windows/linux 安装zookeeper + Kafka (含自启动)运行教学
详细的一站式实战,让笔者带你快速使用上手使用kafka~~~
首先我们来花两分钟了解一下:
什么是zookeeper?
什么是kafka?
为什么kafka依赖zookeeper和javaSDK?
Zookeeper 和 Kafka 都是 Apache 软件基金会中的开源软件。
Zookeeper 是一个分布式协调服务,它提供了一个基于树形结构的命名空间来协调分布式系统的各个部分。Zookeeper 能够跟踪各个分布式系统组件的状态,并在这些组件之间协调消息传递,从而帮助开发者构建高可用性、可伸缩性的分布式系统。
Kafka 是一个分布式流处理平台,它具有高吞吐量、低延迟的特点。Kafka 通过发布-订阅模式来处理消息,同时提供了流式处理和批处理的支持。Kafka 可以用于处理各种类型的数据,包括日志、指标、事件、事务等。
Kafka 依赖于 Zookeeper 来存储集群的元数据和状态信息,包括 Kafka 的主题、分区、副本等。Kafka 还使用 Zookeeper 来选举控制器和领导者,并协调各个 Kafka 节点之间的同步和复制操作。因此,Kafka 不能单独运行,必须与 Zookeeper 一起使用。
此外,Kafka 还依赖于 Java SDK 来提供对 Java 程序的支持。Kafka 是用 Java 语言编写的,因此需要 Java 运行时环境来运行。Kafka 的客户端 API 也是用 Java 语言编写的,因此需要 Java SDK 来进行开发和编译。
接下来让我一起大展身手=======》
请耐心看完再操作,感谢浏览,一键三连下次再见~
目录
调试Kafka 生产者与消费者消息互通机制(Windows)
下载 JAVA JDK(Windows)
在开始之前,需要下载并安装 ,下载地址 Ja、va Downloads | Oracle。
安装地址选择时请记录安装地址哦!!!!!
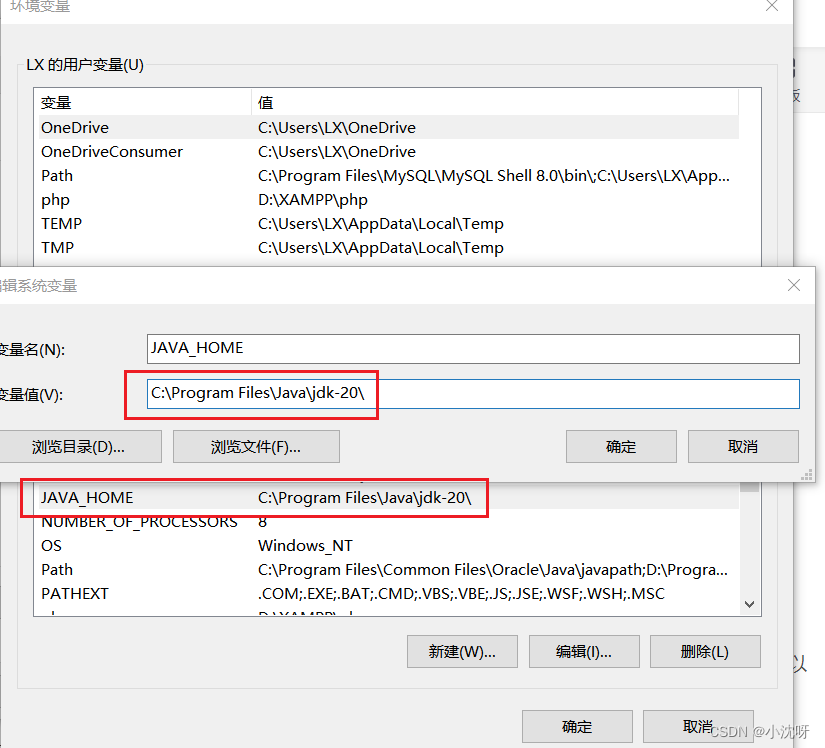
在“环境变量”设置中,找到“系统变量”中的“新建”按钮,然后输入以下内容:
- 变量名:JAVA_HOME
- 变量值:Java 安装目录的路径

下载 JAVA JDK(Linux)
在开始之前,需要下载并安装 ,下载地址 Ja、va Downloads | Oracle。
选择Linux版本下载,我这里下载了
apache-zookeeper-3.7.1-bin.tar.gz
通过winscp或其他软件放在你的linux上
我这里的示例目录放在/opt/tempFile文件夹下

-
然后解压安装包,可以使用以下命令:
tar -zxvf jdk-*.tar.gz解压后会在当前目录下生成一个名为
jdk-*的目录。*代表的是你下载的JDK版本哦请自行替换!! -
将解压后的目录移动到合适的位置,比如
/opt目录下:sudo mv jdk-* /opt -
设置环境变量。可以编辑
/etc/profile文件,在文件末尾添加以下内容:export JAVA_HOME=/opt/jdk-* export PATH=$PATH:$JAVA_HOME/bin其中,
*表示 JDK 版本号,具体替换为解压后的目录名。 -
使环境变量生效,执行以下命令:
ource /etc/profile -
验证 Java 是否安装成功,执行以下命令:
java -version如果成功安装,将会输出 JDK 的版本号信息。
至此,Java 的安装和环境变量的配置就完成了。
下载 Kafka 及控制台包
在开始之前,需要下载并安装 Apache Kafka。你可以从官方网站下载 Kafka:Apache Kafka
这一步不解压与安装,后续会详细说明,!!!!别急哦~~
下载 ZooKeeper (Windows与Linux)
可以从 ZooKeeper 的官方网站(https://zookeeper.apache.org/)下载最新版本的 ZooKeeper
我这里下载的是: apache-zookeeper-3.7.1-bin.tar.gz
配置 ZooKeeper(Windows)
在 ZooKeeper 的解压缩目录中,找到 conf 文件夹,该文件夹包含了 ZooKeeper 的配置文件。以下是一些需要注意的配置选项:
dataDir:指定 ZooKeeper 存储数据的目录,默认为/tmp/zookeeper。
在 ZooKeeper 中,dataDir 是指数据存储目录,用于存储 ZooKeeper 的数据快照和事务日志。它可以是相对路径或绝对路径,具体取决于在配置文件中指定的路径格式。
如果使用相对路径,则相对路径是相对于 ZooKeeper 的安装目录。例如,如果安装目录为 C:\zookeeper,并且 dataDir 被设置为 data,则数据存储目录将位于 C:\zookeeper\data。
如果使用绝对路径,则直接指定完整路径即可。例如,如果 dataDir 被设置为 C:\zookeeper\data,则数据存储目录将位于 C:\zookeeper\data。
clientPort:指定客户端连接到 ZooKeeper 服务器的端口号,默认为 2181。tickTime:指定 ZooKeeper 服务器之间的心跳间隔时间(以毫秒为单位),默认为 2000。
可以根据需要修改这些选项的值,以便更好地满足实际需求。修改完成后,将 conf 文件夹复制到一个安全的位置(例如 /etc/zookeeper 或 C:\zookeeper\conf)。

PS:请注意此处官网下载的包只有zoo_sample.cfg (示例文件),zoo.cfg需要自行复制后zoo_sample.cfg文件后更名配置使用
配置 ZooKeeper(Linux)
在 ZooKeeper 的解压缩目录中,找到 conf 文件夹,该文件夹包含了 ZooKeeper 的配置文件。以下是一些需要注意的配置选项:
dataDir:指定 ZooKeeper 存储数据的目录,默认为/tmp/zookeeper。
在 ZooKeeper 中,dataDir 是指数据存储目录,用于存储 ZooKeeper 的数据快照和事务日志。它可以是相对路径或绝对路径,具体取决于在配置文件中指定的路径格式。
如果使用相对路径,则相对路径是相对于 ZooKeeper 的安装目录。例如,如果安装目录为 C:\zookeeper,并且 dataDir 被设置为 data,则数据存储目录将位于 C:\zookeeper\data。
如果使用绝对路径,则直接指定完整路径即可。例如,如果 dataDir 被设置为 C:\zookeeper\data,则数据存储目录将位于 C:\zookeeper\data。
clientPort:指定客户端连接到 ZooKeeper 服务器的端口号,默认为 2181。tickTime:指定 ZooKeeper 服务器之间的心跳间隔时间(以毫秒为单位),默认为 2000。
可以根据需要修改这些选项的值,以便更好地满足实际需求。修改完成后,将 conf 文件夹复制到一个安全的位置(例如 /opt/zookeeper/data/如不存在文件,直接创建后指向即可)。

ZooKeeper 的配置文件为 conf/zoo.cfg,需要进行以下修改:
tickTime=2000
dataDir=/opt/zookeeper/data
clientPort=2181创建 ZooKeeper 数据目录
在上一步中,我们将 dataDir 设置为 /var/lib/zookeeper,需要手动创建该目录:
$ sudo mkdir -p /var/lib/zookeeperPS:请注意此处官网下载的包只有zoo_sample.cfg (示例文件),zoo.cfg需要自行复制后zoo_sample.cfg文件后更名配置使用
启动 ZooKeeper(Windows)
在 Windows 系统上,可以使用命令行启动 ZooKeeper
当前安装目录:C:\apache-zookeeper-3.7.1-bin
- 在 Windows 系统上,打开命令提示符,并进入 ZooKeeper 的解压缩目录,然后执行以下命令:
#切换目录至C:\apache-zookeeper-3.7.1-bin\bin文件夹下
cd /d C:\apache-zookeeper-3.7.1-bin\bin>
#运行该服务
zkServer.cmd正常情况下没有ERROR警告释出,基本Zookeeper已经启动完成了,我这边的图示

启动 ZooKeeper(Linux)
-
启动 ZooKeeper
启动 ZooKeeper 需要执行以下命令:
$ cd apache-zookeeper-3.7.1-bin $ bin/zkServer.sh start如果看到以下输出,则代表 ZooKeeper 启动成功:
设置开机启动 ZooKeeper(Linux)
待更新
配置 Kafka(Windows)
开始使用 Kafka ,将其解压到自己选择的目录下
示例当前目录C:\Kafka
我们需要对其创建环境变量(windows怎么新增修改环境变量,请自行百度)
系统变量中,选择Path变量,新建当前解压目录下的bin文件夹

保存退出
检查自己kafka bin文件夹下是否多了windows文件夹,没有的话就是你的环境变量配置有误哦
配置 Kafka(Linux)
待更新
启动 Kafka(Windows)
在 Windows 系统上,打开命令提示符,并进入 kafka的解压缩目录,然后执行以下命令:
#切换至kafka根目录
cd /d C:\Kafka
#运行kafkaf服务
.\bin\windows\kafka-server-start.bat .\config\server.properties 正常情况下没有ERROR警告释出,基本kafka已经启动完成了,我这边的图示
启动 配置 Kafka(Windows)
待更新
调试Kafka 生产者与消费者消息互通机制(Windows)
-
打开一个新的命令行窗口。
-
进入 Kafka 的安装目录,然后进入
bin目录。 -
运行以下命令来启动 Kafka 的控制台生产者:
-
执行cd C:/Kafka/bin/windows
-
执行 afka-console-producer.bat --broker-list localhost:9092 --topic test
这将启动一个控制台生产者,它将向名为
test的主题发送消息。请注意,这里使用的是本地 Kafka 服务器的默认地址和端口,如果你的 Kafka 服务器位于不同的主机或使用了不同的端口,请相应地修改命令中的参数。 -
等待几秒钟,直到控制台显示类似于以下内容的提示符
 (啥也没有就对了)
(啥也没有就对了) -
这表明控制台生产者已经准备好了,可以开始向 Kafka 发送消息了。
-
在控制台中输入一些文本,然后按回车键发送消息。例如:
Hello ,this is u first Kafka!这将向
test主题发送一条消息,其内容为Hello ,this is u first Kafka!。 -
打开另一个命令行窗口,进入 Kafka 的
bin目录,然后运行以下命令来启动控制台消费者:kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning这将启动一个控制台消费者,它将从
test主题订阅消息,并显示在控制台中。请注意,--from-beginning参数表示从主题的开头开始消费消息,以便能够查看在启动消费者之前发送的消息。 -
在控制台消费者窗口中,你应该能够看到之前发送的消息:
这表明 Kafka 已经成功启动,并且可以通过控制台生产者和消费者来发送和接收消息
启动 Kafka(Linux)
待更新
设置开机启动Kafka(Linux)
待更新

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)