消息队列选型
第一梯队: KafKa ~ Disque ~ NSQ第二梯队: RocketMQ ~ RabbitMQ第三梯队:消息队列选型Sep 27, 2015什么是消息队列顾名思义,消息队列就是用存放消息的队列结构,简称MQ。那什么是消息呢?广义上来说,所有的网络通信都可以看做是消
第一梯队: KafKa ~ Disque ~ NSQ
第二梯队: RocketMQ ~ RabbitMQ
第三梯队:
消息队列选型
什么是消息队列
顾名思义,消息队列就是用存放消息的队列结构,简称MQ。那什么是消息呢?广义上来说,所有的网络通信都可以看做是消息的传递。在通信的过程中,添加一个队列缓冲,可以使得许多问题变得非常容易解决。
图:不使用消息队列的网络架构

图:使用消息队列的网络架构

题外话:在最初的面向对象编程的设计中,对象之间的交互并不是直接的方法调用,而是消息传递。比如,打开电脑,并不是简单的computer.start(),而是向computer对象实例发一个“开机”消息,computer对象实例收到这个消息后执行start()方法来处理这个消息。只不过,当下的主流编程语言中,只有Objective C完整的保留了这种语义。
为什要使用消息队列
为了更好的说明为什么要使用消息队列,这个举例一个实际的例子。现在我们要设计一个开放平台,平台中有很多服务实例,这些服务可以是我们自己实现的服务,也可能是由第三方提供的。服务之间以事件的方式的通信,服务提供的API可以是同步调用,也可以是异步调用。所有的API通过统一的代理层对外开放。对于内部服务,需要考虑系统的可伸缩性,充许调整每个服务的实例数量并进行负载均衡。对于由第三方提供的服务,需要进行并发控制,以免压力过大造成服务中断。
图:平台的整体架构

不使用消息队列的实现方案
图:平台的通信模型(不使用消息队列)
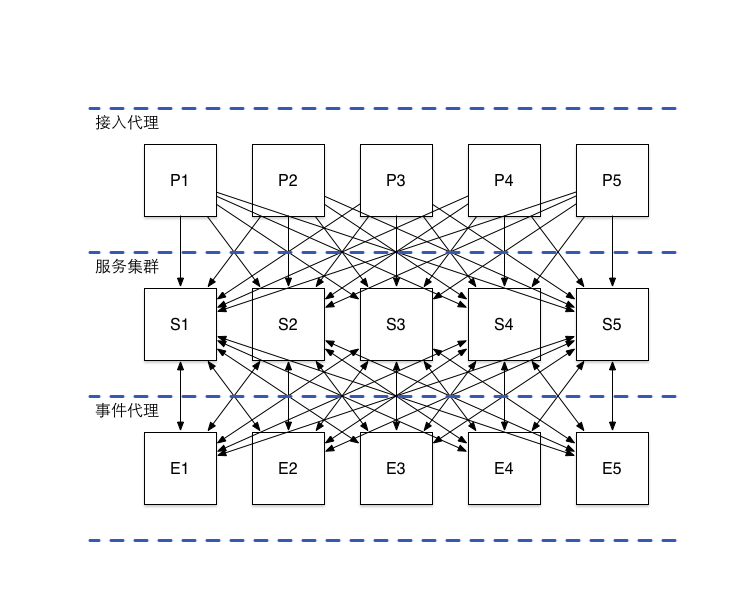
在这种方案中,接入代理层的每个实例都要维护所有服务实例的配置参数。当系统中的服务实例数量发生变化,或需要接入新的第三方实例时,需要同步修改所有的接入层实例。接入层不仅需要处理请求的负载均衡,还要实现对第三方服务的并发,服务实例的失效检测、重试等复杂的控制逻辑。
而在事件代理层,由于事件转发实际上是广播方式,同一个事件往往需要转发多次,在当前的方案中,如果采用同步方式,一个事件的处理时间,取决于所有接收方的的处理时间之和。如果采用异步方式,则取决于所有接收方的的处理时间的最大值,并且代理层的实现的复杂度会大大增加。
引入消息队列的方案
图:平台的通信模型(使用消息队列)

在这种方案中,引入了基于生产消费模型的消息队列后,天然具备了负载均衡能力。同时,队列中的消息是由服务实例自行拉取的,所以不论是接入层,还是消息队列,都不要关心服务实例的部署细节。服务实例也可以处行控制拉取消息的频率,实现并发控制。
但由于引入消息队列后,每一次的请求都不会被直接响应,这对于异步请求没有问题,但对于同步请求,处理起来就有些麻烦了。还好,在一些成熟的消息队列方案中,会提供request-reply模式,用于处理同步请求。这也是后我们进行技术选型的重要考虑因素。
而对于事件代理层,现在只需要把事件加入到队列中就万事大吉了。
当然了,实践中还有很多细节问题要处理,但整体上来说,不论是初期的实现成本,还是后续的维护成本,都要比不使用队列时的方案优化不少。
消息队列有哪些实现方案
消息队列的核心思想非常简单,就是一个生产消费队列,所以,即便是自己实现,成本也是可以接受的。而且,从面的可以看到,消息队列的设计基本上与具体业务没有什么关联。所以业界也早有很多成熟的实现方案可供选择,包括笔者所在的公司内部,也有一些消息队列方案可供选用。
基于成熟网络编程框架开发
由于消息队列的原理很简单,所以不免会有人跃跃欲试的想要自己实现。这当然是一个可以选的方案,但在笔者看来,这不应该是一个首选的方案。因为一个完备的消息队列需要考虑很多细节问题,在ØMQ的文档中就详细的列举了这些问题:
| How do we handle I/O? Does our application block, or do we handle I/O in the background? This is a key design decision. Blocking I/O creates architectures that do not scale well. But background I/O can be very hard to do right. |
- 这个问题是说系统采用同步IO,还是异步IO,同步IO代码逻辑简单、直观、易维护,但性能有限。异步IO性能好,但代码往往需要按特定的模式去书写,对于后期接手项目的人来说,学习和维护成本较高。
| How do we handle dynamic components, i.e., pieces that go away temporarily? Do we formally split components into “clients” and “servers” and mandate that servers cannot disappear? What then if we want to connect servers to servers? Do we try to reconnect every few seconds? |
- 这个问题说的是集群的可维护性和容错性,当集群的拓扑发生变生时,如何处理,某个模块临时下线了,相关联的模块如何容错并以最低的代价切换到其它的可用模块上,当故障模块恢复后,或有新增机器扩容后,又如何以最低的代价将新增结点加入拓扑中。
| How do we represent a message on the wire? How do we frame data so it’s easy to write and read, safe from buffer overflows, efficient for small messages, yet adequate for the very largest videos of dancing cats wearing party hats? |
- 这里的问题是如保设计数据串行化协议,要考虑读写效率、缓冲区溢出、短消息的效率、大消息的效率、流媒体传输等等,这里补充一个问题:是否需要兼性多种协议?
| How do we handle messages that we can’t deliver immediately? Particularly, if we’re waiting for a component to come back online? Do we discard messages, put them into a database, or into a memory queue? |
- 这个问题其实是针对像ØMQ这样的无持久化的消息队列而言的,因为没有持久化,所有的消息只能缓存在内存里,如果下游模块故障或处理速度过慢就会造成队列溢出,对于这种情况,是阻塞消息发送模块停止发送消息,直到下游恢复,还是直接丢充一部分消息,需要做出技术决策。ØMQ选择了前者。
| Where do we store message queues? What happens if the component reading from a queue is very slow and causes our queues to build up? What’s our strategy then? |
- 如果消息需要持久化,如何持久化?队列消费过慢时如何处理?
| How do we handle lost messages? Do we wait for fresh data, request a resend, or do we build some kind of reliability layer that ensures messages cannot be lost? What if that layer itself crashes? |
- 如保处理消息丢失的问题?系统可靠生与数据一致性问题,CAP原则,也是一个如何取舍的问题
| What if we need to use a different network transport. Say, multicast instead of TCP unicast? Or IPv6? Do we need to rewrite the applications, or is the transport abstracted in some layer? |
- 是否兼容多种传输层协议?TCP?UDP?IPC?UNIX SOCKET?
| How do we route messages? Can we send the same message to multiple peers? Can we send replies back to an original requester? |
- 如何处理消息路由,举个例子:假设,A模块通过MQ发布消息给B模块和C模块,B模块与C模块收到消息后,需要通过MQ向A模块发送确认消息。这时MQ需要能够自动的将B和C的应答消息转发给A,而不是其它模块。这个也是实现前面提到的request-reply模式的关健所在。
| How do we write an API for another language? Do we re-implement a wire-level protocol or do we repackage a library? If the former, how can we guarantee efficient and stable stacks? If the latter, how can we guarantee interoperability? |
- 如何封MQ自己的交互协议,为解决数据的一致性、消息路由等问题,MQ必然要有一个自己的接口交互逻辑,如错误重试、消息重发、地址封装等,这些逻辑的封装以何种方式提供?还是要每个接入的模块都自己实现?
| How do we represent data so that it can be read between different architectures? Do we enforce a particular encoding for data types? How far is this the job of the messaging system rather than a higher layer? |
- 与第三个问题类似,只是角度不同
| How do we handle network errors? Do we wait and retry, ignore them silently, or abort? |
- 如保处理各种网络异常
看完了这些问题,你是否仍然坚持要自己实现一个MQ呢?
基于ØMQ开发
ØMQ实际上是只是一个LIB,他对消息通信的模型进行了抽象和封装,覆盖了上面提到的大部分问题,可以说,基于ØMQ开发了一个MQ是件非常轻松的事情。而且ØMQ的文档如提供了大量的实例,这些本身已经满足大部分的应用场景。使用者可以利用ØMQ组合出一套最简也最易维护的消息队列系统,并按着业务需求进行有针对性的优化。ØMQ唯一缺失的特性就是持久化。
使用成熟的中间件
虽然用ØMQ开发一个MQ非常简单,但终究还是要开发,而实际上,很多时候,MQ都是与业务无关的,因此也就有了很多可以直接使用的中间件,只需部署好相应的环境就可以直接使用了。
ActiveMQ
重量级的老牌儿MQ,诞生自Java生态,功能完备,相关的介绍很多,这里不再赘述。
RabbitMQ
同样是老牌儿MQ,基于erlang实现,语言无关,功能完备,诞生自金融领域。
Kafka
MQ中的后起之秀,在很多场景下都超越了前辈,诞生自Hadoop生态,在大数据的支持方面,目前无人能出其右。
nmq
笔者公司内部的MQ,功能比较单一,但性能高,稳定性好。
选择哪个中间件?
到底应该哪个方案,还是要看具体的需求。在我们的设计中,MQ的功能与业务无关,因此优先考虑使用已有的中间件搭建。那么具本选择哪个中间件呢?先来梳理下我们对MQ的需求:
功能需求
如前文所述,除了最基本生产消费模型,还需要MQ能支持REQUEST-REPLY模型,以提供对同步调用的支持。 此外,如果MQ能提供PUBLISH-SUBSCRIBE模型,则事件代理的实现可以更加简单。
性能需求
考虑未来一到两年内产品的发展,消息队列的呑吐量预计不会超过 1W qps,但由单条消息延迟要求较高,希望尽量的短。
可用性需求
因为是在线服务,因此需要较高的可用性,但充许有少量消息丢失。
易用性需求
包括学习成本、初期的开发部署成本、日常的运维成本等。
横向对比
ActiveMQ与RabbitMQ在很多方面都很相似,但ActiveMQ对非JAVA生态的支持不及rabbitMQ, 加之精力有限,因此本文重点关注RabbitMQ。
| 特性 | ActiveMQ | RabbitMQ | Kafka | NMQ |
| PRODUCER-COMSUMER | 支持 | 支持 | 支持 | - |
| PUBLISH-SUBSCRIBE | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 不支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持,JAVA优先 | 语言无关 | 支持,JAVA优先 | C/C++ |
| 单机呑吐量 | 万级 | 万级 | 十万级 | 单机万级 |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
注: - 表示尚未查找到准确数据
从上表中可以很明显的看到,最后的决择就是在rabbitmq与kafka之间了。考虑前面需求,系统的吞吐量不是特别大,但希望延时尽量的小,而且我们的系统会基于Python和PHP构建。因此综合上述结果,RabbitMQ最终胜出。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)