Storm 的流量控制和多线程并发处理
面临问题:storm多线程的时候,会遇到并发修改的问题,会报concurrentModificationException,如下图所示 解决方法:第一种治标不治本的方法:一方面,对发送到kafka的数据进行控制,将线程sleep的时间变长if(count==18000){try {Threa
·
- 面临问题:
storm多线程的时候,会遇到并发修改的问题,会报concurrentModificationException,如下图所示
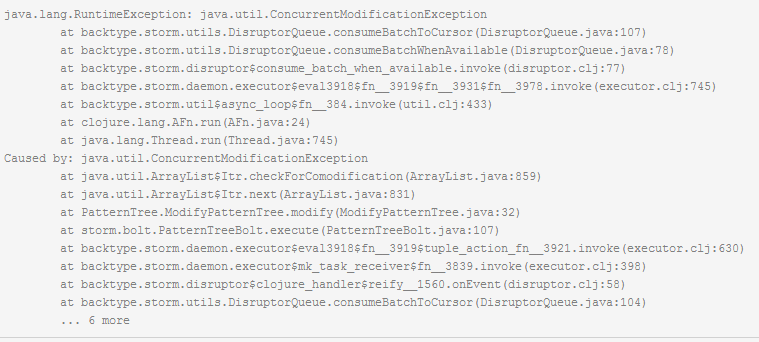
- 解决方法:
- 第一种治标不治本的方法:
一方面,对发送到kafka的数据进行控制,将线程sleep的时间变长
if(count==18000)
{
try {
Thread.sleep(1000);
time++;
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
count=0;
}另一方面,可以从处理的线程入手,即不允许并发修改(单线程不会报这种错误);
可以将线程数设低,控制比较快的处理,即前一部分的数据处理过快,导致后面数据处理成为瓶颈,也就是要找到一个平衡点。
- 第二种网络上的其他人写的方法(试过,都不管用):
1.hasNext()是不会抛出ConcurrentModificationException的,将next()换成hasNext(),但是还是会用到next()对ArrayList进行遍历
2.使用并发容器CopyOnWriteArrayList代替ArrayList
下面是原先代码。
public static void modify(ArrayList<frequent> afr, double count,String time, PatternTree tree)
{
for (frequent fr : afr)
{
ArrayList<String> item = fr.getItem();
double value = fr.getCount();
}
}做了如下修改
public static void modify(List<frequent> afr, double count,String time, PatternTree tree)
{
for(Iterator it = afr.iterator(); it.hasNext();)
{
List<String> item=new CopyOnWriteArrayList<String>();
item = ((frequent) it.next()).getItem();
double value = ((frequent) it.next()).getCount();
}
}最终还是报这个错,不管是修改遍历方法,还是换成CopyOnWriteArrayList,当一个线程执行modify方法的时候,另一个线程修改了modify中的afr,就会抛出ConcurrentModificationException。
- 最终方案
将ConcurrentModificationException的异常catch住,这样导致了发送数据会fail掉,storm有出错重发的机制,所以会不断重发,拖慢了处理速度,在后面的博客中,我会介绍storm的Qos的方法,减少fail的数据,加快处理的速度。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)