Windows环境下搭建Hadoop+Spark+Zookeeper+Kafka
Windows环境下搭建Spark+Zookeeper+Kafka
一.Windows10 64位环境pyspark安装**
1.安装JDK1.8
(1)下载JDK1.8,需要注册一下oracle网址
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html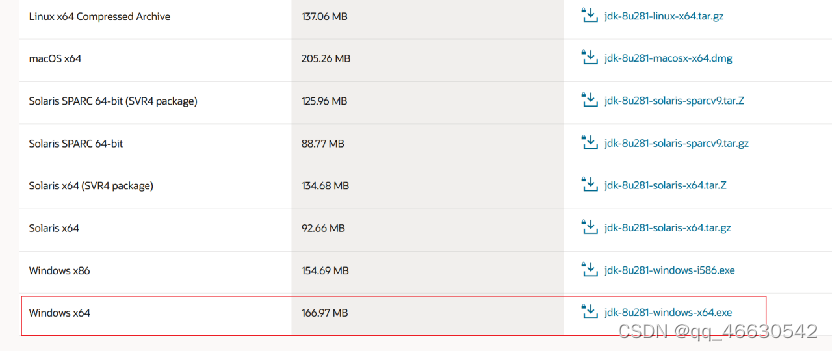
(2)安装JDK1.8
双击安装,一直选择下一步,(注意安装路径 ),直到安装完毕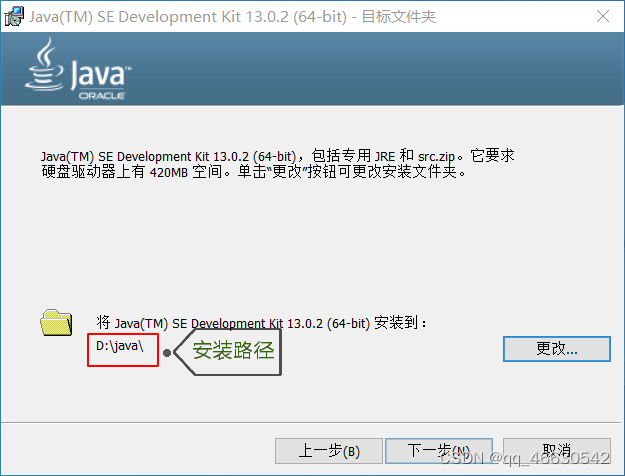
(3)配置Java环境变量
右键点击我的电脑,选择属性,高级系统设置,环境变量,在系统变量中
增加JAVA_HOEM = D:\java(注意,此处为JDK安装路径)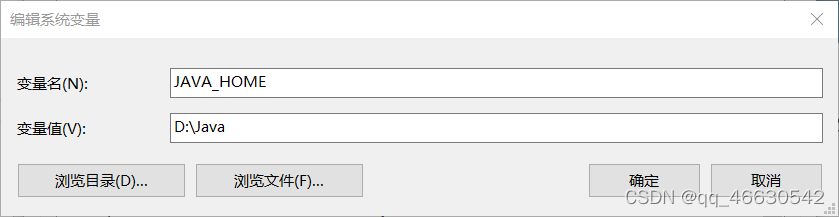
同理,在系统变量区域,选择"新建按钮"输入"变量名"为CLASSPATH,输入"变量值"为.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar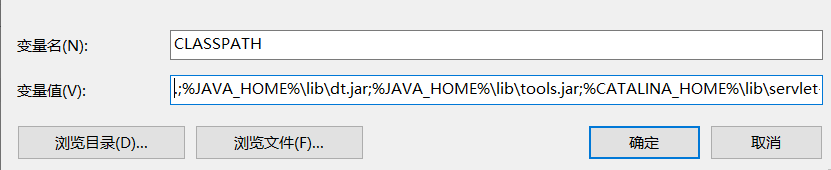
在系统变量区域,选择Path,点击下面的编辑按钮,在弹出的框中选择新建添加2行,一行输入%JAVA_HOME%\bin,一行输入%JAVA_HOME%\jre\bin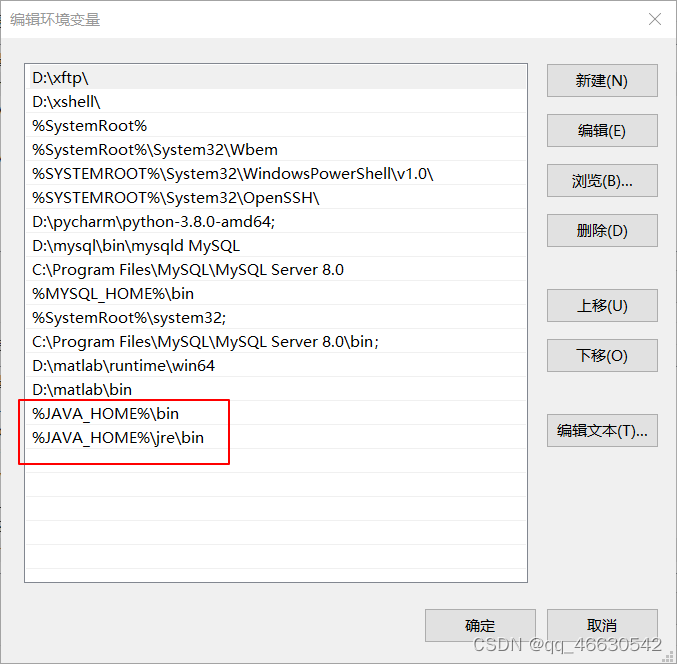
(4)测试
打开cmd ,依次输入java -version,显示如图配置成功。在这里插入图片描述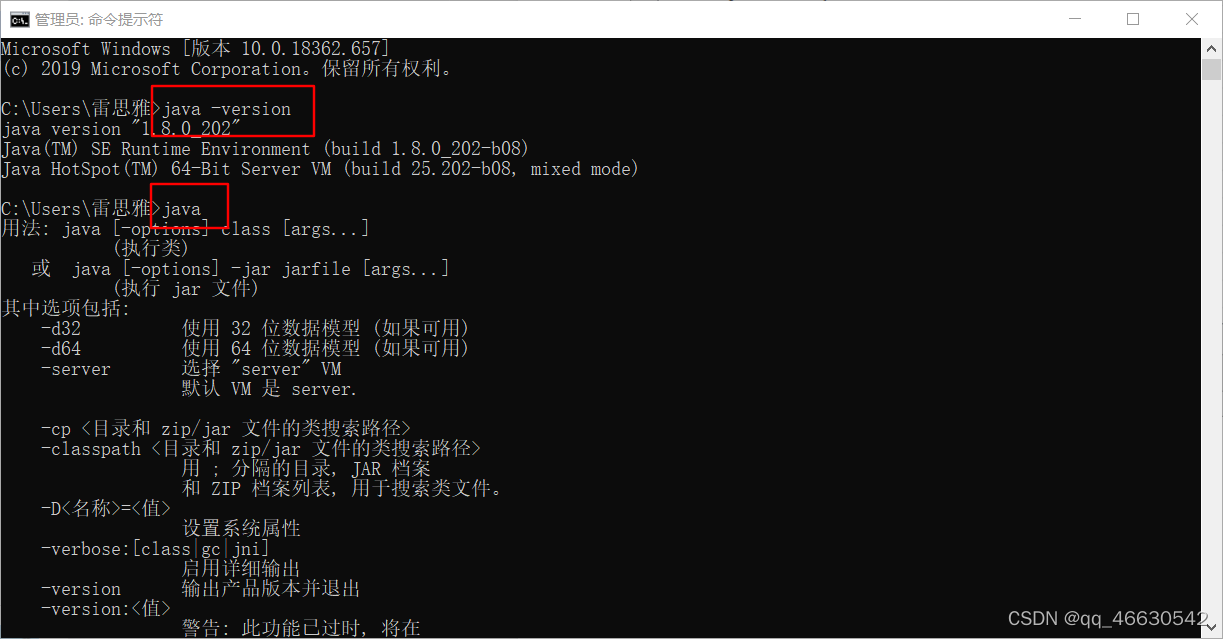
二.Hadoop安装
(1)Hadoop下载
https://hadoop.apache.org/releases.html
(2)hadoop windows10环境安装需要hadoop.dll和winutils.exe两个文件。默认官网下载的二进制hadoop包里面没有,需要去第三方下载,解压找到对应hadoop版本的hadoop.dll和winutils.exe。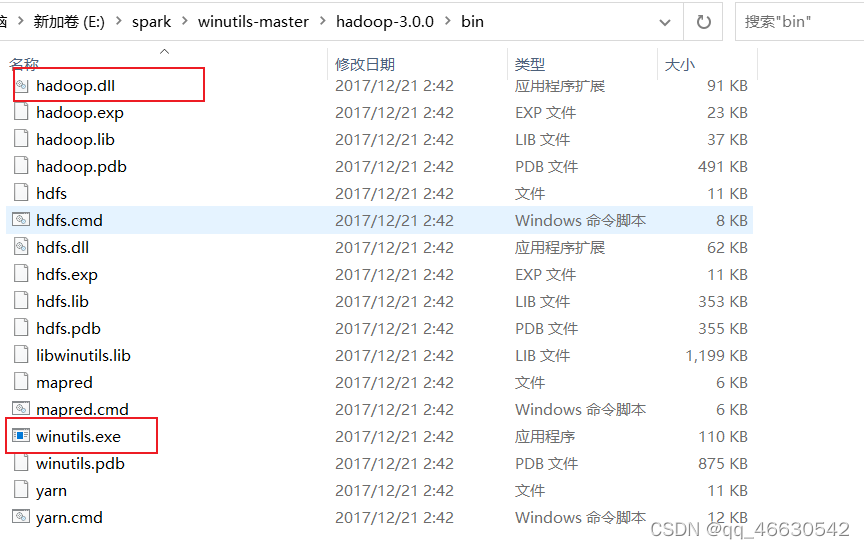
(3)复制hadoop.dll和winutils.exe两个文件到hadoop的bin目录下。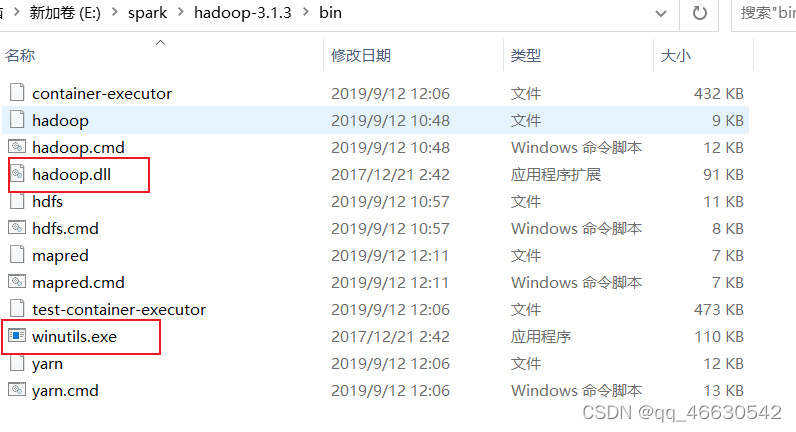 (4)复制hadoop.dll文件到C:\Windows\System32目录下。
(4)复制hadoop.dll文件到C:\Windows\System32目录下。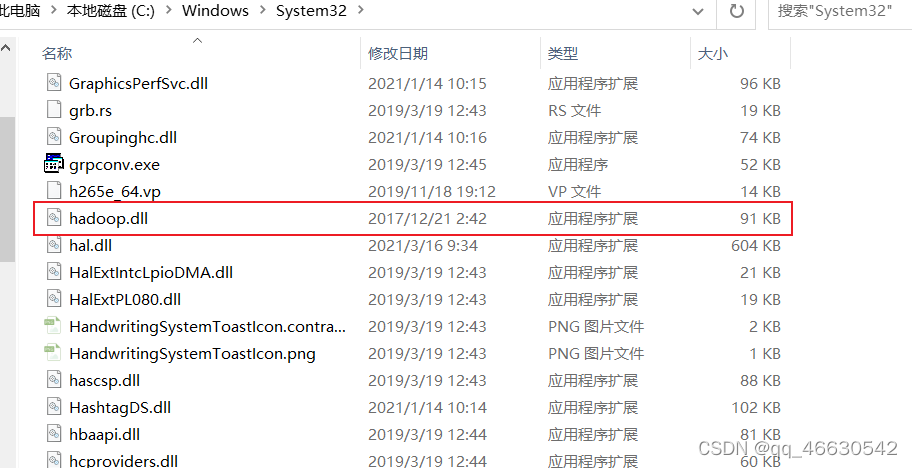
(5)配置Hadoop环境变量。在系统变量里面,新建HADOOP_HOME变量,值为hadoop的解压路径,如下图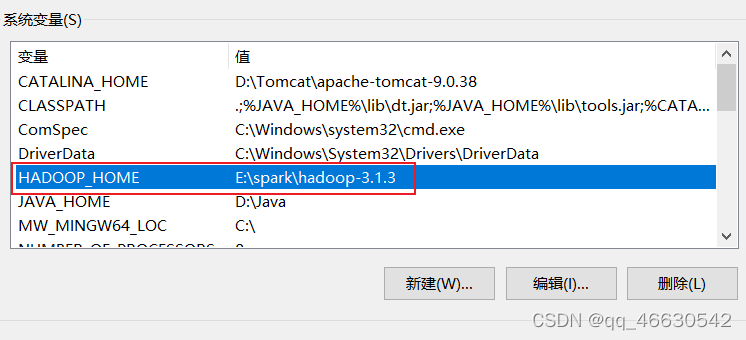
然后在Path路径中,配置bin目录和sbin目录,如图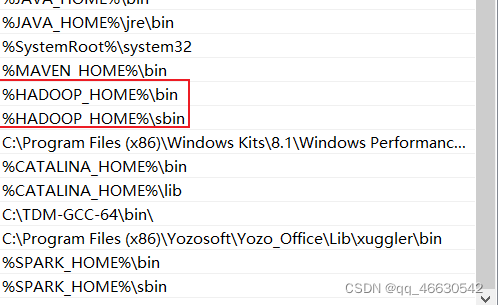
(6)修改hadoop3.1.3里面(我的路径)E:\hadoop-3.1.3\etc\hadoop下的hadoop-env.cmd文件,配置自己的java路径,如图。其中Program Files路径名要替换成Progra~1。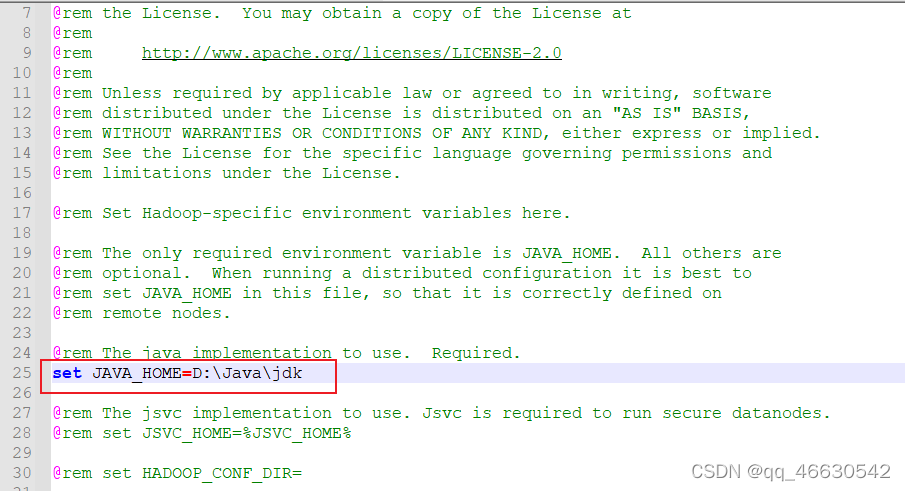
(7)测试hadoop是否配置成功,如图显示,配置成功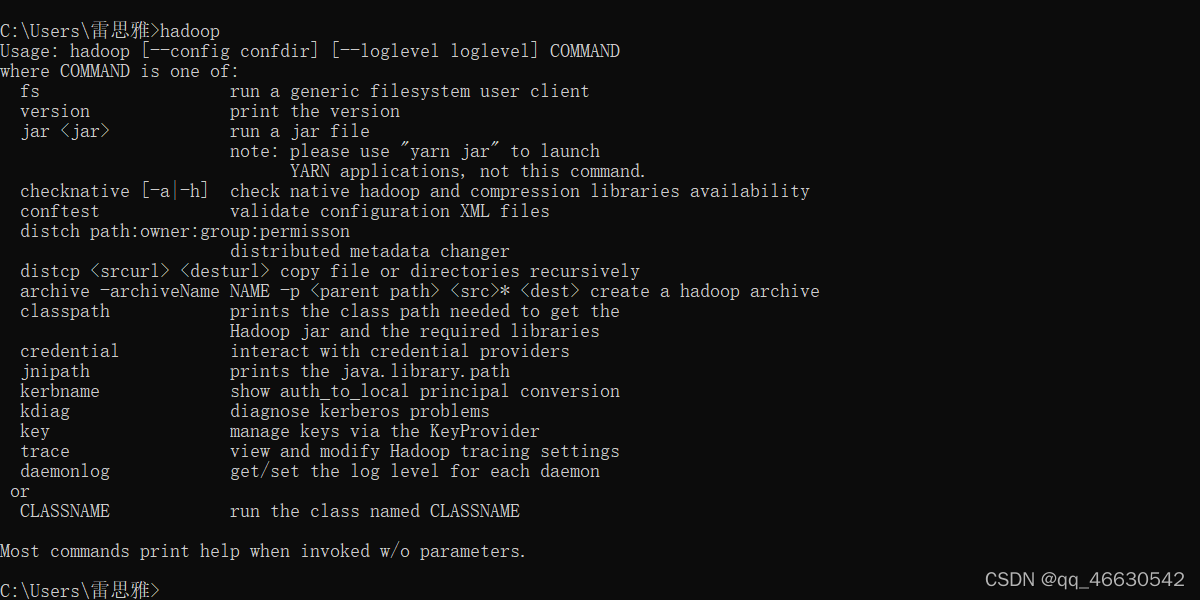
三.Spark安装
(1)下载spark二进制包:http://spark.apache.org/downloads.html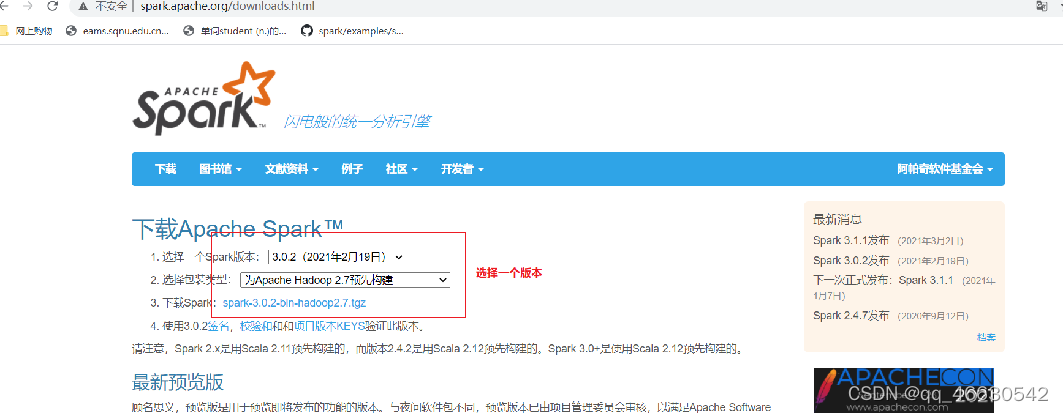
解压
(2)配置环境,系统环境变量
SPARK_HOME=E:\spark\spark-2.4.7-bin-hadoop2.7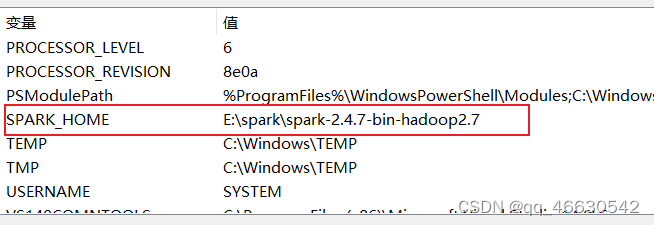
%SPARK_HOME%\bin;%SPARK_HOME%\sbin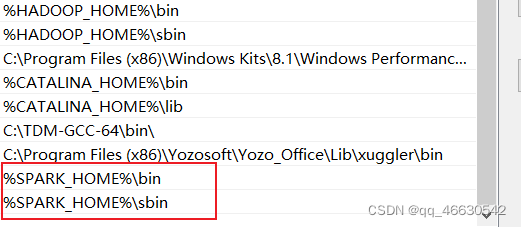
(3)测试Spark环境,win + R cmd 运行pyspark,查看运行版本是否是解压的spark版本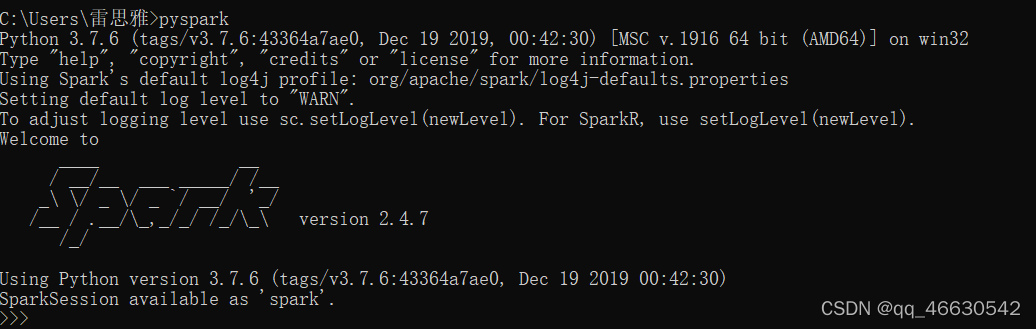
四.搭建Zookeeper
(1)下载安装包https://www.apache.org/dyn/closer.cgi/zookeeper/
解压并进入Zookeeper目录,我的是E:\zookeeper\apache-zookeeper-3.5.9\conf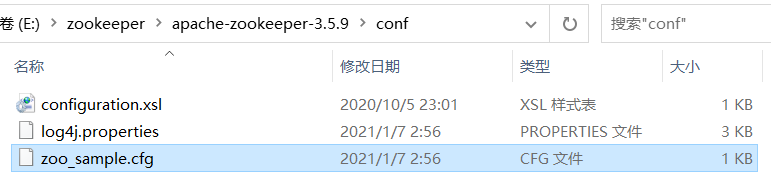
(2)将”zoo_sample.cfg”重命名为“zoo.cfg”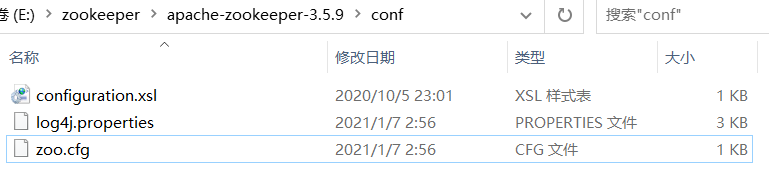
(3)打开“zoo.cfg”找到并编辑
dataDir=E:\zookeeper\apache-zookeeper-3.5.9\data (data目录提前新建好)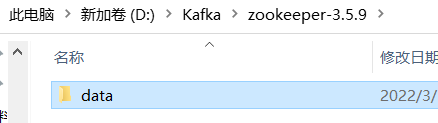

(4)添加系统变量:
ZOOKEEPER_HOME=E:\zookeeper\apache-zookeeper-3.5.9
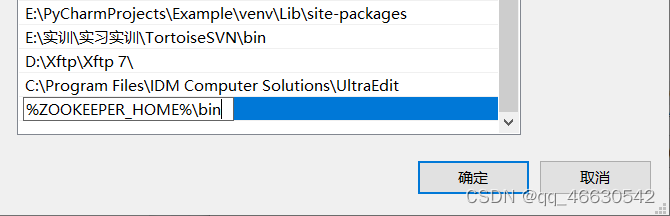
编辑path系统变量,添加路径:%ZOOKEEPER_HOME%\bin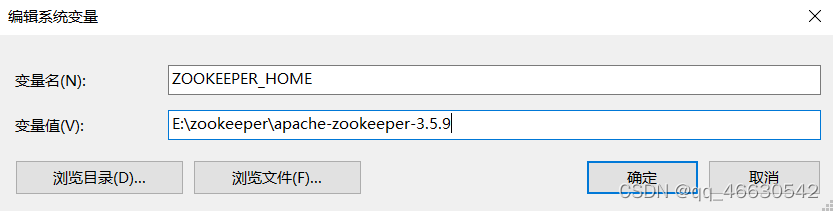
 (5)打开cmd,输入“zkServer”,运行Zookeeper,命令提示如下,则说明Zookeeper启动成功(注意:不要关闭这个窗口)
(5)打开cmd,输入“zkServer”,运行Zookeeper,命令提示如下,则说明Zookeeper启动成功(注意:不要关闭这个窗口)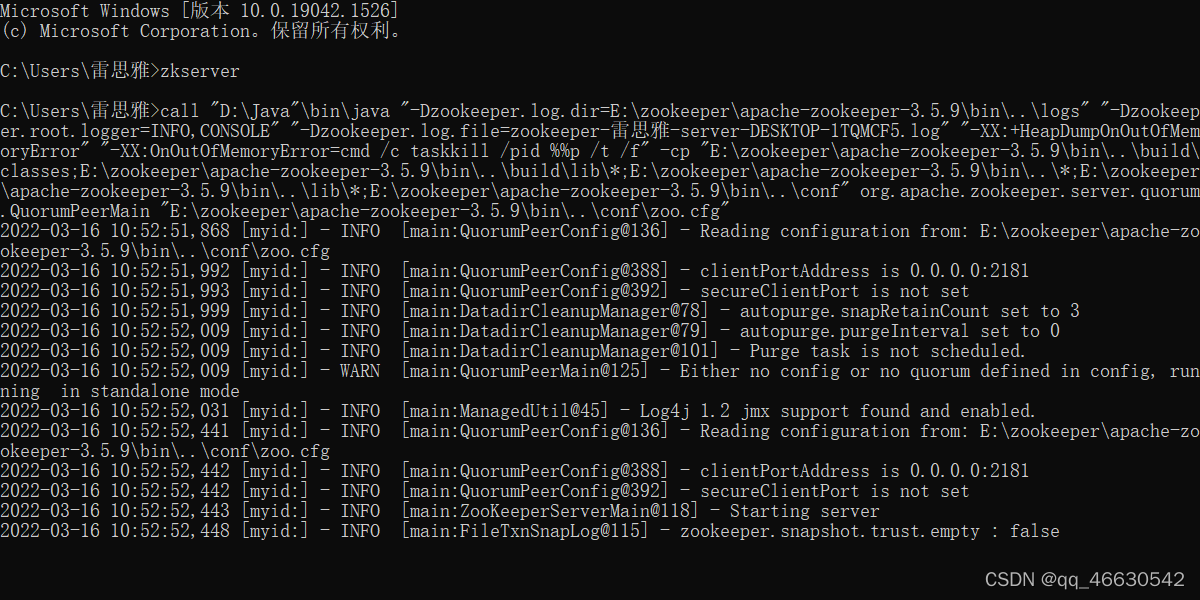
五.Kafka安装
(1)下载安装包:http://kafka.apache.org/downloads 注意要下载二进制版本
(2) 解压并进入Kafka目录,我的:E:\kafka\kafka_2.12-3.1.0
(3) 进入config目录找到文件server.properties并打开
(4) 找到并编辑log.dirs=E:\software\kafka_2.11-2.4.0\kafka-logs(提前新建)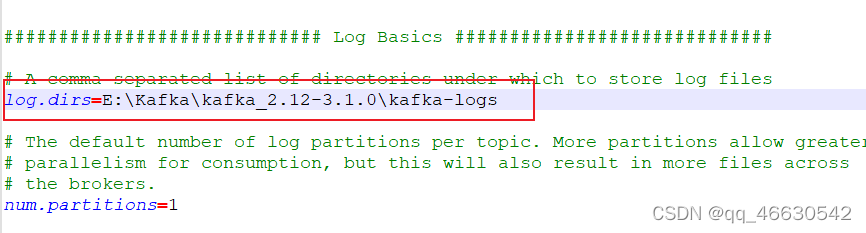 (5) 找到并编辑zookeeper.connect=localhost:2181, Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181
(5) 找到并编辑zookeeper.connect=localhost:2181, Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181
(6)进入Kafka安装目录E:\kafka\kafka_2.12-3.1.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-server-start.bat .\config\server.properties
注意:不要关了这个窗口,启用Kafka前请确保ZooKeeper实例已经准备好并开始运行
(7)创建主题wordsendertest,进入Kafka安装目录E:\kafka\kafka_2.12-3.1.0打开cmd命令行,输入:
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic wordsendertest
注意:不要关了这个窗口
(8)查看主题:输入.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
(9)创建生产者
进入Kafka安装目录E:\kafka\kafka_2.12-3.1.0,打开cmd命令行输入:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic wordsendertest
注意:不要关了这个窗口
(10)创建消费者
进入Kafka安装目录E:\kafka\kafka_2.12-3.1.0,打开cmd命令行输入:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic wordsendertest --from-beginning
在生产者窗口中输入单词,消费者窗口能看到消费的单词信息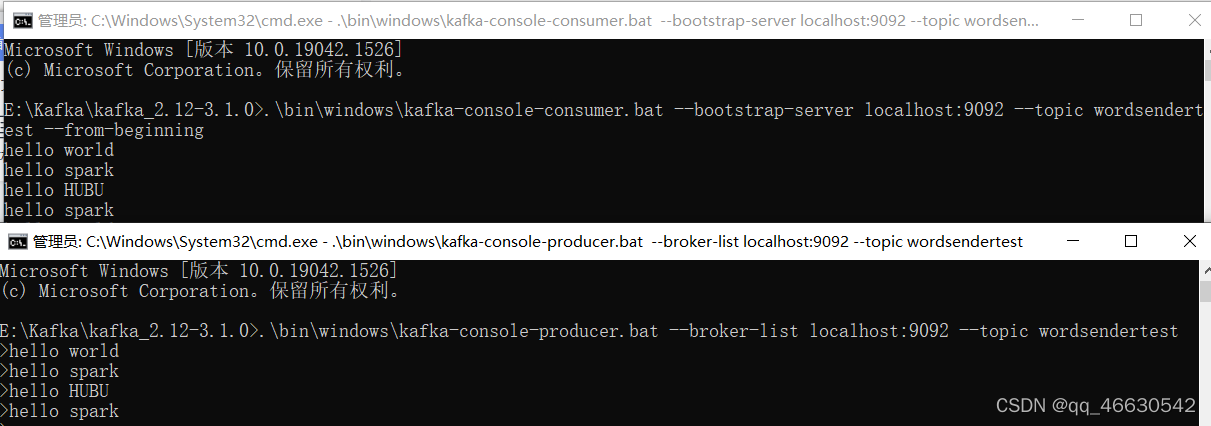

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)