ELK 7.16 + Filebeat+ Kafka搭建日志系统
ELK 7.16 + Filebeat+ Kafka搭建日志集群
ELK 7.16 + Filebeat+ Kafka搭建日志集群
ELK 是 elastic 公司研发的一套完整的日志收集、 分析和展示的企业级解决方案。接下来以二进制安装的方式部署一套ELK集群。
一、系统环境
在elk1、elk2、elk3三台主机上分别部署Zookeeper、Kafka、Elasticsearch集群,在应用程序运行的服务器上安装filebeat收集日志,并传输到kafka,再由Logstash从kafka中消费topic传输到Elasticsearch。此为测试集群,服务器配置较低,如生产环境,建议zookeeper和kafka与ES分开单独服务器集群部署,logstash可根据需求配置一台或者多台,
| 主机IP | 主机名 | 组件 |
|---|---|---|
| 192.168.5.84 | elk1 | zookeeper、kafka、elasticsearch、kibana |
| 192.168.5.85 | elk1 | zookeeper、kafka、elasticsearch、logstash |
| 192.168.5.86 | elk1 | zookeeper、kafka、elasticsearch |
二、基础配置
最小化安装操作系统,配置主机名,关闭防火墙,禁用SELinux,配置本地域名解析,配置时间同步
systemctl stop firewalld; systemctl disable firewalld; systemctl mask firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config && setenforce 0
sed -i '/swap/s/^[^#]/#&/' /etc/fstab
hostnamectl --static set-hostname elk1; exec bash
hostnamectl --static set-hostname elk2; exec bash
hostnamectl --static set-hostname elk3; exec bash
配置hosts解析
cat /etc/hosts
192.168.5.84 elk1
192.168.5.85 elk2
192.168.5.86 elk3
配置时间同步
yum install chrony -y # apt -y install chrony
vim /etc/chrony.conf
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
systemctl enable chronyd.service; systemctl restart chronyd.service
chronyc sources -v #说明:^* #已同步
配置java环境
下载java11安装包,安装java 11环境
https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html
vim java11-install.sh
#!/bin/bash
JAVA_APP=jdk-11.0.12_linux-x64_bin.tar.gz
JAVA_DIR=jdk-11.0.12
tar -zxf ${JAVA_APP} -C /usr/local/src/
ln -sv /usr/local/src/${JAVA_DIR} /usr/local/jdk
ln -sv /usr/local/jdk/bin/java /usr/bin/
cat >> /etc/profile <<EOF
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=\$JAVA_HOME/jre
export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar:\$JRE_HOME/lib
export PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin
EOF
. /etc/profile
java -version
添加可执行权限,运行安装java11
chmod +x java11-install.sh
./java11-install.sh
java version "11.0.12" 2021-07-20 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.12+8-LTS-237)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.12+8-LTS-237, mixed mode)
三、安装配置Zookeeper和Kafka集群
从Apache官网下载zookeeper和kafka的二进制压缩包。https://archive.apache.org/dist/
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
wget https://archive.apache.org/dist/kafka/2.8.1/kafka_2.13-2.8.1.tgz
解压的到指定目录下,并创建对应的软连接
tar -zxf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/src/
tar -zxf kafka_2.13-2.8.1.tgz -C /usr/local/src/
ln -sv /usr/local/src/apache-zookeeper-3.7.0-bin /usr/local/zookeeper
ln -sv /usr/local/src/kafka_2.13-2.8.1 /usr/local/kafka
安装配置zookeeper集群
cd /usr/local/zookeeper/conf/; cp zoo_sample.cfg zoo.cfg
zookeeper关键参数配置
grep -v "#" zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=192.168.5.84:2888:3888
server.2=192.168.5.85:2888:3888
server.3=192.168.5.86:2888:3888
mkdir -p /data/zookeeper
创建节点myid文件
echo 1 > /data/zookeeper/myid #在节点elk1上配置
echo 2 > /data/zookeeper/myid #在节点elk2上配置
echo 3 > /data/zookeeper/myid #在节点elk3上配置
在各节点启动zookeeper,并查看状态
nohup /usr/local/zookeeper/bin/zkServer.sh start >> /data/zookeeper/zookeeper.log 2>&1 &
查看zookeeper启动日志
tail -f /data/zookeeper/zookeeper.log
查看zookeeper的状态
节点1的Mode: follower
/usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
节点2的Mode: follower
/usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
节点3的Mode: leader
/usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
创建systemd服务
cat /usr/lib/systemd/system/zookeeper.service
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=simple
Environment=PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/local/jdk/bin:/usr/local/jdk/jre/bin
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
PIDFile=/data/zookeeper/zookeeper_server.pid
Restart=on-failure
[Install]
WantedBy=multi-user.target
重新加载并启动
systemctl daemon-reload
systemctl enable zookeeper.service; systemctl start zookeeper.service
systemctl status zookeeper.service -l # -l显示详细信息
● zookeeper.service
Loaded: loaded (/usr/lib/systemd/system/zookeeper.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2022-04-21 11:14:45 CST; 5min ago
Main PID: 919 (java)
CGroup: /system.slice/zookeeper.service
└─919 java -Dzookeeper.log.dir=/usr/local/zookeeper/bin/....
Apr 21 11:14:45 zk1 systemd[1]: Started zookeeper.service.
Apr 21 11:14:45 zk1 zkServer.sh[851]: /usr/bin/java
Apr 21 11:14:45 zk1 zkServer.sh[851]: ZooKeeper JMX enabled by default
Apr 21 11:14:45 zk1 zkServer.sh[851]: Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Apr 21 11:14:46 zk1 zkServer.sh[851]: Starting zookeeper ... STARTED
安装配置kafka集群
cd /usr/local/kafka/config/; cp server.properties server.properties.bak
grep -v "#" server.properties
broker.id=1 #elk2、elk3修改为对应的id
listeners=PLAINTEXT://192.168.5.84:9092 #elk2、elk3修改为对应的ip
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka-logs
num.partitions=3 #设置topic 默认分区数量,一般和节点数量保持一致
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.5.84:2181,192.168.5.85:2181,192.168.5.86:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
mkdir -p /data/kafka-logs #创建kakfa数据目录
在各节点启动kafka
nohup /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties >> /data/kafka-logs/output.log 2>&1 &
查看启动日志
tail -f /data/kafka-logs/output.log
创建systemd服务
cat /usr/lib/systemd/system/kafka.service
[Unit]
Description=kafka.service
After=network.target zookeeper.service
[Service]
Type=simple
Environment=PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/local/jdk/bin:/usr/local/jdk/jre/bin
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
重新加载并启动
systemctl daemon-reload
systemctl enable kafka.service; systemctl start kafka.service
systemctl status kafka.service
systemctl status kafka.service -l
● kafka.service
Loaded: loaded (/usr/lib/systemd/system/kafka.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2022-04-21 11:16:41 CST; 4min 12s ago
Main PID: 2386 (java)
CGroup: /system.slice/kafka.service
└─2386 java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20
Apr 21 11:17:59 zk2 kafka-server-start.sh[848]: [2022-04-21 11:17:59,786] INFO Kafka version: 2.8.1 (org.apache.kafka.common.utils.AppInfoParser)
Apr 21 11:17:59 zk2 kafka-server-start.sh[848]: [2022-04-21 11:17:59,786] INFO Kafka commitId: 839b886f9b732b15 (org.apache.kafka.common.utils.AppInfoParser)
Apr 21 11:17:59 zk2 kafka-server-start.sh[848]: [2022-04-21 11:17:59,786] INFO Kafka startTimeMs: 1650511078612 (org.apache.kafka.common.utils.AppInfoParser)
Apr 21 11:17:59 zk2 kafka-server-start.sh[848]: [2022-04-21 11:17:59,792] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
Apr 21 11:18:01 zk2 kafka-server-start.sh[848]: [2022-04-21 11:18:01,494] INFO [broker-2-to-controller-send-thread]:
安装kafka-manager查看top信息,https://github.com/yahoo/CMAK/releases
在elk2上安装kafka-manager
cd /usr/local/src
wget https://github.com/yahoo/CMAK/releases/download/3.0.0.5/cmak-3.0.0.5.zip
unzip cmak-3.0.0.5.zip
ln -sv /usr/local/src/cmak-3.0.0.5 /usr/local/cmak
修改配置文件
cd /usr/local/cmak/conf/
vim application.conf
kafka-manager.zkhosts=${?ZK_HOSTS}
#cmak.zkhosts="kafka-manager-zookeeper:2181"
cmak.zkhosts="192.168.5.84:2181,192.168.5.85:2181,192.168.5.86:2181"
cmak.zkhosts=${?ZK_HOSTS}
后台启动,设置端口为9000
nohup /usr/local/elk/cmak/bin/cmak -Dconfig.file=/usr/local/elk/cmak/conf/application.conf -Dhttp.port=9000 >> /usr/local/elk/cmak/output.log 2>&1 &
查看启动日志
tail -f /usr/local/elk/cmak/output.log
启动成功后浏览器访问http://192.168.5.85:9000/,点击Cluster下拉列表中选择添加集群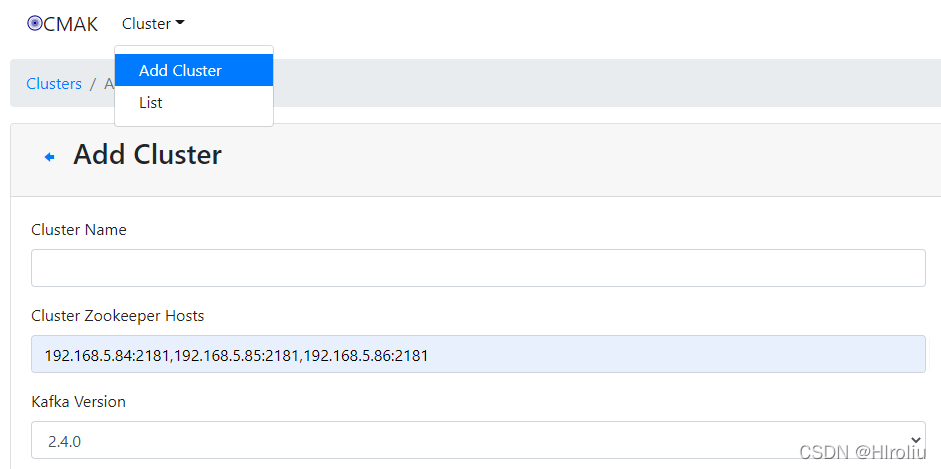
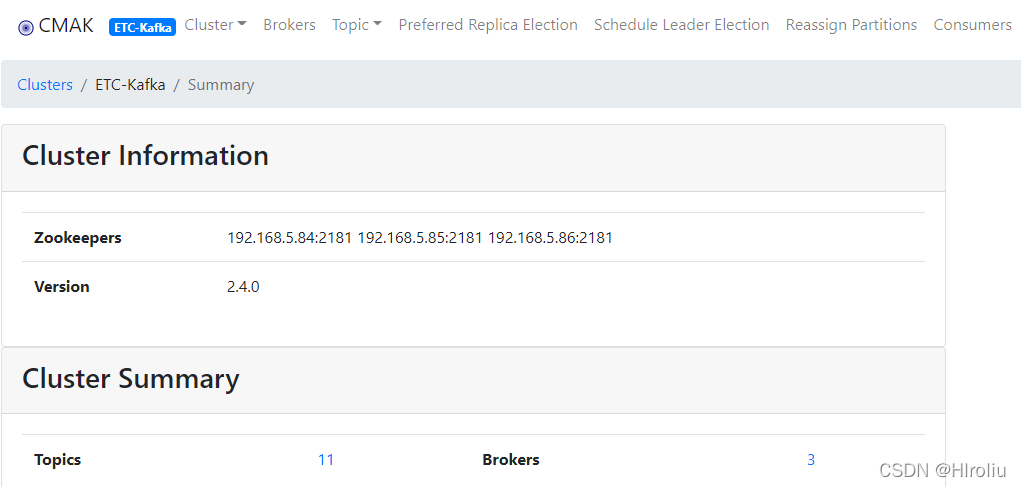
四、安装Elasticsearch集群
修改系统参数
vim /etc/security/limits.conf
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* soft memlock unlimited
* hard memlock unlimited
vim /etc/sysctl.conf
vm.max_map_count=655360
fs.file-max=655360
sysctl -p
从Elastic官网下载对应的软件包https://www.elastic.co/cn/downloads/past-releases#elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.2-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.2-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.2-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.2-linux-x86_64.tar.gz
tar -zxf elasticsearch-7.16.2-linux-x86_64.tar.gz -C /usr/local/src/
tar -zxf kibana-7.16.2-linux-x86_64.tar.gz -C /usr/local/src/
tar -zxf logstash-7.16.2-linux-x86_64.tar.gz -C /usr/local/src/
mkdir /usr/local/elk
ln -sv /usr/local/src/elasticsearch-7.16.2-linux-x86_64 /usr/local/elk/elasticsearch
‘/usr/local/elk/elasticsearch’ -> ‘/usr/local/src/elasticsearch-7.16.2-linux-x86_64’
因elastisearch拒绝以root启动服务,因此需要创建用户以及修改目录权限,确保用户有权限访问目录
创建elk用户,并配置目录权限
useradd elk
chown -R elk:elk /usr/local/elk
chown -R elk:elk /usr/local/src/elasticsearch-7.16.2
mkdir -p /data/elk/es-data /data/elk/es-logs
chown -R elk:elk /data/elk
以elk用户配置elasticsearch并启动
su - elk
修改jvm参数
vim /usr/local/elk/elasticsearch/config/jvm.options #修改成合适的内存,官方建议不要超过32G
31 #-Xms6g
32 #-Xmx6g
修改启动时的java环境,默认是调用elasticsearch安装目录下的openjdk
/usr/local/elk/elasticsearch/jdk/bin/java -version
openjdk version "17.0.1" 2021-10-19
OpenJDK Runtime Environment Temurin-17.0.1+12 (build 17.0.1+12)
OpenJDK 64-Bit Server VM Temurin-17.0.1+12 (build 17.0.1+12, mixed mode, sharing)
修改为自己安装的java11
cat /usr/local/elk/elasticsearch/bin/elasticsearch-env
39 ES_JAVA_HOME=/usr/local/jdk #增加一行配置,指定ES_JAVA_HOME的路径
40 if [ ! -z "$ES_JAVA_HOME" ]; then
41 JAVA="$ES_JAVA_HOME/bin/java"
42 JAVA_TYPE="ES_JAVA_HOME"
43 elif [ ! -z "$JAVA_HOME" ]; then
44 # fallback to JAVA_HOME
45 echo "warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME" >&2
46 JAVA="$JAVA_HOME/bin/java"
47 JAVA_TYPE="JAVA_HOME"
配置elasticsearch集群参数
cd /usr/local/elk/elasticsearch/config/; cp elasticsearch.yml elasticsearch.yml.bak
grep -v "#" elasticsearch.yml
cluster.name: ELK-Test
node.name: node-1 #elk2、elk3配置对应的node.name
path.data: /data/elk/es-data
path.logs: /data/elk/es-logs
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["192.168.5.84", "192.168.5.85", "192.168.5.86"]
cluster.initial_master_nodes: ["192.168.5.84", "192.168.5.85", "192.168.5.86"]
action.destructive_requires_name: true
cd /usr/local/elk/elasticsearch/
nohup /usr/local/elk/elasticsearch/bin/elasticsearch >> /usr/local/elk/elasticsearch/output.log 2>&1 &
查看启动日志
tail -f /usr/local/elk/elasticsearch/output.log
查看ES集群状态http://192.168.5.84:9200/_cluster/health?pretty,
curl http://192.168.5.84:9200/_cluster/health?pretty
{
"cluster_name" : "ELK-Test",
"status" : "green", #集群状态为green
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 91,
"active_shards" : 182,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
配置ES集群可视化工具cerebro
Cerebro 是查看分片分配和最有用的界面之一通过图形界面执行常见的索引操作。 完全开放源,并且它允许您添加用户,密码或 LDAP 身份验证问网络界面。Cerebro 是对先前插件的部分重写,并且可以作为自运行工具使用应用程序服务器,基于 Scala 的Play 框架。Cerebro 是一种现代反应性应用程序; 它使用 Scala 使用 Play 框架在 Scala 中编写,用于后端 REST 和 Elasticsearch 通信。 此外,它使用通过 AngularJS 用JavaScript 编写的单页应用程序(SPA)前端。https://github.com/lmenezes/cerebro
在elk2上安装cerebro
cd /usr/local/src
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tgz
tar -xf cerebro-0.9.4.tgz
ln -sv /usr/local/src/cerebro-0.9.4 /usr/local/cerebro
cat /usr/local/cerebro/conf/application.conf
修改配置,一个host就是一个es集群,可配置多个elk集群
hosts = [
{
host = "http://192.168.5.84:9200"
name = "ELK-Test"
}
#{
# host = "http://xxx.xxx.xxx:9200"
# name = "ELK-Cluster2"
#}
]
nohup /usr/local/elk/cerebro-0.9.4/bin/cerebro -Dhttp.port=9090 -Dhttp.address=0.0.0.0
浏览器访问http://192.168.5.85:9090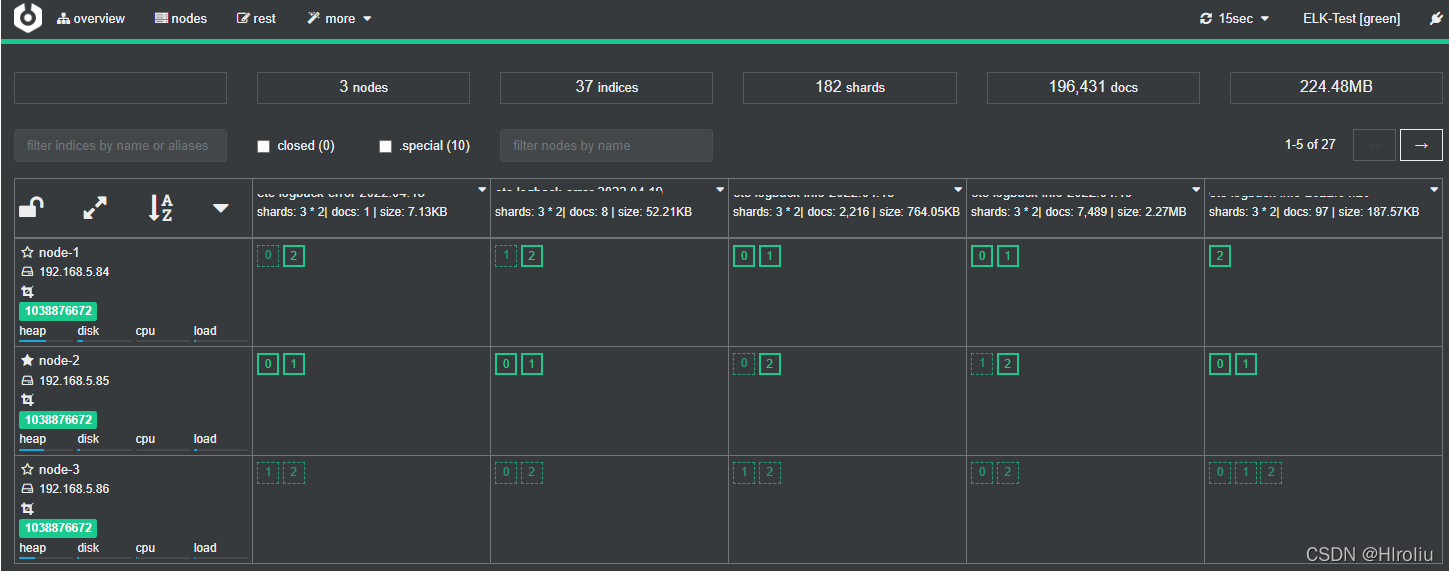
配置elasticsearch索引副本和分片数
elasticsearch索引副本和分片数的设置需要在索引生成之前,即集群部署完成后设置
1、相同分片的副本不会放在同一个节点。比如这个分片有两个副本,这两个副本不可以在同一个节点。
2、ES禁止同一个分片的主分片和副本分片在同一个节点。比如单节点ES,不允许有副本分片,有副本分片,则集群不健康。
number_of_shards每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。
number_of_replicas每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
设置索引副本数为1,分片为3。一般情况下:集群所有索引的副本最大值+1 <= 集群节点数量 <= 分片数量
curl -X PUT 192.168.5.86:9200/_template/log -H 'Content-Type: application/json' -d '{
"template": "*",
"settings": {
"number_of_shards": 3,
"number_of_replicas": "1"
}
}'
curl -X PUT 192.168.5.85:9200/_template/log -H 'Content-Type: application/json' -d '{
"template": "*",
"settings": {
"number_of_shards": 3,
"number_of_replicas": "1"
}
}'
curl -X PUT 192.168.5.84:9200/_template/log -H 'Content-Type: application/json' -d '{
"template": "*",
"settings": {
"number_of_shards": 3,
"number_of_replicas": "1"
}
}'
配置systemd服务
cat /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=https://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=ES_JAVA_HOME=/usr/local/jdk
Environment=ES_HOME=/usr/local/elk/elasticsearch
Environment=PID_DIR=/usr/local/elk/elasticsearch
User=elk
Group=elk
ExecStart=/usr/local/elk/elasticsearch/bin/elasticsearch
StandardOutput=journal
StandardError=inherit
LimitNOFILE=65535
LimitNPROC=4096
LimitAS=infinity
LimitFSIZE=infinity
TimeoutStopSec=0
KillSignal=SIGTERM
KillMode=process
SendSIGKILL=no
SuccessExitStatus=143
TimeoutStartSec=75
[Install]
WantedBy=multi-user.target
重新加载并启动
systemctl daemon-reload
systemctl enable elasticsearch.service; systemctl start elasticsearch.service
systemctl status elasticsearch.service -l
● elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2022-04-19 10:54:45 CST; 23h ago
Docs: https://www.elastic.co
Main PID: 90574 (java)
CGroup: /system.slice/elasticsearch.service
├─90574 /usr/local/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 .....
└─90747 /usr/local/elk/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controller
Apr 19 10:55:05 elk3 elasticsearch[90574]: [2022-04-19T10:55:05,831][INFO ][o.e.n.Node ] [node-3] started
五、安装Kibana
以elk用户身份在elk1上安装配置kibana,生产环境可配置多台kibana,通过nginx/haproxy实现反向代理
tar -zxf kibana-7.16.2-linux-x86_64.tar.gz -C /usr/local/src/
tar -zxf logstash-7.16.2-linux-x86_64.tar.gz -C /usr/local/src/
mkdir /usr/local/elk
ln -sv /usr/local/elk/src/kibana-7.16.2-linux-x86_64 /usr/local/elk/kibana
修改配置文件
cd /usr/local/elk/kibana/config/; cp kibana.yml kibana.yml.bak
grep -v "#" kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.5.84:9200","http://192.168.5.85:9200","http://192.168.5.86:9200"]
i18n.locale: "zh-CN" #配置为支持中文,在最后一行
nohup /usr/local/elk/kibana/bin/kibana >> /usr/local/elk/kibana/output.log 2>&1 &
配置systemd服务
cat /lib/systemd/system/kibana.service
[Unit]
Description=Kibana
Documentation=https://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=elk
Group=elk
Environment=KBN_HOME=/usr/local/elk/kibana
Environment=KBN_PATH_CONF=/usr/local/elk/kibana/config
chroot="/usr/local/elk/kibana"
chdir="/usr/local/elk/kibana"
nice=""
ExecStart=/usr/local/elk/kibana/bin/kibana --logging.dest="/usr/local/elk/kibana/kibana.log" --pid.file="/usr/local/elk/kibana/kibana.pid"
Restart=on-failure
RestartSec=3
StartLimitBurst=3
StartLimitInterval=60
WorkingDirectory=/usr/local/elk/kibana
StandardOutput=journal
StandardError=inherit
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable kibana.service; systemctl start kibana.service
systemctl status kibana.service
浏览器访问http://192.168.5.84:5601
六、配置filebeat收集日志
在应用服务器上安装filebeat收集日志并传输至kafka
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.2-x86_64.rpm
yum -y localinstall filebeat-7.16.2-x86_64.rpm
配置filebeat收集应用日志,并输出至kafka
cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/xxx/logs/xxxx1.*.log #应用日志文件路径1
fields:
logtopic: "xxxx1-info"
host_ip: "192.168.5.53"
fields_under_root: true
encoding: utf-8
- type: log
enabled: true
paths:
- /home/xxx/logs/xxx2.*.log #应用日志文件路径2
fields:
logtopic: "xxx2-info"
host_ip: "192.168.5.53"
fields_under_root: true
encoding: utf-8
- type: log
enabled: true
paths:
- /var/log/messages*
fields:
logtopic: "messages"
host_ip: "192.168.5.53"
fields_under_root: true
encoding: utf-8
- type: log
enabled: true
paths:
- /var/log/secure*
fields:
logtopic: "secure"
host_ip: "192.168.5.53"
fields_under_root: true
encoding: utf-8
output.kafka:
hosts: ["192.168.5.84:9092","192.168.5.85:9092","192.168.5.86:9092"]
topic: '%{[logtopic]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
code.format:
string: '%{[message]} %{[logtopic]} %{@timestamp}' #只输出需要的字段信息
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
processors:
- drop_fields:
fields: ["log","input","agent","ecs","_score","_type","host"]
#注释不必要的元数据信息
#setup.kibana:
## host: "192.168.5.84:5601"
#
##processors:
### - add_host_metadata:
### when.not.contains.tags: forwarded
### - add_cloud_metadata: ~
### - add_docker_metadata: ~
### - add_kubernetes_metadata: ~
启动filebeat并在kafka-manager上查看生成的topic
systemctl daemon-reload
systemctl enable filebeat.service; systemctl start filebeat.service
systemctl status filebeat.service -l
● filebeat.service - Filebeat sends log files to Logstash or directly to Elasticsearch.
Loaded: loaded (/usr/lib/systemd/system/filebeat.service; disabled; vendor preset: disabled)
Active: active (running) since 三 2022-04-20 11:41:54 CST; 2s ago
Docs: https://www.elastic.co/beats/filebeat
Main PID: 23283 (filebeat)
CGroup: /system.slice/filebeat.service
└─23283 /usr/share/filebeat/bin/filebeat --environment systemd -c /etc/filebeat/filebeat.yml ....
浏览器访问kafka-manager验证topic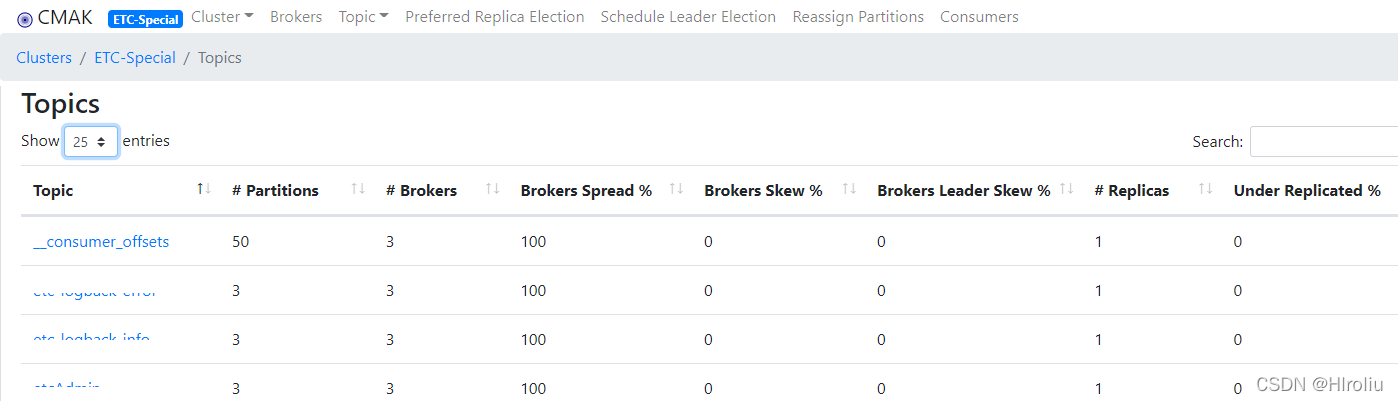
七、配置logstash
logstash从kafka消费/取出日志,并对数据做一些格式化操作,然后传入ES集群。以elk用户身份操作
修改logstash使用的java环境,默认是使用安装包目录下的openjdk。
/usr/local/elk/logstash/jdk/bin/java -version
openjdk version "11.0.13" 2021-10-19
OpenJDK Runtime Environment Temurin-11.0.13+8 (build 11.0.13+8)
OpenJDK 64-Bit Server VM Temurin-11.0.13+8 (build 11.0.13+8, mixed mode)
编辑安装包bin目录下的logstash.lib.sh文件,指定java
vim logstash/bin/logstash.lib.sh
# 在setup_java()行上面添加以下两行配置
89 export JAVACMD="/usr/local/jdk/bin/java"
90 export LS_JAVA_HOME="/usr/local/jdk"
91 setup_java() {
92 # set the path to java into JAVACMD which will be picked up by JRuby to launch itself
93 if [ -z "$JAVACMD" ]; then
程序的日志格式内容如下
原始日志信息如下
2022-04-19 17:37:32.200[http-xxxx] INFO com.aop.LogRecordAspect - 请求开始===地址:http://localhost:xxxx/xxxxxxx/xxxxxxxx
2022-04-19 17:37:32.200[http-xxxx] INFO com.aop.LogRecordAspect - 请求开始===类型:POST
2022-04-19 17:37:32.200[http-xxxx] INFO com.aop.LogRecordAspect - 请求开始===参数:{........}
2022-04-19 17:37:32.202[http-xxxx] INFO com.aop.LogRecordAspect - 请求结束===返回值:{"MessageCode":"091","RequestTime":"2022-04-19 17:37::31.807","ExecuteCode":1,"ResponeTime":"2022-04-19 17:37:32"}
logstash配置文件的目录
vim /usr/local/elk/logstash/config/pipelines.yml
- pipeline.id: main
path.config: "/usr/local/elk/logstash/config/conf.d/*.conf"
mkdir -p /usr/local/elk/logstash/config/conf.d
配置logstash从kafka取出日志并输出到控制台
cd /usr/local/elk/logstash/config/conf.d
cat logstash.conf
input {
kafka {
bootstrap_servers => ["192.168.5.84:9092,192.168.5.85:9092,192.168.5.86:9092"]
topics => "xxxx1-info"
type => "xxxx1-info"
group_id => "xxxx1-info" #当从kafka集群中消费topic时,需要配置group_id和client_id区分
client_id => "xxxx1-info"
decorate_events => "basic"
auto_offset_reset => "earliest"
codec => "json"
}
}
output {
stdout {} # 标准输出
}
/usr/local/elk/logstash/bin/logstash -f /usr/local/elk/logstash/config/logstash.conf -t #检验配置文件
[2022-04-19T18:16:00,725][INFO ][org.reflections.Reflections] Reflections took 97 ms to scan 1 urls, producing 119 keys and 417 values
Configuration OK
启动logstash查看输出到控制台
/usr/local/elk/logstash/bin/logstash -f /usr/local/elk/logstash/config/logstash.conf
验证无误后,修改logstash.conf把日志输出到elasticsearch
output {
if [type] == "xxxx1-info" {
elasticsearch {
action => "index"
hosts => ["192.168.5.84:9200","192.168.5.85:9200","192.168.5.86:9200"]
index => "xxxx1-info-%{+YYYY.MM.dd}" # 创建的索引不能有大写字母,不然会报错
}
}
if [type] == "xxx2-info" {
elasticsearch {
action => "index"
hosts => ["192.168.5.84:9200","192.168.5.85:9200","192.168.5.86:9200"]
index => "xxx2-info-%{+YYYY.MM.dd}"
}
}
}
在kibana上创建索引后查看,日志的时间与@timestamp不一致,@timestamp是logstash取出日志的时间,从kafka消费数据时是无序的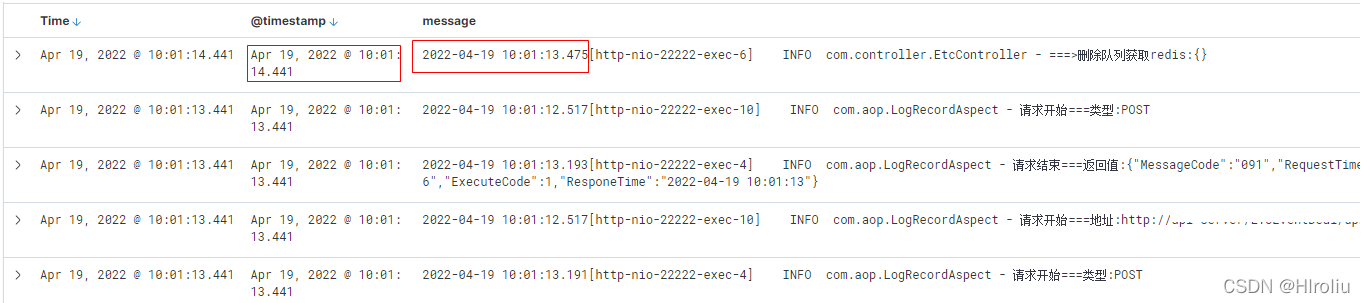
通过filter过滤器,把message中的时间覆盖掉@timestamp;修改logstash.conf,增加filter配置
input { ... }
filter {
grok {
match => ["message","(?<logtime>%{TIMESTAMP_ISO8601})" ] #获取message中的时间
}
date {
match => [ "logtime","YYYY-MM-dd HH:mm:ss.SSS" ] #匹配message中的日期格式,“2022-04-19 17:48:24.798[http....”
target => "@timestamp"
}
mutate {
remove_field => ["@version","logtopic","logtime"] #删除不必要的字段
}
}
output { ... }
登录kibana创建索引后查看,message中的时间与@timestamp一致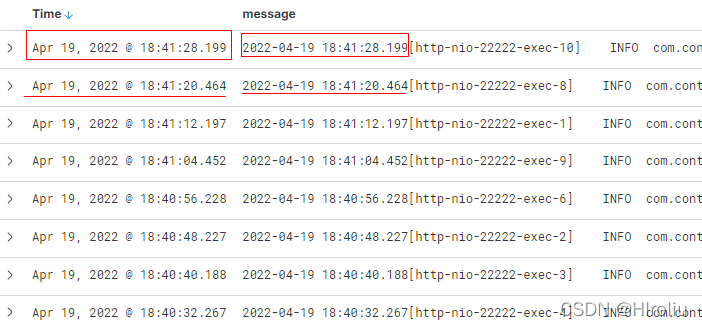
配置systemd服务
cat /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
Type=simple
User=elk
Group=elk
Environment=LS_HOME="/usr/local/elk/logstash"
Environment=LS_SETTINGS_DIR="/usr/local/elk/logstash/config"
Environment=LS_PIDFILE="/usr/local/elk/logstash/logstash.pid"
Environment=LS_GC_LOG_FILE="/usr/local/elk/logstash/gc.log"
Environment=LS_OPEN_FILES="16384"
LS_NICE="19"
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
ExecStart=/usr/local/elk/logstash/bin/logstash "--path.settings" "/usr/local/elk/logstash/config"
Restart=always
WorkingDirectory=/usr/local/elk/logstash
Nice=19
LimitNOFILE=16384
TimeoutStopSec=infinity
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable logstash.service; systemctl start logstash.service
systemctl status logstash.service -l
● logstash.service - logstash
Loaded: loaded (/usr/lib/systemd/system/logstash.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2022-04-20 09:54:50 CST; 19min ago
Main PID: 10674 (java)
CGroup: /system.slice/logstash.service
└─10674 /usr/local/jdk/bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC.....
八、Kibana上配置索引生命周期
一般情况下我们会要求删除过期索引,这个可以直接在kibana中实现。在左上角下拉菜单栏中选择Management模块下的Stack Management,选择索引生命周期管理。Kibana已经内置了很多策略,如不满足需求,可编辑现有的策略并另存为自定义策略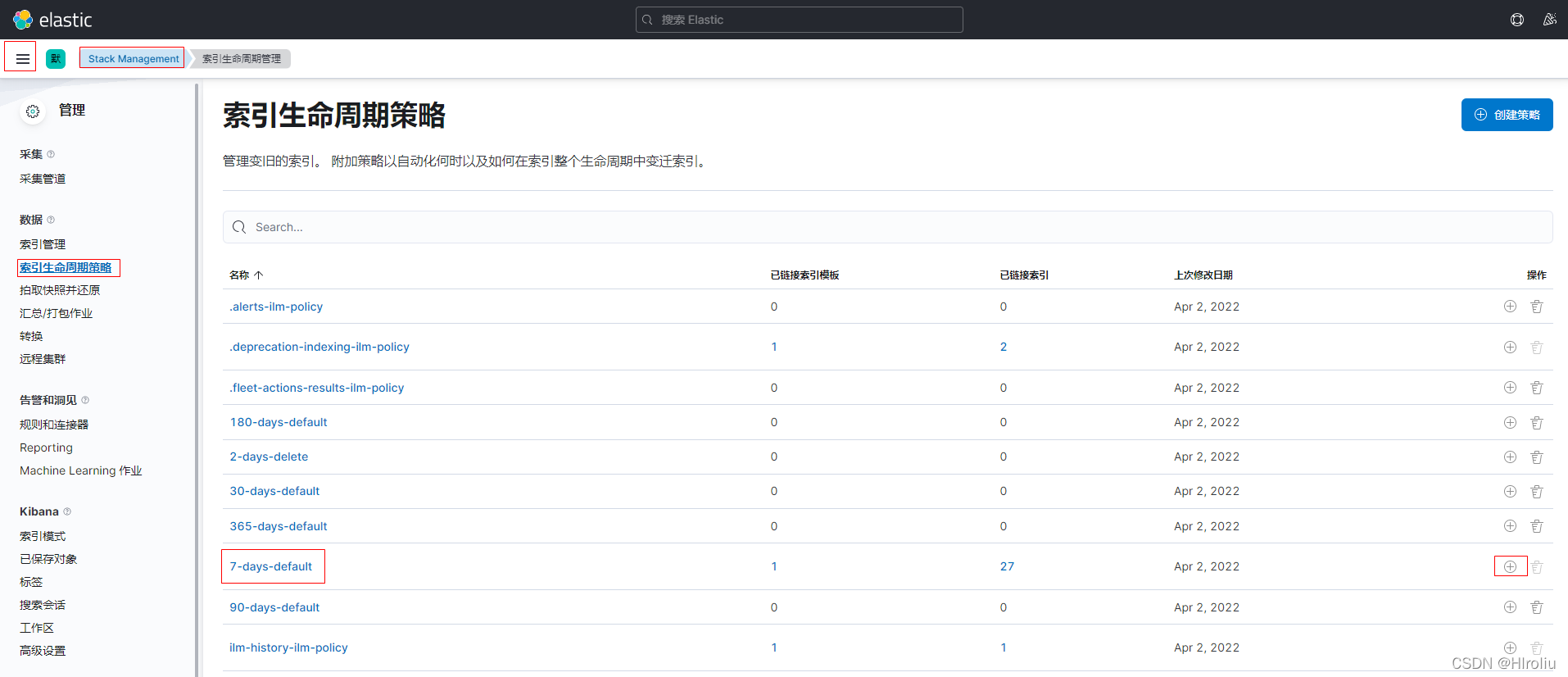
右侧的加号,可以将策略添加到索引模板,默认有一个log的索引模板可以匹配所有的索引。在这之后创建的索引都会添加上这个策略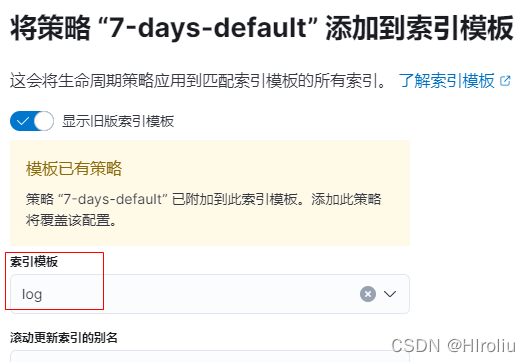
再回到索引管理界面,删除更改前创建的索引,查看新生成的索引详细信息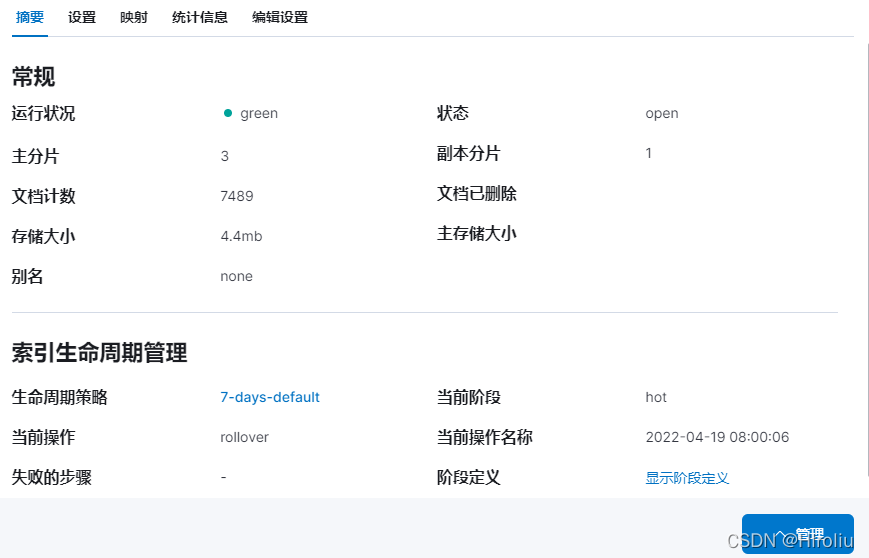
查看对应的索引模板,索引管理==>索引模板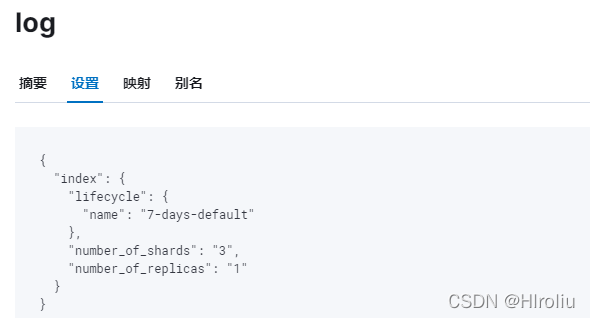

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)