flink1.12接受Kafka数据写入hive中,hive客户端不能查询数据
1、代码如下StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.getConfig().registerKryoType(BusEventKafka.class);//e
·
1、代码如下
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.getConfig().registerKryoType(BusEventKafka.class);
//env.enableCheckpointing(1000 * 60 * 1);
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("auto.offset.reset","earliest");
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "2000");
//kafkaSource就是KafkaConsumer
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("example", new SimpleStringSchema(), props);
kafkaSource.setStartFromGroupOffsets();//设置从记录的offset开始消费,如果没有记录从auto.offset.reset配置开始消费
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, bsSettings);
String name = "myhive"; // Catalog名称,定义一个唯一的名称表示
String defaultDatabase = "yqfk"; // 默认数据库名称
String hiveConfDir = "/opt/hive/conf"; // hive-site.xml路径
//String hiveConfDir = "/Users/jinhuan/eclipse-workspace/flinkLearn";
String version = "3.1.2"; // Hive版本号
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
/*hive.getHiveConf().set("hive.exec.dynamic.partition", "true");
hive.getHiveConf().set("hive.exec.dynamic.partition.mode", "nonstrict");*/
tEnv.registerCatalog(name, hive);
tEnv.useCatalog(name);
tEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
tEnv.useDatabase(defaultDatabase);
tEnv.createTemporaryView("kafka_table", kafkaStream);
tEnv.executeSql("insert into bus_event_tmp01 select id,organization,user_name,address," +
"sex,card_no,event_time,safety_hat,door_position,temperature,temp_abnormal," +
"check_result,health_code,auth_method,direction,desc_info,wear_mask," +
"user_type,user_id,equip_id,hospital_no from kafka_table");2、建表语句
CREATE TABLE bus_event_tmp01(
id string,
organization string,
user_name string,
address string,
sex string,
card_no string,
event_time string,
safety_hat string,
door_position string,
temperature string,
temp_abnormal string,
check_result string,
health_code string,
auth_method string,
direction string,
desc_info string,
wear_mask string,
user_type string,
user_id string,
equip_id string
) partitioned by (hospital_no int) stored as orc TBLPROPERTIES (
'sink.partition-commit.delay'='0s',
'sink.partition-commit.policy.kind'='metastore'
);
3、问题描述:数据成功写入到hive中,hive客户端查询不到数据,写入的文件是以.开头的隐藏文件如下图:
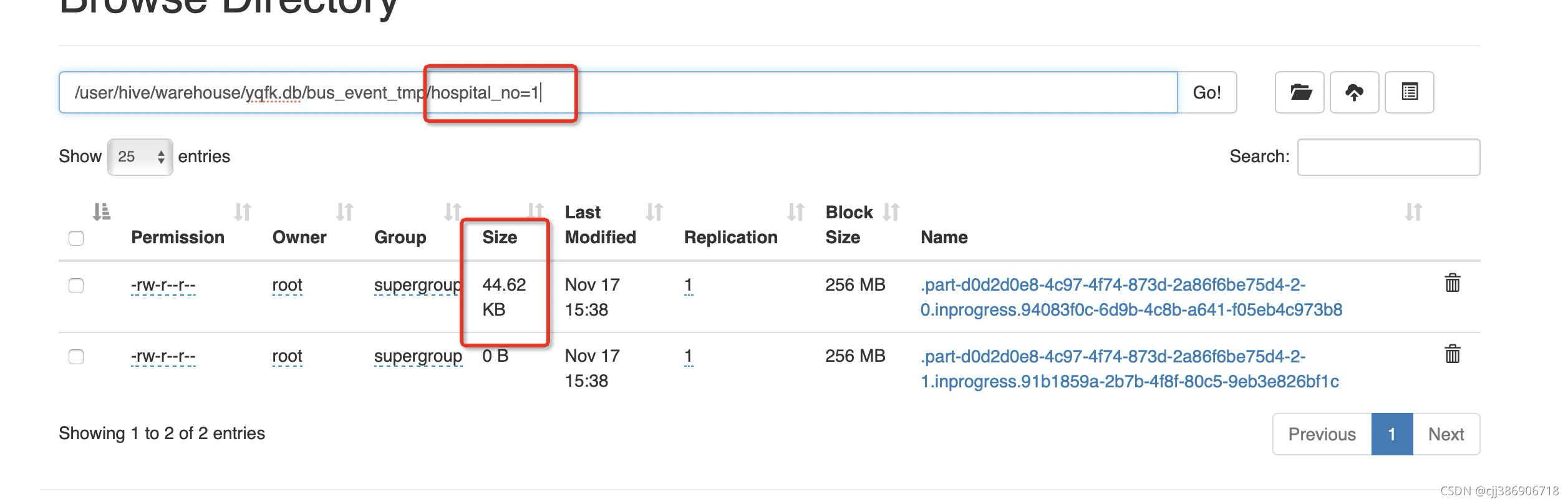
用下面命令查看文件状态文件全为空且处于inprogress状态
执行命令
hdfs dfs -count -h /user/hive/warehouse/path/*文件处于inprogress状体
4、最后解决方法: 添加以下代码数据成功写入
env.enableCheckpointing(3000);Flink将一直缓存从Kafka消费出来的数据,只有当Checkpoint 触发的时候,才把数据刷新到目标目录

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)