Spark Streaming + Kafka direct 从Zookeeper中恢复offset
在上一遍《将 Spark Streaming + Kafka direct 的 offset 保存进入Zookeeper》中,我们已经成功的将 topic 的 partition 的 offset 保存到了 Zookeeper中,使监控工具发挥了其监控效果。那现在是时候来处理《“Spark Streaming + Kafka direct + checkpoints + 代码改变” 引发的问题》中
在上一遍《将 Spark Streaming + Kafka direct 的 offset 保存进入Zookeeper》中,我们已经成功的将 topic 的 partition 的 offset 保存到了 Zookeeper中,使监控工具发挥了其监控效果。那现在是时候来处理《“Spark Streaming + Kafka direct + checkpoints + 代码改变” 引发的问题》中提到的问题了。
解决的方法是:分别从Kafka中获得某个Topic当前每个partition的offset,再从Zookeeper中获得某个consumer消费当前Topic中每个partition的offset,最后再这两个根据项目情况进行合并,就可以了。
一、具体实现
1、程序实现,如下:
public class SparkStreamingOnKafkaDirect{
public static JavaStreamingContext createContext(){
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("SparkStreamingOnKafkaDirect");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(30));
jsc.checkpoint("/checkpoint");
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list","192.168.1.151:1234,192.168.1.151:1235,192.168.1.151:1236");
Map<TopicAndPartition, Long> topicOffsets = getTopicOffsets("192.168.1.151:1234,192.168.1.151:1235,192.168.1.151:1236", "kafka_direct");
Map<TopicAndPartition, Long> consumerOffsets = getConsumerOffsets("192.168.1.151:2181", "spark-group", "kafka_direct");
if(null!=consumerOffsets && consumerOffsets.size()>0){
topicOffsets.putAll(consumerOffsets);
}
// for(Map.Entry<TopicAndPartition, Long> item:topicOffsets.entrySet()){
// item.setValue(0l);
// }
for(Map.Entry<TopicAndPartition,Long> entry:topicOffsets.entrySet()){
System.out.println(entry.getKey().topic()+"\t"+entry.getKey().partition()+"\t"+entry.getValue());
}
JavaInputDStream<String> lines = KafkaUtils.createDirectStream(jsc,
String.class, String.class, StringDecoder.class,
StringDecoder.class, String.class, kafkaParams,
topicOffsets, new Function<MessageAndMetadata<String,String>,String>() {
public String call(MessageAndMetadata<String, String> v1)
throws Exception {
return v1.message();
}
});
final AtomicReference<OffsetRange[]> offsetRanges = new AtomicReference<>();
JavaDStream<String> words = lines.transform(
new Function<JavaRDD<String>, JavaRDD<String>>() {
@Override
public JavaRDD<String> call(JavaRDD<String> rdd) throws Exception {
OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
return rdd;
}
}
).flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(
String event)
throws Exception {
return Arrays.asList(event);
}
});
JavaPairDStream<String, Integer> pairs = words
.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(
String word) throws Exception {
return new Tuple2<String, Integer>(
word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs
.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2)
throws Exception {
return v1 + v2;
}
});
lines.foreachRDD(new VoidFunction<JavaRDD<String>>(){
@Override
public void call(JavaRDD<String> t) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("192.168.1.151:2181").connectionTimeoutMs(1000)
.sessionTimeoutMs(10000).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (OffsetRange offsetRange : offsetRanges.get()) {
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/spark-group/offsets/" + offsetRange.topic()+ "/" + offsetRange.partition();
if(curatorFramework.checkExists().forPath(nodePath)!=null){
curatorFramework.setData().forPath(nodePath,offsetBytes);
}else{
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
}
curatorFramework.close();
}
});
wordsCount.print();
return jsc;
}
public static Map<TopicAndPartition,Long> getConsumerOffsets(String zkServers,
String groupID, String topic) {
Map<TopicAndPartition,Long> retVals = new HashMap<TopicAndPartition,Long>();
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(zkServers).connectionTimeoutMs(1000)
.sessionTimeoutMs(10000).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
try{
String nodePath = "/consumers/"+groupID+"/offsets/" + topic;
if(curatorFramework.checkExists().forPath(nodePath)!=null){
List<String> partitions=curatorFramework.getChildren().forPath(nodePath);
for(String partiton:partitions){
int partitionL=Integer.valueOf(partiton);
Long offset=objectMapper.readValue(curatorFramework.getData().forPath(nodePath+"/"+partiton),Long.class);
TopicAndPartition topicAndPartition=new TopicAndPartition(topic,partitionL);
retVals.put(topicAndPartition, offset);
}
}
}catch(Exception e){
e.printStackTrace();
}
curatorFramework.close();
return retVals;
}
public static Map<TopicAndPartition,Long> getTopicOffsets(String zkServers, String topic){
Map<TopicAndPartition,Long> retVals = new HashMap<TopicAndPartition,Long>();
for(String zkServer:zkServers.split(",")){
SimpleConsumer simpleConsumer = new SimpleConsumer(zkServer.split(":")[0],
Integer.valueOf(zkServer.split(":")[1]),
10000,
1024,
"consumer");
TopicMetadataRequest topicMetadataRequest = new TopicMetadataRequest(Arrays.asList(topic));
TopicMetadataResponse topicMetadataResponse = simpleConsumer.send(topicMetadataRequest);
for (TopicMetadata metadata : topicMetadataResponse.topicsMetadata()) {
for (PartitionMetadata part : metadata.partitionsMetadata()) {
Broker leader = part.leader();
if (leader != null) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, part.partitionId());
PartitionOffsetRequestInfo partitionOffsetRequestInfo = new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.LatestTime(), 10000);
OffsetRequest offsetRequest = new OffsetRequest(ImmutableMap.of(topicAndPartition, partitionOffsetRequestInfo), kafka.api.OffsetRequest.CurrentVersion(), simpleConsumer.clientId());
OffsetResponse offsetResponse = simpleConsumer.getOffsetsBefore(offsetRequest);
if (!offsetResponse.hasError()) {
long[] offsets = offsetResponse.offsets(topic, part.partitionId());
retVals.put(topicAndPartition, offsets[0]);
}
}
}
}
simpleConsumer.close();
}
return retVals;
}
public static void main(String[] args) throws Exception{
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
public JavaStreamingContext create() {
return createContext();
}
};
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate("/checkpoint", factory);
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
2、准备测试环境,并记录目前consumer中的信息,如下图: 
从界面上可以看到,目前所有的消息都已经被处理过了。
现在向kafka_direct中新增一个消息,如下图:
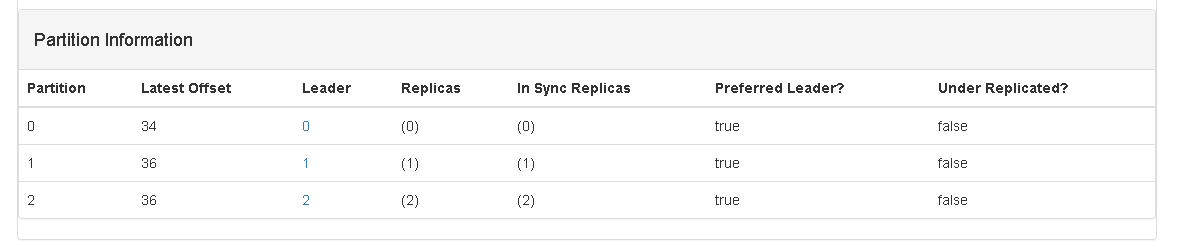
3、运行Spark Streaming 程序(注意:要先清空 checkpoint 目录下的内容),观察命令行输出情况,及kafka manager中关于 spark-group的变化情况:
命令行输出: 
打印出了,从zookeeper中读取到的offset。

打印出了,从Kafka的kafka_direct中消费的消息的结果数据。
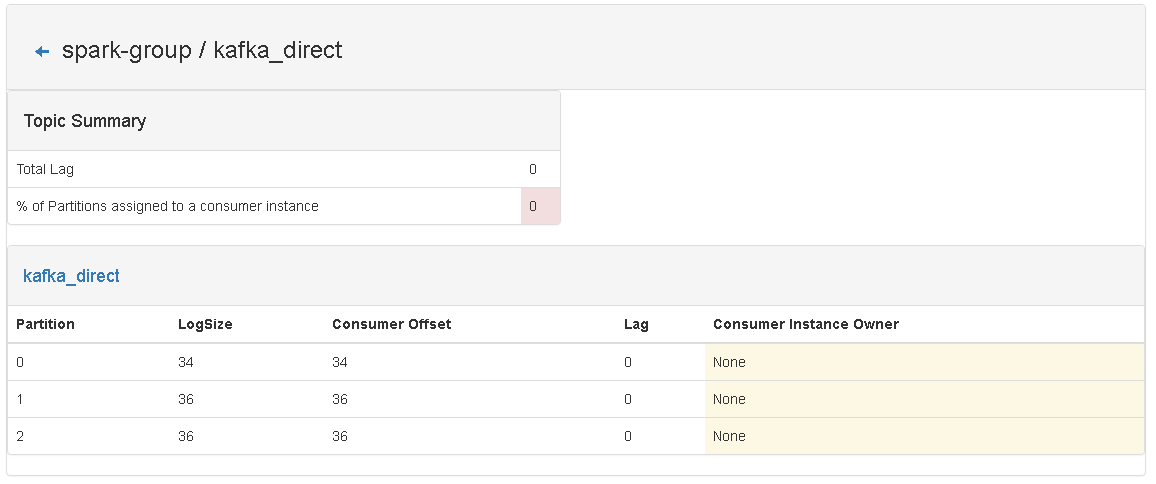
从图片中,可以看到consumer offset 和 logSize 是一样的。
4、下面我们人为的将topic的partition的offset的值设置为0,看其是否会打印出所有消息的结果数据。
(取消上面程序中注释的部分即可)
5、再次运行Spark Streaming 程序(注意:要先清空 checkpoint 目录下的内容),看命令行输出效果: 
从图中,可以看出Spark Streaming 程序将之前所有的测试消息都重新处理了一次。
至此,《“Spark Streaming + Kafka direct + checkpoints + 代码改变” 引发的问题》的整个解决的过程都已经结束了。
说明:源代码中,由于时间紧,没有写注释,等后面有时间了再补上。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)