java写kafka的生产者与消费者代码
kafka、producer、consumer
1、环境说明:
OS:redhat6.5 ,cloudera-mamager5.7 ,zookeeper-3.4.5 ,kafka-0.9.0
2、kafka的配置:
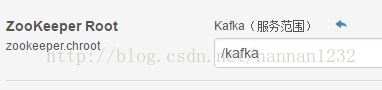
zookeeper和kafka都是默认配置
3、引用的包:
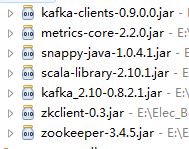
4、producer程序:
package com.kafka;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
public class KafkaProducer extends Thread{
private String topic;
public KafkaProducer(String topic){
super();
this.topic = topic;
}
@Override
public void run() {
Producer<Integer, String> producer = createProducer();
int i=0;
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//设置日期格式
while(true){
producer.send(new KeyedMessage<Integer, String>(topic, "时间:"+ df.format(new Date())+",message: " + i++));
System.out.println("发送时间:"+ df.format(new Date())+",message: " + i);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private Producer<Integer, String> createProducer() {
Properties properties = new Properties();
properties.put("zookeeper.connect", "10.2.46.129:2181,10.2.46.130:2181,10.2.46.131:2181");//zookeeper安装在机器IP
properties.put("serializer.class", StringEncoder.class.getName());
properties.put("metadata.broker.list", "10.2.46.131:9092");// kafka安装的机器IP
return new Producer<Integer, String>(new ProducerConfig(properties));
}
public static void main(String[] args) {
new KafkaProducer("333").start();// 使用kafka集群中创建好的主题
}
}
5、consumer程序:
package com.kafka;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class KafkaConsumerEx {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerEx.class);
public static void main(String[] args) {
KafkaConsumerEx kc =new KafkaConsumerEx();
kc.testConsumer();
}
public void testConsumer()
{
b("333");
}
private void b(String topic)
{
ConsumerConnector consumer = createConsumer();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1); // 一次从主题中获取一个数据
Map<String, List<KafkaStream<byte[], byte[]>>>messageStreams = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = messageStreams.get(topic).get(0);// 获取每次接收到的这个数据
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//设置日期格式
while(iterator.hasNext()){
String message = new String(iterator.next().message());
System.out.println("接收到时间:"+ df.format(new Date())+",message: " + message);
}
}
private ConsumerConnector createConsumer() {
Properties props = new Properties();
props.put("zookeeper.connect", "10.2.46.129:2181,10.2.46.130:2181,10.2.46.131:2181/kafka");//声明zk
props.put("group.id", "555");
return Consumer.createJavaConsumerConnector(new ConsumerConfig(props));
}
}

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)