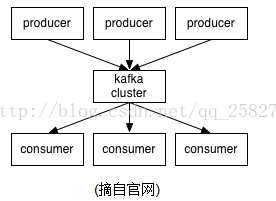
1.producer:
消息生产者,发布消息到 kafka 集群的终端或服务。
2.broker:
kafka 集群中包含的服务器。
3.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。
4.partition:
partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
5.consumer:
从 kafka 集群中消费消息的终端或服务。
6.Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
7.replica:
partition 的副本,保障 partition 的高可用。
8.leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
9.follower:
replica 中的一个角色,从 leader 中复制数据。
10.controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
12.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。
以下是如何从zookeeper中动态读取kafka集群中brokers的方法。
public class KafkaBrokerInfoFetcher {
public static void main(String[] args) throws Exception {
ZooKeeper zk = new ZooKeeper("localhost:2181", 10000, null);
List<String> ids = zk.getChildren("/brokers/ids", false);
for (String id : ids) {
String brokerInfo = new String(zk.getData("/brokers/ids/" + id, false, null));
System.out.println(id + ": " + brokerInfo);
}
}
}1: {"jmx_port":-1,"timestamp":"1428512949385","host":"192.168.0.11","version":1,"port":9093}
2: {"jmx_port":-1,"timestamp":"1428512955512","host":"192.168.0.11","version":1,"port":9094}
3: {"jmx_port":-1,"timestamp":"1428512961043","host":"192.168.0.11","version":1,"port":9095}如果对你有帮助,记得点赞哦~欢迎大家关注我的博客,可以进群366533258一起交流学习哦~

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)