2011-2022年高职大数据竞赛-赛题内容
本系列共分五篇,内容分别为:第一部分 赛题内容第二部分 任务剖析第三部分 赛题模拟实现-离线数据抽取第四部分 赛题模拟实现-离线数据统计第五部分 赛题模拟实现-数据采集与实时计算第六部分 赛题模拟实现-数据可视化第一部分 竞赛内容赛项以大数据技术与应用为核心内容和工作基础,重点考查参赛选手基于Spark、Flink平台环境下,充分利用Spark Core、Spark SQL、Flume、Kafka
本系列共分五篇,内容分别为:
第一部分 竞赛内容
赛项以大数据技术与应用为核心内容和工作基础,重点考查参赛选手基于Spark、Flink平台环境下,充分利用Spark Core、Spark SQL、Flume、Kafka、Flink等技术的特点,综合软件开发相关技术,解决实际问题的能力,具体包括:
- 1. 掌握基于Spark的离线分析平台、基于Flink的实时分析平台,按照项目需求安装相关技术组件并按照需求进行合理配置;
- 2. 掌握基于Spark的离线数据抽取相关技术,完成指定数据的抽取并写入Hive分区表中;
- 3. 综合利用Spark Core、Spark SQL等技术,使用Scala开发语言,完成某电商系统数据的离线统计服务,包括销量前5商品统计、某月的总销售额统计、每个月的销售额统计、每个用户在线总时长统计,并将统计结果存入MySQL数据库中;
- 4. 综合利用Flume、Flink相关技术,使用Scala开发语言,完成将某电商系统的用户操作日志抽取到Kafka中,消费Kafka中的数据并计算商城在线人数,并统计该电商系统的UV与PV;
- 5. 综合运用HTML、CSS、JavaScript等开发语言,Vue.js前端技术,结合Echarts数据可视化组件,对MySQL中的数据进行可视化呈现;
- 6. 根据数据可视化结果,完成数据分析报告的编写;
(一) 竞赛内容构成
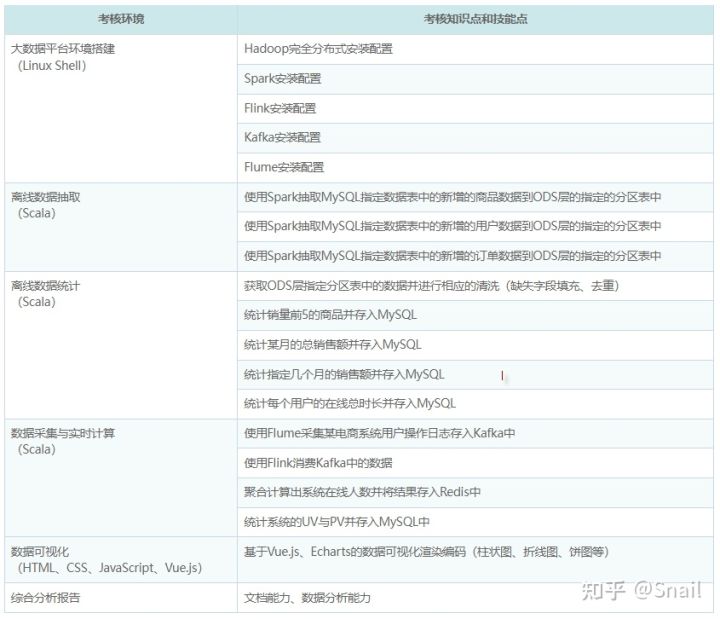
竞赛内容构成如下:

(二) 竞赛内容概述

任务说明
本项目要求完成离线电商数据统计分析,完成大数据平台环境搭建、离线数据抽取、离线数据统计、数据采集与实时计算、数据可视化及综合分析报告编写等工作。
提供的相关资源包括:
- 1.大数据环境搭建中需要用到的组件安装包
- 2.电商相关数据
- 3.大数据分析集群环境
- 4.离线数据抽取开发环境
- 5.离线数据统计开发环境
- 6.数据采集与实时计算开发环境
- 7.数据可视化开发环境
- 8.综合分析报告文档模板
任务一:大数据平台环境搭建
按照大数据分析平台需求,需要完成Hadoop完全分布式、Spark安装配置、Flink安装配置、Kafka安装配置、Flume安装配置。
任务二:离线数据抽取
按照要求使用Scala语言完成特定函数的编写,使用Spark抽取MySQL指定数据表中的新增的数据到ODS层的指定的分区表中。
任务三:离线数据统计
使用Scala语言编写程序获取ODS层指定分区表中的数据进行清洗,并完成销量前5的商品统计、某月的总销售额统计、指定月份的销售额统计、各用户在线总时长统计,并将统计后的数据存入MySQL数据库中。
任务四:数据采集与实时计算
启动业务系统,按照要求使用Flume将用户操作日志采集并存入Kafka中并使用Flink、Scala消费Kafka中的数据将其进行聚合计算出商城在线人数,将结果存入Redis中,并统计该系统的UV与PV将结果存入MySQL中。
任务五:数据可视化
编写前端Web界面,调用后台数据接口,使用Vue.js、Echarts完成数据可视化。
任务六:综合分析报告
根据项目要求,完成综合分析报告编写。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)