kafka Consumer均衡算法,partition的个数和消费组组员个数的关系
kafka的Consumer均衡算法有一个topic:lijietest,然后这个topic的partition和他们所在的broker的图如下:1.其中 broker有两个,也就是服务器有两台。2.partition有6个,分布按照如图所示,按照哈希取模的算法分配。3.消费者有8个,他们属于同一个消费组。如果按照如图所示,那么这一个消费组中的消费者
kafka的Consumer均衡算法
有一个topic:lijietest,然后这个topic的partition和他们所在的broker的图如下:
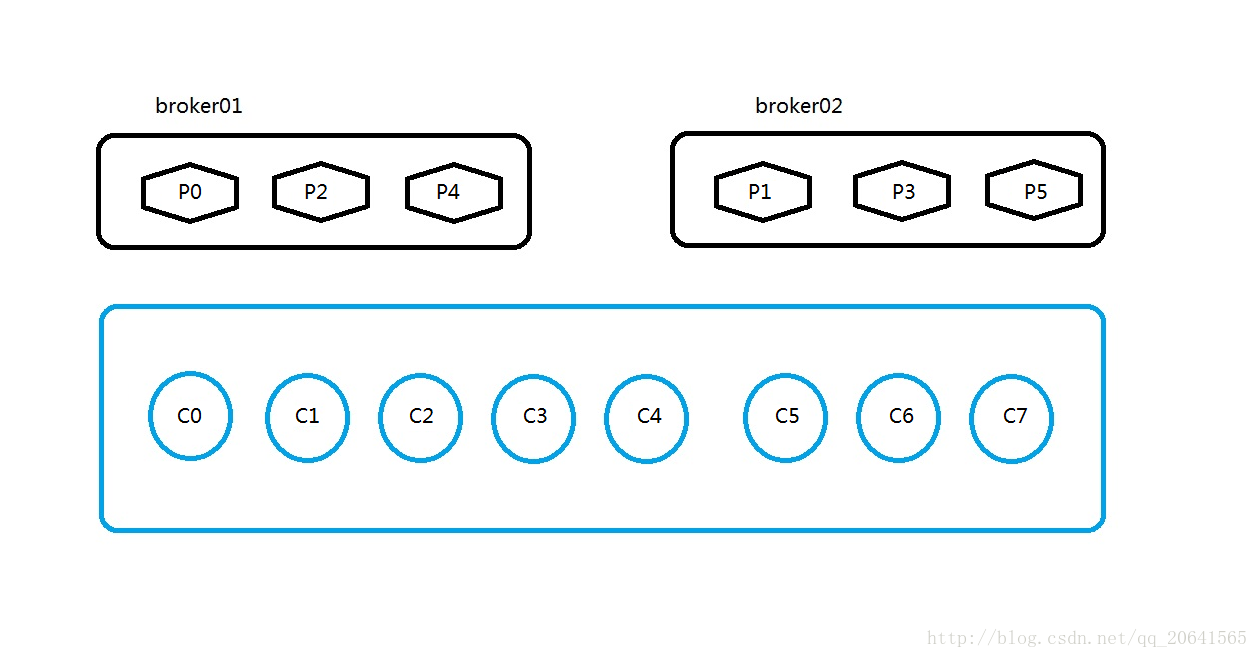
1.其中 broker有两个,也就是服务器有两台。
2.partition有6个,分布按照如图所示,按照哈希取模的算法分配。
3.消费者有8个,他们属于同一个消费组。
如果按照如图所示,那么这一个消费组中的消费者会怎么取kafka的数据呢?
其实kafka的消费端有一个均衡算法,算法如下:
1.A=(partition数量/同分组消费者总个数)
2.M=对上面所得到的A值小数点第一位向上取整
3.计算出该消费者拉取数据的patition合集:Ci = [P(M*i ),P((i + 1) * M -1)]
按照如图所示,那么这里:
A=6/8=0.75
M=1
C0=[P(1*0),P((0+1)*1-1)]=[P0,P0]
同理:
C1=[P(1*1),P((1+1)*1-1)]=[P1,P1]
C2=[P(1*2),P((2+1)*1-1)]=[P2,P2]
C3=[P(1*3),P((3+1)*1-1)]=[P3,P3]
C4=[P(1*4),P((4+1)*1-1)]=[P4,P4]
C5=[P(1*5),P((5+1)*1-1)]=[P5,P5]
C6=[P(1*6),P((6+1)*1-1)]=[P6,P6]
C7=[P(1*7),P((7+1)*1-1)]=[P7,P7]
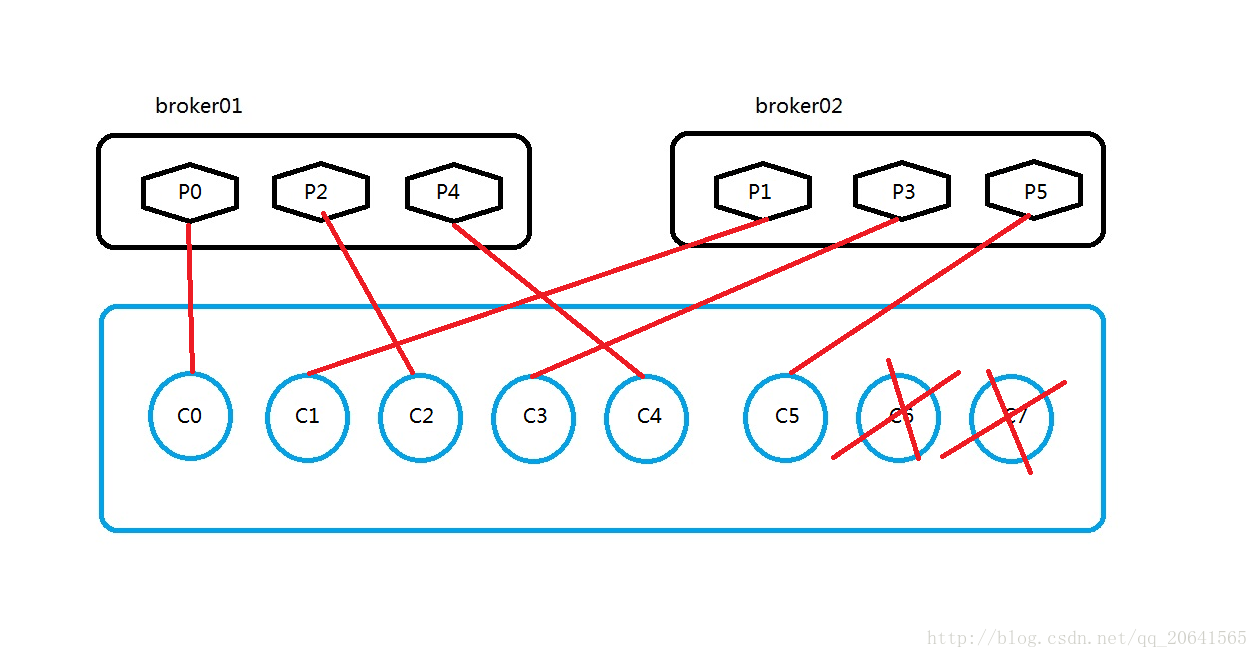
那么按照上面的算法:
C0消费者消费P0的数据
C1消费者消费P1的数据
C2消费者消费P2的数据
C3消费者消费P3的数据
C4消费者消费P4的数据
C5消费者消费P5的数据
C6消费者消费P6的数据
C7消费者消费P7的数据
但是partition只有P0-P5根本就没有P6和P7,所以这两个消费者相当于是会被闲置的,就相当于占用资源,却没什么用,所以在这里真正起到作用的就是C0-C5。
如下图所示:
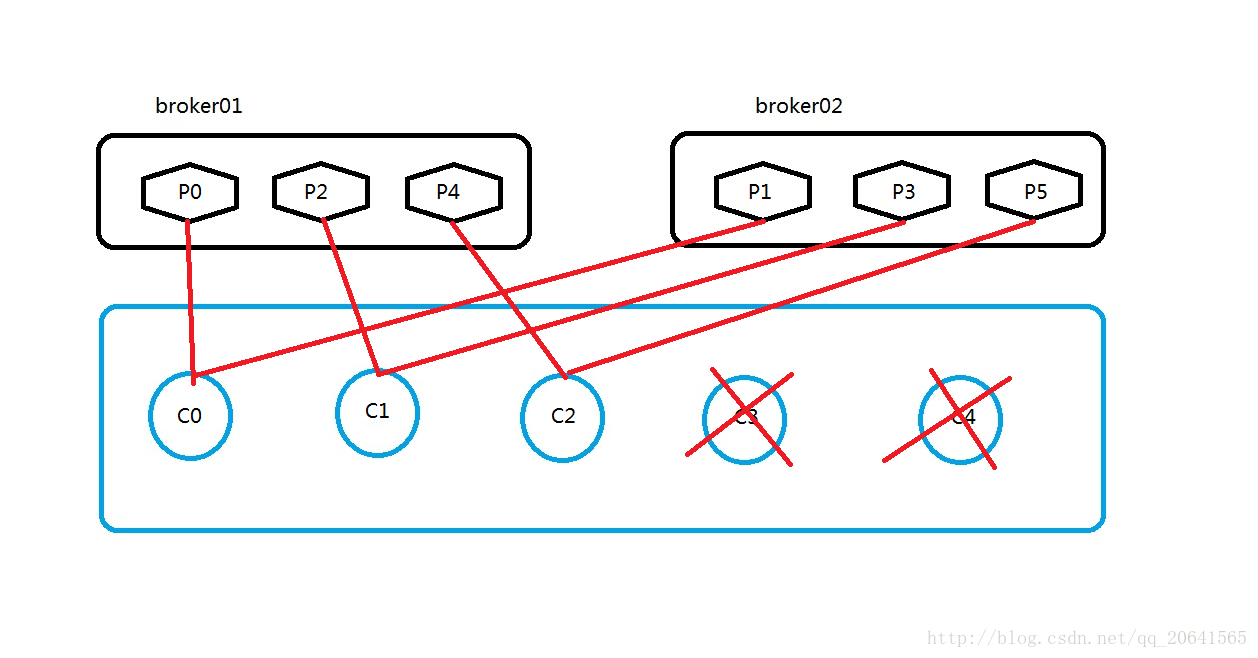
如果这个消费组里面的消费者少于partition数量呢(比如5个)?
那么还是依葫芦画瓢,根据上面的算法:
A=6/5=1.2
M=2
C0=[P(2*0),P((0+1)*2-1)]=[P0,P1]
C1=[P(2*1),P((1+1)*2-1)]=[P2,P3]
C2=[P(2*2),P((2+1)*2-1)]=[P4,P5]
C3=[P(2*3),P((3+1)*2-1)]=[P6,P7]
C4=[P(2*4),P((4+1)*2-1)]=[P8,P9]
同上面一样C3和C4没有起到任何作用。
如下所示:
总结:
1.按照如上的算法,所以如果kafka的消费组需要增加组员,最多增加到和partition数量一致,超过的组员只会占用资源,而不起作用;
2.kafka的partition的个数一定要大于消费组组员的个数,并且partition的个数对于消费组组员取模一定要为0,不然有些消费者会占用资源却不起作用;
3.如果需要增加消费组的组员个数,那么也需要根据上面的算法,调整partition的个数

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)