深度学习框架Deeplearning4j实战:文本智能抽取快速定位
一、Deeplearning4jDeeplearning4j(简称DL4J)是基于java的一个深度学习框架,已经发布了1.0版本的beta版。与其他深度学习框架相比,DL4J具有以下优点:与Spark、Hadoop、Kafka等主流JVM框架实现大规模集成专为基于分布式CPU和/或GPU运行而优化服务于Java和Scala用户群企业级部署可享商业化支持二、神经网络2.1、定义神经网络是一个模拟生
一、Deeplearning4j
Deeplearning4j(简称DL4J)是基于java的一个深度学习框架,已经发布了1.0版本的beta版。
与其他深度学习框架相比,DL4J具有以下优点:
- 与Spark、Hadoop、Kafka等主流JVM框架实现大规模集成
- 专为基于分布式CPU和/或GPU运行而优化
- 服务于Java和Scala用户群
- 企业级部署可享商业化支持
二、神经网络
2.1、定义
神经网络是一个模拟生物(更确切的说,就是人)大脑结构的数学模型。人的大脑由1000亿个神经元构成,神经元通过各自间的连接,形成一个网络,就是所谓的神经网络。
人工神经网络就是通过数学建模的办法模拟大脑神经网络结构,实现类似人脑的功能。
2.2、作用
目前而言,神经网络最常被应用在分类和模式识别上面。
分类最著名的例子就是百度首席科学家吴达恩(Andrew Wu)用youtube上的视频训练神经网络,使神经网络准确识别出猫。
模式识别,举个例子,某宝网通过数据统计,统计出每个注册用户的每天的订单数据情况。这些订单数据可能千差万别,数据之间也没有必然联系。如果要统计这些用户的类别,分析出他们的一些属性,该如何操作?人工操作肯定不行,像某宝网每天PB级的数据,那要请多少人来干这活,那计算机能干这活吗?能,关键是要把这些数据转换成计算机,更准确的说,神经网络,能识别的数据模型,然后,根据人们的一些直观认识,例如买化妆品的大多是小女生,买保健品的多是老大妈老大爷,诸如此类的所谓先验知识,来设定神经网络的分类目标。
虽说通过不断学习,网络总能与人们的直观认识达成一致(至少是大部分一致),但这仅对于训练样本而言。我们训练网络的目的,是为了最终的预测(也称为泛化)。如果网络对于除训练样本之外的数据,识别出来的分类未能与人们直观的认识相一致,就会出现所谓的过拟合的问题。事实上,究竟人们直观认识上的东西是不是真能找到这样一个数学公式来近似模拟,不好说,因为神经网络也不是万能的。
因此,神经网络擅长于一些模识较为固定的领域,例如图像识别。因为大部分的图形,都可以找到其相应的解析函数。
2.3、基本概念
神经网络有多种,不同的神经网络有不同的用途。如正向前馈网络(BP网络),递归网络(RNN),卷积网(CNN)。但不管什么样的神经网络都离不开以下这几个概念。这里只粗浅的介绍其中一些概念(不一定全)及在dl4j中相对应的部分,其中一些复杂的数学推导这里不作展开。
2.3.1、神经元
这是神经网络最基本的元素,神经元接收输入,并产生输出。
最经典的结构如下图所示:

神经元输入输出的数学模型大致可以简化成如下数学公式
其中xi是输入,wi是权值(),b是偏置,f(·)是激活函数(activation function,常用的有sigmod,RELU,SOFTMAX)。这个公式就是神经元实际执行的计算操作。在dl4j里面没有单独为神经元建模,因为框架实际上已经把网络模型转换为矩阵运算。
2.3.2、网络模型
可以看得出来,神经元的输出计算是一个简单的线性函数,所以一层的神经网络(称为感知器perceptor)只能处理线性可分的分类问题。为了打破感知器的局限,才有了BP网络等多层网络模型。理论证明,经过神经元之间的相互连接,形成一个更复杂的确网络,能解决更多的分类问题。
神经元的输入可能是原始数据样品,也可能是上一层数据的输入,这取决于神经元所处的层,对于一些复杂的神经网络来说,神经元可能有多层分布,每一层的神经元接收上一层(如果存在)神经元的输出数据,产出下一层(如果存在)神经元的输入数据。输入层接收的是原始输入,输出层输出的是最终输出。
传统的三层BPN的是长下面这副模样的:
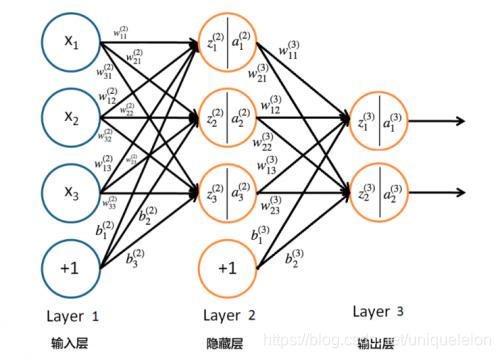
如果把整个神经网络看作一个黑盒子,那输入输出的关系更可以进一步简化成Y=F(X)。理论上,通过选择不同的权值和激活函数,函数F(X)的输出能逼近任意连续函数。神经网络能实现分类的原理即在此。
举例,2维平面直角坐标系(可推广到n维)上有一堆点(事先不知道其规律),如果能过这些点作一个曲线(推广到n维上就是超平面),那么这个曲线的解析函数即为神经网络所演化出来的F(X)。如果有n条曲线刚好穿过这些点,实际上就相当于把这些点分成了n类。如果网络自己学习到的这些曲线与人们直观认识上的分类相一致,我们就认为网络已经成功实现了分类。
在DL4J中,可以为每一层进行单独建模。建模的过程中,可以自由选择参数,参数包括输入输出的个数,偏置值,权值初始化方案,激活函数,损失计算函数等。
2.3.3、训练样本
训练样本就是你能给神经网络提供的数据,训练样本在DL4J里面分成两部分,分别为特征(features)和标签(labels),特征就是网络实际用于训练的数据,例如人的身高,体重等,标签顾名思义就是给样本打标签,在dl4j的一些demo里,就是一个某维为1,其余全为0的n维向量。如果按照身高,把人们分成三类,高个,中等身材,矮个。那么转换成dl4j的标签即为一个三维向量,如要把一个人标签为高个,那么他的标签向量即为(1.0,0,0)。
为了保证学习质量,训练样本一般成批地进行输入,所以这里又有一个最小批量(miniBatch)的概念。为什么要设定最小批量,因为神经网络是一个复杂的计算模型,要考虑到一个性能与精度的问题,样本量太大,会导致性能下降,样本量太小,样本覆盖范围不够广,精度又会降低,因此设定一个最小批量值,有助于得到一个性能与精度之间的平衡。
而训练的过程,就是不断向神经网络输入相同的数据样本,不断调整网络参数,并最终得到输出误差达到指定范围内的网络模型。
2.3.4、误差与收敛
如前文所述,我们其实是想找到一个近似函数来模拟点集在n维空间的超平面轨迹F(X)。但是神经网络找到的F(X),未必就是我们想要的东西。例如我们要求张量(即n维向量)T应当是属于某一个分类,从数学的角度来说,就是对于分类函数F'(X),这个张量会有预期的输出。如果网络训练的结果与预期输出不一致,就会出现误差。
误差会通过所谓的损失函数(英文称loss function,或cost function,有好几种,常用的有log似然函数)来计算,再通过反向传播算法来修正网络参数(权重)来缩小误差。我们希望误差透过上述算法可以变得越来越小,用数学的语言来说,就是所谓的收敛。但收敛并不是越快越好,因为收敛得快,不一定代表后面预测得准,因此会有所谓的学习率,学习率就是用来控制收敛速度。
上述概念,如偏置,激活函数,网络层数,神经元个数,损失函数,学习率等,在DL4J中都被称为神经网络的超参数(hyper parameter)。通过调节这些参数,能得到不同功能,不同分类特征的神经网络,因此称为超参数。
三、实战
3.1、入门
DL4J是一种特定领域的语言,用于配置由多层构成的深度神经网络。一切都从MultiLayerConfiguration开始,这些MultiLayerConfiguration组织这些层和它们的超参数。
超参数是决定神经网络如何学习的变量。它们包括更新模型权重的次数、如何初始化这些权重、将哪个激活函数附加到节点、使用哪个优化算法以及模型应该学习多快。这就是一个配置的样子:
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.weightInit(WeightInit.XAVIER)
.activation("relu")
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(new Sgd(0.05))
// ... other hyperparameters
.list()
.backprop(true)
.build();
使用DL4J,可以通过调用NeuralNetConfiguration.Builder()上的layer方法来添加层,按照层的顺序(下面的零索引层是输入层)指定其位置、输入和输出节点的数量是nIn和nOut以及类型为:DenseLayer。
.layer(0, new DenseLayer.Builder().nIn(784).nOut(250)
.build())
一旦你已经配置好你的网络,你可以用 model.fit来训练你的网络
3.2、实战
目的:文本智能抽取:通过分析文章,定位要抽取的字段在文章中的位置(哪一段、哪一句)。
3.2.1、提取特征
- 关键词:对已抽取好的规则数据进行词频统计,校验,挑选出跟字段相关的特征关键词;
- 正则表达式:对一些关键词不好统计的特征进行总结,用正则表达式来进行提取,例如”罚款金额”等;
- 最后对特征进行合并,去重,剔除其中歧义较大的。
3.2.2、文本标注
- 先对文本进行分段,对每段文本进行特征提取;
- 对有特征的标记的文本进行标注,是否含有某字段相关信息;
- 将标注好的文本进行随机分配,一部分为训练文本,一部分为测试文本;
3.2.3、模型训练
对于输入的训练集,采用神经网络算法,定义好输入层、输出层等算法参数。
训练过程:
- 读入训练集,将训练集向量化,每个特征是一个维度,若是文本包含特征则为1,否则为0;
- 构造神经网络,设置参数配置;
- 进行迭代训练;
- 测试模型准确率召回率是否达标,若达标则进行下一步;
- 否则返回2调整参数配置;
- 保存模型。
下面是dl4j打印出来的输出结果:
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.9887
Precision: 0.9946
Recall: 0.9903
F1 Score: 0.9925
Precision, recall & F1: reported for positive class (class 1 - "1") only
=========================Confusion Matrix=========================
0 1
-----------
2453 40 | 0 = 0
73 7434 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
简单解释一下结果:
Accuracy 精确率,正确识别数/总样本数
Precision 精密度,精密度通常以算术平均差、极差、标准差或方差来量度。
Recall 召回率
F1 : 各分类准确率的宏观平均值
具体参考:https://blog.csdn.net/index20001/article/details/77651028

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)