初识Kafka:构架、生产消费模型以及其他相关概念
公司的事件总线采用的是Kafka分布式消息队列来完成的,近来项目需要接入到事件总线中,故开启了kafka的学习之旅(之前一直在听说kafka这玩意儿,但是学习计划中还没有将它安排进去,借着这个机会学习kafka也算是弥补了这方面的一些遗憾~)关于kafka是神马东西这里就不在累述了,网上的资料一大堆下面分享一些自己对kafka的理解,如有不妥之处还望指出~(1)何为分布式消息队列?有何特点?1、一
当前使用的事件总线采用的是Kafka分布式消息队列来完成的,近来项目需要接入到事件总线中,故开启了kafka的学习之旅(之前一直在听说kafka这玩意儿,但是学习计划中还没有将它安排进去,借着这个机会学习kafka也算是弥补了这方面的一些遗憾~)
关于kafka是神马东西这里就不在累述了,网上的资料一大堆
下面分享一些自己对kafka的理解,如有不妥之处还望指出~
(1)何为分布式消息队列?有何特点?
1、一旦涉及到分布式这个概念,其就必须解决两个问题:可靠性和可扩展性。
kafka通过事件回溯机制来实现高可靠性:当出现一些不可预料的异常导致生产的消息没有被相应的消费者消费掉时,kafka可以进行回滚操作,将消息队列恢复到这个异常事件的地方让消费者可以重新消费,保证每个消息都有相应的消费者消费掉
kafka支持水平扩展,brocker(kafka集群上的一个或多个服务器)越多,集群的吞吐率越高,如果你觉得你的kafka不够用了,简单,加大集群规模,就像使用调节按钮一样简单方便
2、既然叫消息队列,那么它就有队列的特征,顺序、按个存取。保证事件能够按照规定的顺序被处理掉,就像挂号排队一样,一个个领号,在按顺序一个个处理
(2)那么为什么要用这个分布式消息队列呢?
大多数的应用都需要处理一些事件,例如某个用户点击了什么东西,这个动作要进行一些额外的处理,但是处理的行为定义在另外一个程序中(当系统框架大了之后这种行为很常见)。常规的解决方法就是调用接口
但是这么做有一个很明显的问题,两个应用之间产生了耦合,它们需要知道对方的存在,接口的调用方式是什么。
当系统不是很大的时候这么做并没有什么缺陷,反而会比较方便
但假如应用中要处理n个不同类型的事件,分别由n个不同的程序提供接口进行处理,在应用中必须要知道每个处理程序的调用方式,一方的修改会影响到另外一方。如果有n个应用中有n个事件需要n个程序来处理,互相调来调去,堆在一起很容易就变成了死亡代码
这时候独立的消息队列就可以很简单的解决这个问题,生产事件的应用只管往队列上发事件,不关心有没有人去处理,怎么处理,发了之后就不管了
而处理事件的程序从消息队列中取得事件,不用关心是谁发的,怎么发的
于是消息队列将整个系统都解耦了
之前讲到过,kafka中的消息都是按顺序,一个个存取的,那么问题来了:按顺序一个个处理的话,如果应用A要处理消息a,应用B要处理消息b,消息a排在消息b之前,现在应用A不处理消息a了,而应用B马上就要处理消息b,怎么解决?
其实很简单,kafka并不只有一个队列,不同应用发送的事件可以存放在不同的topic中而不互相影响,狭义上来讲可以将topic这个概念就看成是一个消息队列,而kafka中可以存在n个topic
(3)kafka的构架:
kafka由以下几个部分组成:
Brocker:Kafka集群包含一个或多个服务器,这种服务器被称为broker。生产者向Brocker发送事件,消费者从Brocker中拿事件
Topic:之前提到过,可以将topic看成是一个消息队列,每个事件都必须指定其要存在在哪个topic中(这里倒是可以当成事件的分类来看待),topic是存在于brocker之中的
Partition:每个topic都可以包含一个或者多个partition,顾名思义,就是分区的意思,这里和hadoop的mr程序的partitioner分区有些相似,可以将topic中的各个事件按照规则分开存放
Producer:即生产者,负责发送事件到kafka brocker
Consumer:即消费者,从kafka brocker读取事件
Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
kafka通过Consumer Group来实现消息的广播和单播,一个事件发送到一个Consumer Group中,那么这个Group中只能有一个Consumer消费这个事件,但是其他的Consumer Group也可以由其中的一个Consumer来消费这个事件
示意图:
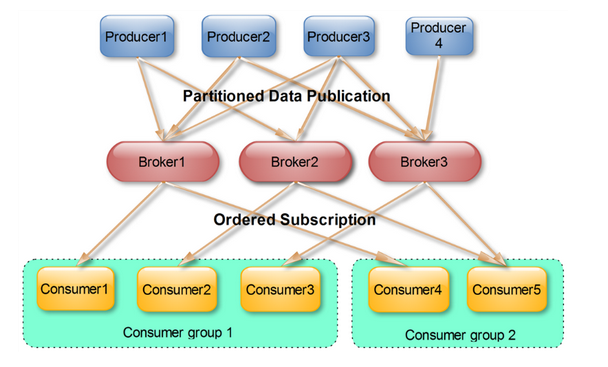
如果要实现广播,让每个Consumer都能收到某个Topic中的事件,只要让各个Consumer处在不同的Consumer Group中即可;单播则是将所有的Consumer放在一个Consumer Group中
kafka构架图:
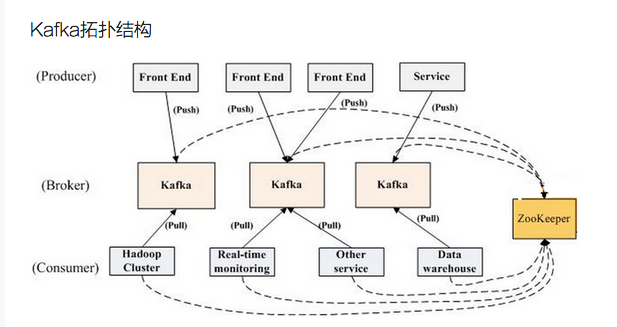
图中的zk起到的作用就是负载均衡,将集群中的变化及时同步到各个节点中,保证集群是一致的
(4)kafka下载、运行测试
进入之后选择Binary Downloads
选择任意的一个版本即可(官方建议下载2.10)
下载下来的tgz包lib目录中有开发kafka客户端程序的相关jar包
将其解压缩之后直接就可使用(因为公司已有kafka集群,可以仅仅拿来当客户端来连接测试使用)
进入kafka目录执行以下命令:
显示kafka中的topic列表
bin/kafka-topics.sh –list –zookeeper 54.223.171.230:2181
54.223.171.230:2181为集群zk节点对应的hostname:port
生产事件
bin/kafka-console-producer.sh –broker-list amazontest:9092 –topic omni
amazontest:9092–为brocker的hostname:port
omni–为要发送到的topic
消费事件
bin/kafka-console-consumer.sh –zookeeper 54.223.171.230:2181 –topic omni –from-beginning
54.223.171.230:2181–消费事件要从zk中获得,所以使用zk的地址
omni–从指定的topic中获得事件
运行过程中出现一个异常,如下图:
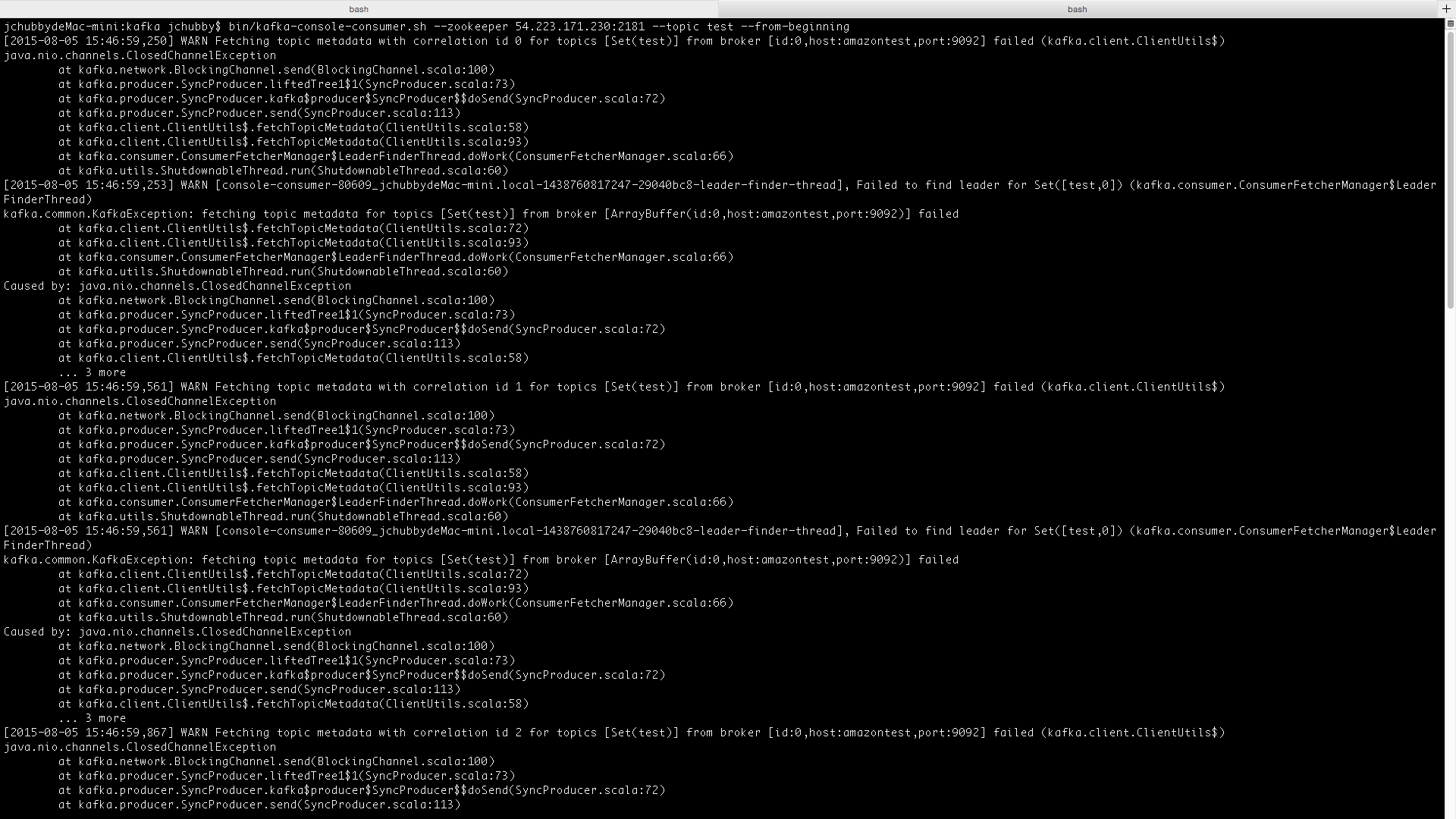
原因是我在本地连接远程kafka集群,而amazontest是定义在程序服务器上的主机名,本地并不知道这个hostname映射到哪个ip,在/etc/hosts中加入此映射关系即可正常
最后推荐一篇文章(上面的图都是偷这里面的)
Kafka剖析(一):Kafka背景及架构介绍

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)