Kafka 实战开篇-讲解架构模型、基础概念以及集群搭建
该博文作为专栏【Kafka】第一篇,为大家了整理了各大消息中间件之间的特性以及优劣势,结合 AKF 划分原则对 Kafka 集群、Topic、Partition 作了划分;通过自身理解的【架构模型】为大家提前梳理清楚一些概念以及问题,在 Kafka 中存在的角色作了一些概述;最后,以实践校验真理的唯一准则,搭建了 Kafka 集群以及通过控制台方式整理了一些常用命令以及对前面所描述的一些问题作了验

🔭 嗨,您好 👋 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者
📖 推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代
🌲文章所在专栏:Kafka
🤔 我当前正在学习微服务领域、云原生领域、消息中间件等架构、原理知识
💬 向我询问任何您想要的东西,ID:vnjohn
🔥觉得博主文章写的还 OK,能够帮助到您的,感谢三连支持博客🙏
😄 代词: vnjohn
⚡ 有趣的事实:音乐、跑步、电影、游戏
目录
前言
什么是 Kafka?是做什么的,官网定义如下:
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
翻译过来,大概意思就是:这是一个实时数据处理系统,可以横向扩展以及高可靠!
实时数据处理,从名字上看,很好理解,就是将数据进行实时处理,在现在流行的微服务开发当中,最常用的实时数据处理平台包括了:RocketMQ、RabbitMQ 等消息中间件.
从网上整理资料加上自身理解,对 Kafka、RocketMQ、RabbitMQ 这三种中间件做一下对比,如下:

这些中间件,最大的特点主要有两个:
- 服务/业务解耦,中间件与程序无强关联
- 流量削峰,将服务的一部分流量交给中间件去作处理
AKF 划分原则
通过 AKF 划分原则来认识 Kafka

- X 轴:处理的服务节点的单点问题,支持横向扩展、全量镜像
- Y 轴:在 Kafka 服务节点基础上根据业务来划分出不同的 Topic
- Z 轴:基于 Topic 分配出不同的 partition 分区,每个 partition 分散到不同的服务节点上
架构模型
一个好的中间件设计,必然要关注它的架构模型;对于大数据处理下,一个重要、必然的概念:分而治之
- 无关联的数据将其分散到不同的分区上,以追求并发并行的目标,分区外部是无序的
- 有关联的数据,保证按顺序发送到同一个分区上,通过
offset 偏移量来保证分区内部是有序执行的
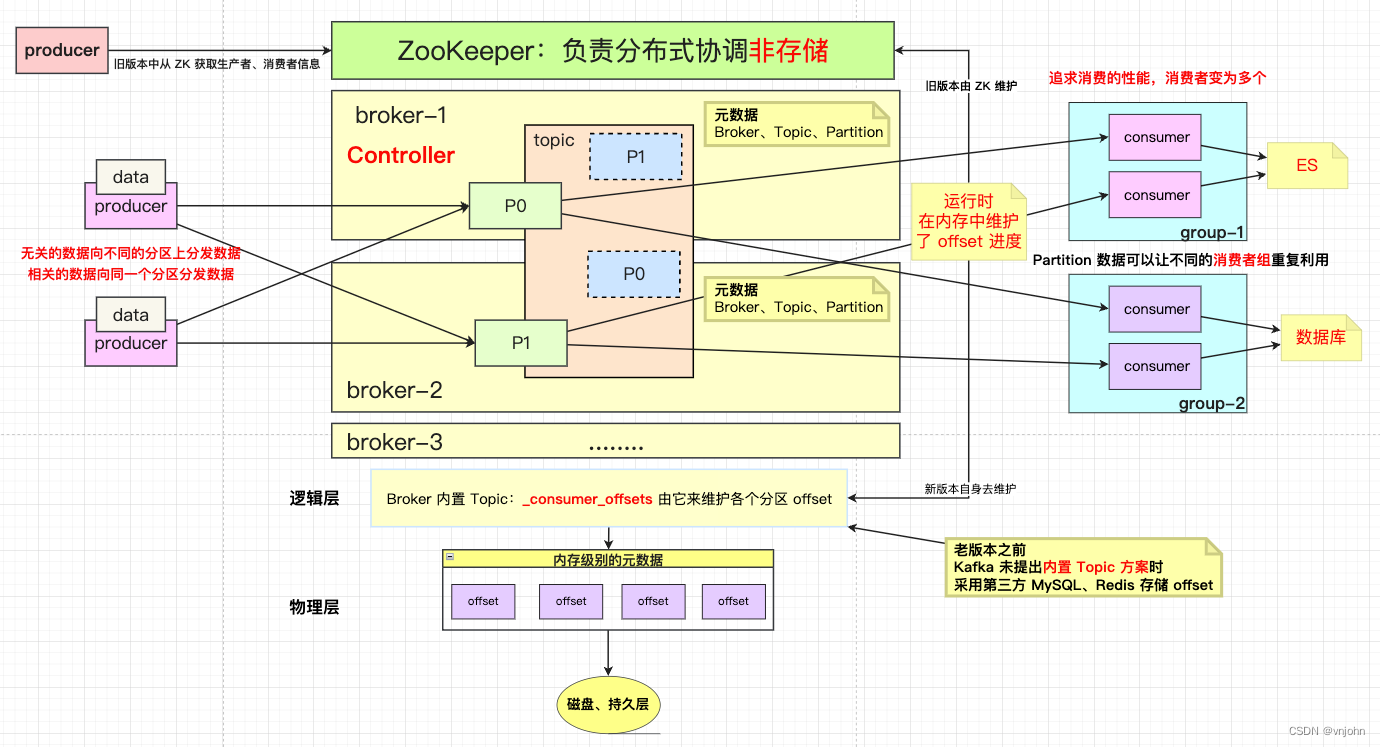
如下关注它的架构模型图

架构模型图简述:
- 在
Kafka 0.9 版本之前,由 ZK 来获取所有的客户端元数据信息(生产者、消费者、偏移量)信息;在Kafka 0.9 版本之后,新版本会把这些信息保存在一个 Kafka 内部主题【_consumer_offsets】内,通过集群中一个名为Coordinator组件进行管理 - 服务端元数据【broker 节点元数据信息、Controller 信息(
ids、broker metadata、topic、partitio)】 仍然是从 ZK 中获取,Controller 会从 ZK 中获取最新的元数据信息缓存在服务节点的内存中;这些信息后面通过使用 Kafka 操作时再来观察是否如此! - 在生产者产生数据时,在并发场景下需要保证一致性(数据从 partition -> Kafka 入地)时,需要 Producer 在锁粒度范围内将数据发送到 broker 中
- Partition、Consumer 关系只有
1:1 或 N:1,而绝不能是1:N关系,主要是一个分区内的数据必须保证顺序的在一个消费者中执行完毕
在实际应用中,建议消费者 consumer 数量与 partition 数量保持一致,若消费者数量多于分区数量的情况下,会出现消费者处于闲置的情况;若分区数量多于消费者数量的话,会出现消费性能不均衡的情况
- 在运行时,内存需要维护 partition 读取数据的 offset,在旧版本中,由 ZK 来负担这一块的业务需求,在新版本未出现自身来确保 Topic 维护 offset 时,而不得已要采用第三方处理的方式来进行过渡【Redis、MySQL等】
- 数据重复利用:Kafka -> Broker -> Partition,保存了来自 Producer 发送的数据,重点是 “数据” 怎么可以重复利用,在使用场景下,先要保证即便为了追求性能,使用多个 Consumer,也应该要注意,不能一个分区被多个消费者去消费【浪费资源】
数据的重复利用是建立在 Group 上的,但是在 Group 内要保证
第四点所描述的
一个分区内的数据不能被多个 consumer 消费,也就是决不能存在 1:N 关系
【问题】: 在 Consumer 消费时,会出现数据重复消费或丢失的问题,围绕的就是 offset 消费的进度【节奏?频率?先后】以下是在消费数据时所遇到的几种情况
异步:5 秒之内,先干活,再持久化 offset,若干活的时候突然宕机了,导致 offset 没被写入,会造成重复消费
同步:业务操作、offset 持久化,虽然安全但会造成性能的下降
没有控制好顺序,offset 持久了,但是业务写失败了
角色概述
Broker:一个 Kafka 节点就是一个 Broker,一个集群由多个 Broker 组成,一个 Broker 可以容纳多个 Topic
Broker 接受来自生产者产生的消息,为消息设置偏移量,提交消息到磁盘持久化
Broker 为消费者提供服务,对读取分区的请求作出响应,返回给消费者在磁盘持久化后的消息
Producer:消息的生产方,即消息的入口
Consumer:消息的消费方,即消息的出口
Topic:消息通过业务划分,生产者向 Broker 发送消息时指定 Topic,消费者读取消息时也要指定 Topic
Partition:Topic 分为多个 Partition,相关的数据放入到一个 Partition 中,无关的数据放入到不同的 Partition 中,消息以追加方式写入到 Partition,后以先进先出的顺序读取
Replication:一个分区存在多个副本,副本作用是备胎 -> 高可用,主分区(Leader)会将数据同步到从分区(Follower)当主分区故障时会选择一个备胎(Follower)上位,成为 Leader
在 Kafka 中,默认副本最大数量是 10 个,且副本的数量不能大于 Broker 数量,Follower、Leader 绝对是在不同的节点上,一台节点对同一个分区也只只可能存放一个副本
Consumer Group:按业务线(开发小组)不同来划分不同的消费组,以促使可以重复消费数据
Offset:偏移量,Kafka 存储文件是按照 offset.kafka,用 offset 作为名字的好处是方便查找!
Kafka 集群搭建
下载 Kafka 版本:2.1.0,准备三台虚拟机节点 -> node1~node3
由于 Kafka 依赖于 ZooKeeper 作分布式协调处理,前置环境要求:Jdk 8、ZooKeeper,博主整理了这两篇文章帮你完成前置环境的准备
Mac M1 搭建虚拟机节点集群过程及软件分享
分布式组件 ZooKeeper 介绍、术语概述以及集群搭建篇
Kafka 安装包下载地址:https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
安装
将下载好的包放入虚拟机节点目录下,比如:/opt/vnjohn
1、解压安装包:tar -xzf /opt/vnjohn/kafka_2.12-2.1.0.tgz
2、更改名字:mv kafka_2.12-2.1.0 kafka
3、更新 config 目录下 server.properties 文件
# 每台 Kafka 节点配置的都不一样
broker.id=0
# 每台 Kafka 节点要配上自己的 主机:端口号
listeners=PLAINTEXT://node1:9092
# hostname、port 都会广播给 producer、consumer
# 如果你没有配置了这个属性【advertised.listeners】的话,则使用 listeners 的值
# 如果 listeners 值也没有配置的话,则使用 java.net.InetAddress.getCanonicalHostName() 返回值
# java.net.InetAddress.getCanonicalHostName() 返回值就是 localhost
# advertised.listeners=PLAINTEXT://node-1:9092
# 日志文件存储到什么位置下
log.dirs=/var/vnjohn/kafka
# 配置上 ZK 连接信息及目录节点 /kafka
zookeeper.connect=node1:2181/kafka,node2:2181/kafka,node3:2181/kafka
4、调整 /etc/profile 配置文件内容【Shift+G 跳转至最后一行】,追加内容如下:
export KAFKA_HOME=/opt/vnjohn/kafka
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin
刷新配置文件:source /etc/profile
若配置文件修改出现问题,导致所有命令都不生效了,运行✅:export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin 后,再重新调整配置
若配置没有问题的话,输入 kafka 后 Tab 键会出现如下图:

5、node1 配置好了,同步这段配置给 node2、node3,将 kafka 导出到本地,通过 SFTP 方式传给 node2、node3 虚拟机节点上,最后,修改 server.properties 配置文件即可,如下:
# node2
broker.id=1
listeners=PLAINTEXT://node2:9092
# node3
broker.id=2
listeners=PLAINTEXT://node3:9092
更改【node2、node3】/etc/profile 文件,再刷新配置即可
6、node1~node3 启动 Kafka 之前,先通过后台方式启动 ZK【zkServer.sh start】,然后执行命令:kafka-server-start.sh /opt/vnjohn/kafka/config/server.properties

启动出现错误,告知我们,使用 G1 垃圾回收器时必须开启 -XX:+UnlockExperimentalVMOptions
Kafka 默认采用 G1 垃圾回收器,通过脚本可查看:

之前在 Windows 搭建的虚拟机节点不会出现这样的错误,在 Mac 搭建出现了这样的问题,猜测可能是内核的原因导致作了这样的限制吧,查阅网上资料,得知,这是与我们的 Jdk 版本相关,它使用了 Graal 作了 JIT 即时编译器
注意:Graal 是一项实验性功能,仅在 Linux-x64 上受支持
所以,我们要启用 Graal 作为 JIT 编译器,VM 参数要追加配置如下:
-XX:+UnlockExperimentalVMOptions
调整 /opt/vnjohn/kafka/bin/kafka-run-class.sh 脚本内容,如下:

在执行创建生产者、消费者命令【kafka-console-producer.sh、kafka-console-consumer.sh】也会出现这个错误,只需要将一段脚本配置删除,让它默认引用 kafka-run-class.sh 脚本的 JVM 配置即可.

最后,在 node1~node3 执行 kafka-server-start.sh /opt/vnjohn/kafka/config/server.properties 命令启动 Kafka;默认的是在前台运行,会打印日志,后台运行 Kafka 命令:nohup /opt/vnjohn/kafka/bin/kafka-server-start.sh /opt/vnjohn/kafka/config/server.properties >/dev/null 2>&1 &
启动 Kafka 集群成功!!!

7、连接 ZK 客户端【zkCli.sh】,观察它下面的目录节点,看 Controller 角色对应的是哪一台节点【get /kafka/controller】

brokerid =1 ,controller 分配给到了 node2 节点!
使用
Kafka 集群搭建完毕,现在是如何通过命令方式操作它了
1、创建 Topic
执行创建 Topic 操作,示例:topic(order-score)下有两个分区,每个分区对应两个副本
[root@node1 bin]# kafka-topics.sh --zookeeper node1:2181/kafka --create --topic order-score --partitions 2 --replication-factor 2
Created topic "order-score".
2、查看所拥有的 Topic
[root@node1 bin]# kafka-topics.sh --zookeeper node1:2181/kafka --list
order-score
3、查看指定 Topic 描述信息
[root@node1 bin]# kafka-topics.sh --zookeeper node1:2181/kafka --describe --topic order-score
Topic:order-score PartitionCount:2 ReplicationFactor:2 Configs:
Topic: order-score Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: order-score Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Leader 值是我们配置的 broker.id 值
分区的数量再多,也只是为了增加数据的可靠性,R/W 操作仍然只会发生在主(Leader)分区上
4、创建 consumer
创建一个消费者连接 Kafka 集群,订阅 order-score Topic,并分到 vnjohn 这个 group 组中
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic order-score --group vnjohn
该窗口会停顿在前台,一直是否有数据到来,比如,通过第五点 往这个 Topic 生产一些数据,它马上就会来响应到来!
5、创建 Producer
创建一个生产者连接 broker 节点拿到元数据信息,为 order-score 这个 topic 分发消息,接着会有输入框等待输入信息,输入/生产什么,上面的消费者就会消费什么
kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic order-score
6、结合第 4、5 点来看下效果
第一种:若只开启了一个消费者,所有的消息只会分发到那个消费者上

第二种:若开启了多个消费者并且在同一个组上,就会均匀分配消息(每一个消费者分配到了不同的分区上)

第三种:若开启了多个消费者但不是在同一个组上,消息是会被重复消费在不同的组中的

最后一种:如果在同一个组中,消费者多于分区的数量,那么多于分区数量的那些消费者是无法消费到数据的,因为 partition:consumer 1:N 是不成立的
前面我们在创建 order-score Topic 时,只为它分配了两个分区,这时我们开启四个消费者同时消费,看看是否有超过两个消费者在进行消费消息?

从图中可以看出,生产者产生的消息只有两个消费者一直在消费,而其他的两个消费者根本没有起作用,这证明了 partition:consumer 1:N 是不成立的 合理性
7、查看消费组 Group 信息
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
vnjohn01
vnjohn02
vnjohn
8、查看指定消费组 Group 信息
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn01
kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn02
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
order-score 0 8 8 0 consumer-1-4e2ad0fa-788e-48dd-8831-381f4bc06193 /172.16.249.10 consumer-1
order-score 1 9 9 0 consumer-1-8b056660-9d2f-450a-ac30-5480b72d6dfb /172.16.249.10 consumer-1
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn01
Consumer group 'vnjohn01' has no active members.
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
order-score 1 4 9 5 - - -
order-score 0 3 8 5 - - -
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --describe --group vnjohn02
Consumer group 'vnjohn02' has no active members.
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
order-score 1 4 9 5 - - -
order-score 0 3 8 5 - - -
从控制台输出的偏移量结果来看,group:vnjohn 将所有的消息都处理完了,group:vnjohn01、vnjohn02 两个组都各自还有 5 条数据未处理,因为刚刚产生了 10 条数据,按分区数量来分配,每个分区均匀分配,也就是各自 5 条
元数据
在【架构模型】上提及到了,服务端元数据【broker 节点元数据信息、Controller 信息(ids、broker metadata、topic、partition)】以及 Kafka 内部主题【_consumer_offsets】 ,接下来我们从 ZK 客户端上来对这些信息进行具体的查看!
1、查看 broker 节点信息:ls /kafka/brokers/ids
ls /kafka/brokers/ids
[0, 1, 2]
2、查看指定 broker 节点的元数据信息:get /kafka/brokers/ids/0
get /kafka/brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://node1:9092"],"jmx_port":-1,"host":"node1","timestamp":"1680229446282","port":9092,"version":4}
在配置文件中配置的 listeners 值、端口、host 都存储在这里!
3、获取所有的 Topic:ls /kafka/brokers/topics
ls /kafka/brokers/topics
[order-score, __consumer_offsets]
__consumer_offsets 不就出来了嘛!
4、获取 Topic:order-score 下分区信息: ls /kafka/brokers/topics/order-score/partitions
ls /kafka/brokers/topics/order-score/partitions
[0, 1]
5、获取 Topic:order-score 下指定的分区信息:get /kafka/brokers/topics/order-score/partitions/0/state
获取 Topic order-score 下分区 0 的状态信息:主分区及活跃分区(isr)
get /kafka/brokers/topics/order-score/partitions/0/state
{"controller_epoch":3,"leader":2,"version":1,"leader_epoch":2,"isr":[2,0]}
6、获取内部主题:_consumer_offsets 信息
get /kafka/brokers/topics/__consumer_offsets
{"version":1,"partitions":{"45":[0],"34":[1],"12":[0],"8":[2],"19":[1],"23":[2],"4":[1],"40":[1],"15":[0],"11":[2],"9":[0],"44":[2],"33":[0],"22":[1],"26":[2],"37":[1],"13":[1],"46":[1],"24":[0],"35":[2],"16":[1],"5":[2],"10":[1],"48":[0],"21":[0],"43":[1],"32":[2],"49":[1],"6":[0],"36":[0],"1":[1],"39":[0],"17":[2],"25":[1],"14":[2],"47":[2],"31":[1],"42":[0],"0":[0],"20":[2],"27":[0],"2":[2],"38":[2],"18":[0],"30":[0],"7":[1],"29":[2],"41":[2],"3":[0],"28":[1]}}
旧版本中将读取数据的 offset 持久化到 ZK 中,新版本是 Kafka 集群内部通过 Topic 来持久化的
可以看出除了我们自己创建的 Topic 以外,Kafka 还自身创建了一个消费数据时的 Offset Topic,以此来确保读取数据的准确性

拓扑回顾图

- 创建 Topic 会先经过 ZK,再找到 Controller 角色的 Broker,由它来进行创建,
Topic 是横跨集群下所有 Kafka 节点的 - Topic 划分了不同的 Partition,可以为每个 Partition 分配副本数量,Partition 副本是为了保证数据的可靠性,并不会参加 R/W 操作
- Producer 生产的数据会均匀地分配到各个 Partition 中,每一个分区对应一个 Consumer,
可形成 1:1 或 N:1 关系 - 同一个消费组中,消费者是不能重复消费的;不同的消费组,消费者是可以重复消费的
总结
该博文作为专栏【Kafka】第一篇,为大家了整理了各大消息中间件之间的特性以及优劣势,结合 AKF 划分原则对 Kafka 集群、Topic、Partition 作了划分;通过自身理解的【架构模型】为大家提前梳理清楚一些概念以及问题,在 Kafka 中存在的角色作了一些概述;最后,以实践校验真理的唯一准则,搭建了 Kafka 集群以及通过控制台方式整理了一些常用命令以及对前面所描述的一些问题作了验证操作!
若此文有帮助到您,实属开心,博主喜欢用图+理论梳理每一个学习到的知识点,一起开启学习之旅,后续博主会在该专栏【Kafka】中持续更新 Kafka 核心知识、实践问题以及如何避免,最重要的是会包含从源码角度为大家认证此前所梳理的内容,达到融会贯通!
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
大家的「关注❤️ + 点赞👍 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下文见!

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)