org.apache.kafka.clients.consumer.OffsetOutOfRangeException: Offsets out of range with no configured
1.现象spark程序报错后重新启动后报警22/05/05 10:26:54 ERROR executor.Executor: Exception in task 2.1 in stage 3.0 (TID 37)org.apache.kafka.clients.consumer.OffsetOutOfRangeException: Offsets out of range with no con
·
1.现象
spark程序报错后重新启动后报警
22/05/05 10:26:54 ERROR executor.Executor: Exception in task 2.1 in stage 3.0 (TID 37)
org.apache.kafka.clients.consumer.OffsetOutOfRangeException: Offsets out of range with no configured reset policy for partitions: {eventshistory-0=16914080}
at org.apache.kafka.clients.consumer.internals.Fetcher.parseCompletedFetch(Fetcher.java:987)
at org.apache.kafka.clients.consumer.internals.Fetcher.fetchedRecords(Fetcher.java:490)
at org.apache.kafka.clients.consumer.KafkaConsumer.pollForFetches(KafkaConsumer.java:1256)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1188)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1123)
at org.apache.spark.streaming.kafka010.InternalKafkaConsumer.poll(KafkaDataConsumer.scala:200)
at org.apache.spark.streaming.kafka010.InternalKafkaConsumer.get(KafkaDataConsumer.scala:129)
at org.apache.spark.streaming.kafka010.KafkaDataConsumer$class.get(KafkaDataConsumer.scala:36)
at org.apache.spark.streaming.kafka010.KafkaDataConsumer$NonCachedKafkaDataConsumer.get(KafkaDataConsumer.scala:218)
at org.apache.spark.streaming.kafka010.KafkaRDDIterator.next(KafkaRDD.scala:261)
at org.apache.spark.streaming.kafka010.KafkaRDDIterator.next(KafkaRDD.scala:229)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at com.tcl.realtime.app.AppEventHistory$$anonfun$main$1$$anonfun$2.apply(AppEventHistory.scala:94)
at com.tcl.realtime.app.AppEventHistory$$anonfun$main$1$$anonfun$2.apply(AppEventHistory.scala:74)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2121)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2121)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2.报错原因
log.retention.ms
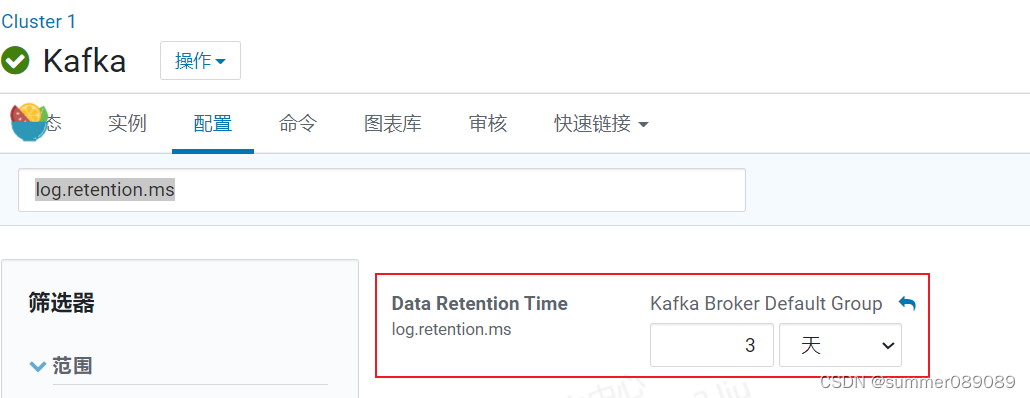
kafka的日志保存时间设置了是3天,因为程序报错中间没有运行,从新启动运行的时候从之前的地方开始消费的时候日志已经被kafka清空了。因此报警
3.报错解决
将spark从之前消费的记录删除。从最新的地方开始消费。相同数据下游只会入库一次。因此将未消费的数据重新采集到kafka对应主题中。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)