kafka文档(16)----0.10.1-Document-文档(8)-Design-kafka设计原理相关
4. DESIGN4.设计相关4.1 MotivationWe designed Kafka to be able to act as a unified platform for handling all the real-time data feeds a large company might have.To do this we had to think th
4. DESIGN
4.1 Motivation
4.1 目的
We designed Kafka to be able to act as a unified platform for handling all the real-time data feeds a large company might have. To do this we had to think through a fairly broad set of use cases.
It would have to have high-throughput to support high volume event streams such as real-time log aggregation.
It would need to deal gracefully with large data backlogs to be able to support periodic data loads from offline systems.
It also meant the system would have to handle low-latency delivery to handle more traditional messaging use-cases.
We wanted to support partitioned, distributed, real-time processing of these feeds to create new, derived feeds. This motivated our partitioning and consumer model.
Finally in cases where the stream is fed into other data systems for serving, we knew the system would have to be able to guarantee fault-tolerance in the presence of machine failures.
Supporting these uses led us to a design with a number of unique elements, more akin to a database log than a traditional messaging system. We will outline some elements of the design in the following sections.
kafka设计之初是用来作为处理大公司一般都会有的所有实时数据信息流的统一平台。为此,我们想了大量的使用场景。
需要高吞吐量,以支持实时日志收集产生的大量的事件流。
需要优雅的处理大量数据的备份,以支持周期性从离线系统下载数据。
同时需要处理低延迟传输,以处理更多传统消息使用场景。
我们还想要它支持分区的,分布式的,实时处理这些信息流,用来产生新的的信息流。这个场景促使我们创建了partitioning和consumer模型。
最后,还需要能够支持数据流可以导入其它数据系统,系统还需要保证容错性,可以毫不费力的应对机器损坏。
为了支持以上场景,kafka具备了大量的独特元素,相比传统消息而言,更加像数据库日志。下面会描述某些设计上的特征。
4.2 Persistence
Don't fear the filesystem!
Kafka relies heavily on the filesystem for storing and caching messages. There is a general perception that "disks are slow" which makes people skeptical that a persistent structure can offer competitive performance. In fact disks are both much slower and much faster than people expect depending on how they are used; and a properly designed disk structure can often be as fast as the network.
kafka由于需要缓存和存储消息,所以重度依赖文件系统。一般认为“磁盘很慢”,所以人们都怀疑持久化的数据结构能否提供有竞争力的性能。实际上,磁盘可能比人们期待的要快,也可能比人们期待的要慢,这取决于怎么来用它。合理的磁盘数据结构将比网络读写更快。
The key fact about disk performance is that the throughput of hard drives has been diverging from the latency of a disk seek for the last decade. As a result the performance of linear writes on a JBOD configuration with six 7200rpm SATA RAID-5 array is about 600MB/sec but the performance of random writes is only about 100k/sec—a difference of over 6000X. These linear reads and writes are the most predictable of all usage patterns, and are heavily optimized by the operating system. A modern operating system provides read-ahead and write-behind techniques that prefetch data in large block multiples and group smaller logical writes into large physical writes. A further discussion of this issue can be found in this ACM Queue article; they actually find that sequential disk access can in some cases be faster than random memory access!
磁盘性能的关键事实是过去十年间硬盘驱动的吞吐量已经远远超过了磁盘查询的延迟(译者注:应该是磁盘查询带来的延迟在性能上完全无法满足磁盘读写的吞吐量)。实际上,在6块JBOD配置为7200rpm SATA RAID-5阵列的磁盘上,线性写的速度可以高达600MB/s,而随机写的速度只有去取100k/s----差距竟然为6000倍。线性读写是所有使用场景中最有可能预测的,可以被操作系统深度优化。现代操作系统提供预读和后写技术:预读取大块数据,并将较小的逻辑写入合并为大的物理写入。有关这方面的讨论可以查看ACM Queue article。讨论结果是他们发现:顺序磁盘读写在某些情况下要比随机内存读写都要快。
To compensate for this performance divergence, modern operating systems have become increasingly aggressive in their use of main memory for disk caching. A modern OS will happily divert all free memory to disk caching with little performance penalty when the memory is reclaimed. All disk reads and writes will go through this unified cache. This feature cannot easily be turned off without using direct I/O, so even if a process maintains an in-process cache of the data, this data will likely be duplicated in OS pagecache, effectively storing everything twice.
Furthermore, we are building on top of the JVM, and anyone who has spent any time with Java memory usage knows two things:
- The memory overhead of objects is very high, often doubling the size of the data stored (or worse).
- Java garbage collection becomes increasingly fiddly and slow as the in-heap data increases.
为了弥补这种性能差距,现代操作系统越来越倾向于使用内存作为磁盘缓存。现代操作系统很乐意将所有可用内存作为磁盘的缓存,而释放这些内存时几乎没有性能损失。所有的磁盘读写都将通过这些统一的高速缓存。如果不使用直接I/O,就不能轻易禁用这个功能,因此,即使进程只是维护自己内部的缓存数据,这些数据在OS的page cache中有可能重复,有效的存储所有内容两次。
而且,kafka构建在JVM之上,使用java内存的人都知道两件事情:
1.对象的内存开销非常高,通常是存储数据的两倍(或者更高)
2.java的垃圾回收会随着堆内存的增长变得越来越紧张和缓慢
As a result of these factors using the filesystem and relying on pagecache is superior to maintaining an in-memory cache or other structure—we at least double the available cache by having automatic access to all free memory, and likely double again by storing a compact byte structure rather than individual objects. Doing so will result in a cache of up to 28-30GB on a 32GB machine without GC penalties. Furthermore, this cache will stay warm even if the service is restarted, whereas the in-process cache will need to be rebuilt in memory (which for a 10GB cache may take 10 minutes) or else it will need to start with a completely cold cache (which likely means terrible initial performance). This also greatly simplifies the code as all logic for maintaining coherency between the cache and filesystem is now in the OS, which tends to do so more efficiently and more correctly than one-off in-process attempts. If your disk usage favors linear reads then read-ahead is effectively pre-populating this cache with useful data on each disk read.
由于使用文件系统以及依靠page cache这两种方式优于维护内存或者其他数据结构的方式,因此,通过自动访问所有可用内存以及存储压缩的字节结构而不是单个的对象结构,至少有两倍可用的缓存。这样做的好处是:在一个32GB的机子上可能拥有高达28~32GB的缓存,而没有GC损失。而且,即使服务重启,这种缓存依然是温暖的(服务重启,老数据依然部分可用?),然而,进程内数据需要在内存中重建(10GB的缓存可能需要10分钟),或者需要启动时加载完全的冷缓存(这可能意味着糟糕的初始化性能)。这可能极大的简化代码,因为所有维护page cache以及文件系统的代码目前都在OS中,这要比每次启动进程加载数据更加直接有效。如果你在使用磁盘时更加倾向于线性读操作,那么每次预读取数据将会极大的提高数据的命中率。
This suggests a design which is very simple: rather than maintain as much as possible in-memory and flush it all out to the filesystem in a panic when we run out of space, we invert that. All data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel's pagecache.
This style of pagecache-centric design is described in an article on the design of Varnish here (along with a healthy dose of arrogance).
这就建议一个简单的设计:原来是内存中维护尽可能多的数据而且只有当耗尽内存时才将所有数据回刷到文件系统,现在我们要正好相反,所有的数据应当立刻写入文件系统上持久化日志而不是回刷到磁盘上。这就意味着,这些数据转移到内核的page cache中。
这种以page cache为中心的设计在这篇文章中有描述,文章中描述了Varnish设计方案。
Constant Time Suffices
The persistent data structure used in messaging systems are often a per-consumer queue with an associated BTree or other general-purpose random access data structures to maintain metadata about messages. BTrees are the most versatile data structure available, and make it possible to support a wide variety of transactional and non-transactional semantics in the messaging system. They do come with a fairly high cost, though: Btree operations are O(log N). Normally O(log N) is considered essentially equivalent to constant time, but this is not true for disk operations. Disk seeks come at 10 ms a pop, and each disk can do only one seek at a time so parallelism is limited. Hence even a handful of disk seeks leads to very high overhead. Since storage systems mix very fast cached operations with very slow physical disk operations, the observed performance of tree structures is often superlinear as data increases with fixed cache--i.e. doubling your data makes things much worse than twice as slow.
消息系统中持久化数据结构通常是每个consumer都有一个队列,队列采用相关联的BTree或者其他通用随机访问数据结构来维护消息的元数据。BTrees是最通用的数据结构,可以支持消息系统中大量的事务性或者非事务性语义。但是BTrees代价还是稍微有点高,Btree操作时间复杂度为O(logN)。一般来说,O(logN)和常量时间基本是等价的,但是对于磁盘操作来说并不是这样的。磁盘查询每个pop需要10ms,每次磁盘一次只能进行一次查询,这限制了并行处理能力。因此,即使很少的磁盘查询依然需要高负载。因为存储系统混合了非常快的缓存操作和非常慢的物理磁盘操作,所以树结构的查询性能通常是超级线性的,因为数据随着固定缓存增加而增加---两倍的数据会使查询性能降低不止两倍。
Intuitively a persistent queue could be built on simple reads and appends to files as is commonly the case with logging solutions. This structure has the advantage that all operations are O(1) and reads do not block writes or each other. This has obvious performance advantages since the performance is completely decoupled from the data size—one server can now take full advantage of a number of cheap, low-rotational speed 1+TB SATA drives. Though they have poor seek performance, these drives have acceptable performance for large reads and writes and come at 1/3 the price and 3x the capacity.
直观来讲,持久化队列可以建立在简单的读写文件上,因为这通常是日志解决方案。这种结构的优点是:所有操作都是O(1)的,读写操作并没有相互阻塞。这样有明显的性能优势,因为性能完全于数据尺寸无关了--一台server就可以利用多台廉价的、低转速的、1+TB SATA磁盘。尽管这样的磁盘查询性能比较糟糕,但是拥有大块数据的读写性能并且价格只为1/3和3倍的空间容量。
Having access to virtually unlimited disk space without any performance penalty means that we can provide some features not usually found in a messaging system. For example, in Kafka, instead of attempting to delete messages as soon as they are consumed, we can retain messages for a relatively long period (say a week). This leads to a great deal of flexibility for consumers, as we will describe.
访问没有限制的虚拟磁盘空间没有任何性能损耗,这意味着可以针对这个特征提供一些消息系统不常见的设计。例如,kafka中,不要一消费完就删除,而是可以将消息保存一段时间(一般来说为1周)。这对consumer来说,可以做大量灵活的事情,具体见下文描述。
4.3 Efficiency
We have put significant effort into efficiency. One of our primary use cases is handling web activity data, which is very high volume: each page view may generate dozens of writes. Furthermore, we assume each message published is read by at least one consumer (often many), hence we strive to make consumption as cheap as possible.
在性能方面,我们做了很多努力。一个主要的使用场景就是可以处理网络活动数据,这种数据量比较大。每个网页浏览都可能带来数十个写操作。而且,假定每条消息都会被每个consumer至少消费一次(通常每个consumer都会消费分多次),因此,需要使消费带来的资源消耗尽可能的小。
We have also found, from experience building and running a number of similar systems, that efficiency is a key to effective multi-tenant operations. If the downstream infrastructure service can easily become a bottleneck due to a small bump in usage by the application, such small changes will often create problems. By being very fast we help ensure that the application will tip-over under load before the infrastructure. This is particularly important when trying to run a centralized service that supports dozens or hundreds of applications on a centralized cluster as changes in usage patterns are a near-daily occurrence.
从以往经验中我们还发现,创建和运行多个相似的系统,性能是有效的多租户操作的关键点。如果下游基础构建服务因为应用中一些小的突变而很容易成为瓶颈的话,那么微小的改变有可能引发大问题。我们需要确保应用很快,在到达基础设施服务之前的负载下就可以翻转。这非常重要,当试图运行在集中式集群上支持支持成千上万应用的中心化服务时,使用场景可能每天都会变化。
We discussed disk efficiency in the previous section. Once poor disk access patterns have been eliminated, there are two common causes of inefficiency in this type of system: too many small I/O operations, and excessive byte copying.
The small I/O problem happens both between the client and the server and in the server's own persistent operations.
前面讨论了磁盘效率。即使糟糕的磁盘使用模式消除了,这种类型的系统还有两个常见的低效率原因:太多的小块数据I/O操作,过多的字节拷贝。
小块数据I/O问题发生在客户端、server端还有server自身持久化操作。
To avoid this, our protocol is built around a "message set" abstraction that naturally groups messages together. This allows network requests to group messages together and amortize the overhead of the network roundtrip rather than sending a single message at a time. The server in turn appends chunks of messages to its log in one go, and the consumer fetches large linear chunks at a time.
为了避免这个问题,我们的协议围绕着“消息集合”的概念:天然的将消息分组。这就允许网络请求可以将消息进行分组,合并发送请求而不是每次发送单个消息,以减少网络请求的开销。server可以一次追加大块消息到日志中,consumer也可以一次获取一大块消息。
This simple optimization produces orders of magnitude speed up. Batching leads to larger network packets, larger sequential disk operations, contiguous memory blocks, and so on, all of which allows Kafka to turn a bursty stream of random message writes into linear writes that flow to the consumers.
The other inefficiency is in byte copying. At low message rates this is not an issue, but under load the impact is significant. To avoid this we employ a standardized binary message format that is shared by the producer, the broker, and the consumer (so data chunks can be transferred without modification between them).
这种简单的优化将产生数量级的加速。批量处理将产生更大的网络包,更大的序列化磁盘操作,持续的内存阻塞等等,所有这些都使得kafka将随机消息的突发流转换为跟随consumers的线性写入。
另一个低效率操作是字节拷贝。消息速率比较低时这没有问题,但是负载大了话,影响还是比较大的。为了避免这个影响,我们采用了有producer、broker、consumer三者共享的二进制消息格式(因此数据块不用经过转换就可以在他们之间传输)。
The message log maintained by the broker is itself just a directory of files, each populated by a sequence of message sets that have been written to disk in the same format used by the producer and consumer. Maintaining this common format allows optimization of the most important operation: network transfer of persistent log chunks. Modern unix operating systems offer a highly optimized code path for transferring data out of pagecache to a socket; in Linux this is done with the sendfile system call.
broker维护的消息日志存放在不同的文件目录中,每个topic-partition占据一个目录,目录下的每个文件都是producer和consumer共用格式的一系列消息集合组成。维护通用的格式将支持最重要操作的优化:持久化日志的网络传输。现代操作系统提供高度优化的代码路径,用于将page cache的数据导入socket;linux系统中,这采用sendfile系统调用。
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
要想理解sendfile的效果,重要的是需要理解从文件传输数据到socket的通用数据路径:
1.操作系统先从磁盘将数据读入内核空间的page cache
2.应用从内核空间将数据读入用户空间的缓存
3.应用将数据将数据写回内核空间到socket缓存中
4.操作系统从socket缓存将数据拷贝到NIC缓存中,然后通过网络发送
This is clearly inefficient, there are four copies and two system calls. Using sendfile, this re-copying is avoided by allowing the OS to send the data from pagecache to the network directly. So in this optimized path, only the final copy to the NIC buffer is needed.
We expect a common use case to be multiple consumers on a topic. Using the zero-copy optimization above, data is copied into pagecache exactly once and reused on each consumption instead of being stored in memory and copied out to kernel space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection.
This combination of pagecache and sendfile means that on a Kafka cluster where the consumers are mostly caught up you will see no read activity on the disks whatsoever as they will be serving data entirely from cache.
For more background on the sendfile and zero-copy support in Java, see this article.
这很明显效率很低,有四次拷贝以及两次系统调用。使用sendfile,可以通过OS将数据从page cache直接发送到网络的方式来避免重拷贝,只有最后一步到NIC缓存的拷贝无法避免。
我们希望多个consumers使用同一个topic的通用使用场景。通过使用上面零拷贝的优化,数据只需要拷贝到page cache中一次,就可以每次消费时反复重用,而不必每次读取时都需要将数据保存到内存,然后再导出内核空间。
page cache和sendfile的结合使用意味着,kafka集群中,大部分consumers的读取操作都可以完全从缓存中读取,而不用读取磁盘上的数据。
更多有关java支持sendfile以及零拷贝的信息可以阅读这篇文章。
End-to-end Batch Compression
In some cases the bottleneck is actually not CPU or disk but network bandwidth. This is particularly true for a data pipeline that needs to send messages between data centers over a wide-area network. Of course, the user can always compress its messages one at a time without any support needed from Kafka, but this can lead to very poor compression ratios as much of the redundancy is due to repetition between messages of the same type (e.g. field names in JSON or user agents in web logs or common string values). Efficient compression requires compressing multiple messages together rather than compressing each message individually.
某些情况下,瓶颈实际上不是CPU或者磁盘而是网络带宽。这对于在建立在广域网之上的数据中心之间传输消息的数据管道来说,是非常正确的。当然,用户可以在没有kafka任何支持的情况下压缩消息,但是有可能导致比较差的压缩比,因为大部分冗余是相同消息之间重复(例如,JSON的字符名字或者web日志中用户代理或者通用字符串)。
高效压缩要求一次压缩多条消息而不是一次压缩一条消息。
Kafka supports this by allowing recursive message sets. A batch of messages can be clumped together compressed and sent to the server in this form. This batch of messages will be written in compressed form and will remain compressed in the log and will only be decompressed by the consumer.
Kafka supports GZIP, Snappy and LZ4 compression protocols. More details on compression can be found here.
4.4 The Producer
Load balancing
The producer sends data directly to the broker that is the leader for the partition without any intervening routing tier. To help the producer do this all Kafka nodes can answer a request for metadata about which servers are alive and where the leaders for the partitions of a topic are at any given time to allow the producer to appropriately direct its requests.
Asynchronous send
Batching is one of the big drivers of efficiency, and to enable batching the Kafka producer will attempt to accumulate data in memory and to send out larger batches in a single request. The batching can be configured to accumulate no more than a fixed number of messages and to wait no longer than some fixed latency bound (say 64k or 10 ms). This allows the accumulation of more bytes to send, and few larger I/O operations on the servers. This buffering is configurable and gives a mechanism to trade off a small amount of additional latency for better throughput.
Details on configuration and the api for the producer can be found elsewhere in the documentation.
4.5 The Consumer
kafka消费者通过“fetch”请求partition的leader以获取数据。consumer在每次请求中指定日志offset,然后就会收到从这个位置开始的大块日志。consumer这样就可以灵活的控制消费的位置,也就可以重复消费数据。
Push vs. pull
An initial question we considered is whether consumers should pull data from brokers or brokers should push data to the consumer. In this respect Kafka follows a more traditional design, shared by most messaging systems, where data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as Scribe and Apache Flume, follow a very different push-based path where data is pushed downstream. There are pros and cons to both approaches. However, a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately, in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems. Previous attempts at building systems in this fashion led us to go with a more traditional pull model.
我们考虑的一个初始问题是:consumer是应该从brokers拉数据还是brokers将数据推向consumer。kafka在这个方面遵循更加传统的设计,就像大部分消息系统那样,producer将数据推向broker,然后consumer从broker拉取数据。某些日志集中系统,就像Scribe和Apache Flume,这些都是采用一种不同于此的基于推送的方式:即将数据推向下游。这两种方法各有利弊。然而,基于推送的系统很难处理consumers和brokers之间数据传输速率不匹配的问题。consumer一般的目标是尽可能快的消费消息。但是不幸的是,在一个推系统中,这就意味着当consumer的速率低于生产者时(实际上服务攻击拒绝),consumer是过载的。基于拉的系统有更好的特征:consumer可能会落后于生产者并尽可能的赶上。这可以通过某些退避协议改善,消费者可以通过这些协议指示它已经过载了,但是获得传输速率以获取完全利用consumer(从来不是过载使用),consumer比看起来的要麻烦很多。以前以这种方式创建系统的尝试使得我们使用一种更加传统的模式。
Another advantage of a pull-based system is that it lends itself to aggressive batching of data sent to the consumer. A push-based system must choose to either send a request immediately or accumulate more data and then send it later without knowledge of whether the downstream consumer will be able to immediately process it. If tuned for low latency, this will result in sending a single message at a time only for the transfer to end up being buffered anyway, which is wasteful. A pull-based design fixes this as the consumer always pulls all available messages after its current position in the log (or up to some configurable max size). So one gets optimal batching without introducing unnecessary latency.
基于拉的系统另一个优势是积极的批处理发送到consumer的数据。基于推的系统必须选择要么是每次立即发送一条消息要么是积累更多的消息,然后在不知道下游consumer是否能够立即处理它的情况下就发送。如果想要更低的延迟,则需要每次发送一条消息,可以减少缓存时间,但是这样对于网络消耗是浪费的。基于拉的设计修正了这一点,consumer总会尽可能拉取当前消费位置之后更多的消息(或者是某些配置的最大值)。因此,没有引入更多不必要的延迟就可以获得最佳的批处理性能。
The deficiency of a naive pull-based system is that if the broker has no data the consumer may end up polling in a tight loop, effectively busy-waiting for data to arrive. To avoid this we have parameters in our pull request that allow the consumer request to block in a "long poll" waiting until data arrives (and optionally waiting until a given number of bytes is available to ensure large transfer sizes).
You could imagine other possible designs which would be only pull, end-to-end. The producer would locally write to a local log, and brokers would pull from that with consumers pulling from them. A similar type of "store-and-forward" producer is often proposed. This is intriguing but we felt not very suitable for our target use cases which have thousands of producers. Our experience running persistent data systems at scale led us to feel that involving thousands of disks in the system across many applications would not actually make things more reliable and would be a nightmare to operate. And in practice we have found that we can run a pipeline with strong SLAs at large scale without a need for producer persistence.
基于拉的系统缺陷是如果broker没有数据,则consumer可能会频繁的循环中轮询,只有在这种忙等待中才能有效等待消息到来。为了避免这种情况,我们在拉取请求中设置了这种参数,即可以允许consumer请求长时间的阻塞在等待中,直到有数据到来(也可以选择等待某个给定数量的字节数,以保证获取大德传输尺寸)。
你可以想想其他可能的设计:只能拉,端到端。生产者可能写入本地日志,broker主动拉取这些日志,然后consumers从brokers拉取日志。通常提出类似类型的“存储-发送”的生产者。这很有趣,但是可以想一下,如果我们有成千上万个producers,这不是特别合适。我们在运行大规模持久化数据系统方面的经验告诉我们:在许多应用中涉及到系统中成千上万个磁盘的操作不会使系统更健壮,反而对操作来说是个噩梦。实际上,我们可以发现运行大规模的具有SALs的管道根本不需要生产者持久化。
Consumer Position
Most messaging systems keep metadata about what messages have been consumed on the broker. That is, as a message is handed out to a consumer, the broker either records that fact locally immediately or it may wait for acknowledgement from the consumer. This is a fairly intuitive choice, and indeed for a single machine server it is not clear where else this state could go. Since the data structures used for storage in many messaging systems scale poorly, this is also a pragmatic choice--since the broker knows what is consumed it can immediately delete it, keeping the data size small.
追踪消费的位置,对于消息系统来说是一个关键的性能点。
大多数消息系统在broker保存了消费的消息的元数据。就是说,当消息发向consumer,broker或者是立刻在本地记录下这个事实或者是等待来自consumer的确认消息。这是个相当直观的选择,事实上对于单个机器server来说,并不清楚将消费状态存储在其他什么地方。因为很多消息系统中用来存储的数据结构扩展性很差,所以这也是务实的选择--因为broker直到哪些已经消费了,并且可以立即删掉它,以保持数据尺寸比较小。
What is perhaps not obvious is that getting the broker and consumer to come into agreement about what has been consumed is not a trivial problem. If the broker records a message as consumed immediately every time it is handed out over the network, then if the consumer fails to process the message (say because it crashes or the request times out or whatever) that message will be lost. To solve this problem, many messaging systems add an acknowledgement feature which means that messages are only marked as sent not consumed when they are sent; the broker waits for a specific acknowledgement from the consumer to record the message as consumed. This strategy fixes the problem of losing messages, but creates new problems. First of all, if the consumer processes the message but fails before it can send an acknowledgement then the message will be consumed twice. The second problem is around performance, now the broker must keep multiple states about every single message (first to lock it so it is not given out a second time, and then to mark it as permanently consumed so that it can be removed). Tricky problems must be dealt with, like what to do with messages that are sent but never acknowledged.
不明显的性能点是,让broker和consumer对于哪些消息已经消费了达成一致并不是一个小事情。如果broker在每次消息通过网络发向consumer时就记录该消息已经被消费了,那么如果consumer处理消息失败(即因为程序崩溃或者请求超时或者其他什么原因),那么这条消息就丢失了。为了解决这个问题,很多消息系统增加了确认的特征,即只有当消息发送未被消费时就打上标记。这个策略解决了丢失消息的问题,但是又引发了新问题。第一,如果consumer处理了消息,但是在发送确认之前失效了,那么消息就会被消费两次。第二是性能问题,broker需要保存每个消息的多个状态(首先目的是为了锁住消息以防发出两次。然后标记为永久消费,就可以删除了)。还有一些小问题需要处理,如果消息发出了但是没有确认的话怎么办。
Kafka handles this differently. Our topic is divided into a set of totally ordered partitions, each of which is consumed by exactly one consumer within each subscribing consumer group at any given time. This means that the position of a consumer in each partition is just a single integer, the offset of the next message to consume. This makes the state about what has been consumed very small, just one number for each partition. This state can be periodically checkpointed. This makes the equivalent of message acknowledgements very cheap.
There is a side benefit of this decision. A consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but turns out to be an essential feature for many consumers. For example, if the consumer code has a bug and is discovered after some messages are consumed, the consumer can re-consume those messages once the bug is fixed.
kafka可以用不同方式处理这些问题。我们的topic划分成完全有序的partitions的集合,每个partition都可以被每个正在订阅的consumer group的consumer在任意时刻准确的消费。这就意味着,每个partition的consumer的位置仅仅是一个单独的整型数据-用来指明下一条待消费消息的offset。这就使得记录哪些消息已经消费的状态花费很少的资源,只是每个partition一个数字。这个状态可以周期性的检查。这就使消息确认也变得很廉价。
这个决定有一个附带好处。consumer可以有目的的回退到旧的offset并重新消费数据。这其实违反了队列的一般抽象,但是对于很多consumers来说证明是一个基本的特征。例如,如果consumer代码有bug,并且发现某些消息已经消费过了,那么consumer可以在修复bug之后选择重新消费消息。
Offline Data Load
In the case of Hadoop we parallelize the data load by splitting the load over individual map tasks, one for each node/topic/partition combination, allowing full parallelism in the loading. Hadoop provides the task management, and tasks which fail can restart without danger of duplicate data—they simply restart from their original position.
可扩展性以及持久化提供了这种consumers的可能性:仅仅周期性消费行为,诸如批量数据加载--加载数据到诸如Hadoop或者关系型数据仓库的离线系统。
在Hadoop这种使用场景中,我们可以并行处理数据,通过将负载分化到单独的map任务中,每个任务一个节点/topic/partition,这样可以在加载时完全并行处理。Hadoop提供了任务管理,失败的任务可以重启,而且没有丢失数据的风险--他们可以简单从他们最初的位置重启。
4.6 Message Delivery Semantics
Now that we understand a little about how producers and consumers work, let's discuss the semantic guarantees Kafka provides between producer and consumer. Clearly there are multiple possible message delivery guarantees that could be provided:
- At most once—Messages may be lost but are never redelivered.
- At least once—Messages are never lost but may be redelivered.
- Exactly once—this is what people actually want, each message is delivered once and only once.
现在知道了一点consumers和producers是如何工作的,让我们讨论一下语义保证吧。kafka提供producer以及consumer的保证。清楚的是,有多种可能的消息传输保证可以提供:
- 最多一次:消息可能丢失并从来不会重发
- 最少一次:消息从来不丢失但是可能重发
- 准确一次:这才是人们想要的,每条消息只传输一次而且仅有一次
It's worth noting that this breaks down into two problems: the durability guarantees for publishing a message and the guarantees when consuming a message.
Many systems claim to provide "exactly once" delivery semantics, but it is important to read the fine print, most of these claims are misleading (i.e. they don't translate to the case where consumers or producers can fail, cases where there are multiple consumer processes, or cases where data written to disk can be lost).
值得注意的是,这分为两个问题:发布消息的可用性保证以及消费消息的保证。
很多系统声称可以提供“准确一次”的传输语义,但是重要的是阅读详细指导,大多数声称都是误导(例如,他们没有考虑到consumer或者producers失败的情况,以及多个consumer进程或者数据写入磁盘可能失败的情况)。
Kafka's semantics are straight-forward. When publishing a message we have a notion of the message being "committed" to the log. Once a published message is committed it will not be lost as long as one broker that replicates the partition to which this message was written remains "alive". The definition of alive as well as a description of which types of failures we attempt to handle will be described in more detail in the next section. For now let's assume a perfect, lossless broker and try to understand the guarantees to the producer and consumer. If a producer attempts to publish a message and experiences a network error it cannot be sure if this error happened before or after the message was committed. This is similar to the semantics of inserting into a database table with an autogenerated key.
kafka的语义是直接了当的。当发布消息时,有一个“提交”日志的概念。一旦发布的消息提交到partition了,只要备份partition的broker依然有存活的,则消息不会丢失。下一节将描述各种类型的失败情况以及活跃状况,以及我们是如何处理这些失败情况。现在我们假设完美的、无损的broker,用来尝试理解producer以及consumer的保证。如果producer尝试发布消息并遇到网络错误,它不能确定这个错误是发生在消息提交之前还是提交之后。这类似于使用自动生成的键插入数据库的语义。
These are not the strongest possible semantics for publishers. Although we cannot be sure of what happened in the case of a network error, it is possible to allow the producer to generate a sort of "primary key" that makes retrying the produce request idempotent. This feature is not trivial for a replicated system because of course it must work even (or especially) in the case of a server failure. With this feature it would suffice for the producer to retry until it receives acknowledgement of a successfully committed message at which point we would guarantee the message had been published exactly once. We hope to add this in a future Kafka version.
Not all use cases require such strong guarantees. For uses which are latency sensitive we allow the producer to specify the durability level it desires. If the producer specifies that it wants to wait on the message being committed this can take on the order of 10 ms. However the producer can also specify that it wants to perform the send completely asynchronously or that it wants to wait only until the leader (but not necessarily the followers) have the message.
这些不是发布商最强的语义。尽管不能确定网络错误时会发生什么,允许producer产生一种“主键”,使得重试产生请求幂(即保证唯一性的东西,幂等性)。这个特征对于备份系统来说不是个小事情,因为即使遇到server失败的场景也依然能够工作。利用这种特征,生产者不断重试直到收到成功提交的确认消息,在这个时间点,我们可以保证消息只发布一次。我们希望在将来的kafka版本中添加这个这个特征。
不是所有消息都需要这么强的保证。对于延迟性敏感的语义,允许producers指定需要的持久化水平。如果生产者指定它希望等待消息被提交,可以指定为10ms的数量级。然而,producer也可以指定它想完全的异步发送消息或者想完全等待leader写入消息的确认消息(不需要指定followers)。
Now let's describe the semantics from the point-of-view of the consumer. All replicas have the exact same log with the same offsets. The consumer controls its position in this log. If the consumer never crashed it could just store this position in memory, but if the consumer fails and we want this topic partition to be taken over by another process the new process will need to choose an appropriate position from which to start processing. Let's say the consumer reads some messages -- it has several options for processing the messages and updating its position.
现在让我们描述一下consumer端的语义。所有备份都需要相同的offsets具有相同的日志。consumer控制日志中的消费位置。如果consumer从来不崩溃,则不需要存储这个位置。但是一旦consumer失败或者我们想要这个topic partition可以由其他进程消费,那么新进程需要选择合适的位置开始消费。让我们说消费者读取一些消息---如何处理消息以及更新它的消费位置有一些选择:
1.It can read the messages, then save its position in the log, and finally process the messages. In this case there is a possibility that the consumer process crashes after saving its position but before saving the output of its message processing. In this case the process that took over processing would start at the saved position even though a few messages prior to that position had not been processed. This corresponds to "at-most-once" semantics as in the case of a consumer failure messages may not be processed.
1.先阅读这些消息,然后保存日志中位置,最后处理这些消息。这种情况下,可能会出现保存读取位置之后但是在保存消息处理结果之前的时候consumer进程崩溃。这种情况下,进程重启处理过程,从保存的位置开始,即使在这之前的某些消息没有真正处理。这对应于“最多一次”的语义,consumer失败的情况下某些消息没有被处理。
2.It can read the messages, process the messages, and finally save its position. In this case there is a possibility that the consumer process crashes after processing messages but before saving its position. In this case when the new process takes over the first few messages it receives will already have been processed. This corresponds to the "at-least-once" semantics in the case of consumer failure. In many cases messages have a primary key and so the updates are idempotent (receiving the same message twice just overwrites a record with another copy of itself)。
2.先阅读消息,处理消息,最后保存位置。这种情况下,可能会出现处理消息之后但是在保存位置之前consumer进程崩溃。这种情况下,当新进程重新读取最初的一些消息时,其实这些消息已经处理过了。这对应于“最少一次”语义,很多情况下,消息是有主键的,因此更新是幂等的(接收到相同消息两次只是会重写)。
3.So what about exactly once semantics (i.e. the thing you actually want)? The limitation here is not actually a feature of the messaging system but rather the need to co-ordinate the consumer's position with what is actually stored as output. The classic way of achieving this would be to introduce a two-phase commit between the storage for the consumer position and the storage of the consumers output. But this can be handled more simply and generally by simply letting the consumer store its offset in the same place as its output. This is better because many of the output systems a consumer might want to write to will not support a two-phase commit. As an example of this, our Hadoop ETL that populates data in HDFS stores its offsets in HDFS with the data it reads so that it is guaranteed that either data and offsets are both updated or neither is. We follow similar patterns for many other data systems which require these stronger semantics and for which the messages do not have a primary key to allow for deduplication.
3.因此,什么才是准确的一次语义?这个限制实际上并不是消息系统的特征而是需要将consumer的位置和输出实际存储之间相协调的问题。解决这个问题的经典方式是在consumer位置存储和consumer输出之间如入两段提交方式。但是更加简单和通用的方式是通过consumer自己在输出的位置存储自己的offset。这种方式更好是因为consumer想要写入的很多输出系统并不支持两段提交。例如,在HDFS中填充数据的Hadoop ETL将offsets存储到其读取数据的HDFS中,从而保证数据和offsets要么都被更新要么都不更新。对于需要这些更强语义并且消息不具有允许重复消除的主键的其他系统来说,我们遵循类似的语义。
So effectively Kafka guarantees at-least-once delivery by default and allows the user to implement at most once delivery by disabling retries on the producer and committing its offset prior to processing a batch of messages. Exactly-once delivery requires co-operation with the destination storage system but Kafka provides the offset which makes implementing this straight-forward.
因此kafka默认情况下可以有效的保证至少一次发送,允许用户通过设置producer不进行重试并在处理一批消息之前不提交它的offset来保证至多一次的发送。准确的一次发送要求目的存储系统之间的协作。但是kafka提供的offset使得可以直接实现这种需求。
4.7 Replication
Kafka replicates the log for each topic's partitions across a configurable number of servers (you can set this replication factor on a topic-by-topic basis). This allows automatic failover to these replicas when a server in the cluster fails so messages remain available in the presence of failures.
Other messaging systems provide some replication-related features, but, in our (totally biased) opinion, this appears to be a tacked-on thing, not heavily used, and with large downsides: slaves are inactive, throughput is heavily impacted, it requires fiddly manual configuration, etc. Kafka is meant to be used with replication by default—in fact we implement un-replicated topics as replicated topics where the replication factor is one.
kafka为每个topic的partitions都提供可配置的备份数。(你可以设置基于topic的备份数目)。这就允许自动的故障转移到这些备份,当集群中的server失败,这些消息依然可用。
其他消息提供一些备份相关的特征,但是,在我们的观点中,这似乎是勉强加上的东西,并没有大量使用,并且有大量的副作用:slaves并不是活跃的,吞吐量受到严重影响,它需要轻松的人工配置。kafka打算默认使用备份-实际上我们将未备份topic的备份数设置为1.
The unit of replication is the topic partition. Under non-failure conditions, each partition in Kafka has a single leader and zero or more followers. The total number of replicas including the leader constitute the replication factor. All reads and writes go to the leader of the partition. Typically, there are many more partitions than brokers and the leaders are evenly distributed among brokers. The logs on the followers are identical to the leader's log—all have the same offsets and messages in the same order (though, of course, at any given time the leader may have a few as-yet unreplicated messages at the end of its log).
Followers consume messages from the leader just as a normal Kafka consumer would and apply them to their own log. Having the followers pull from the leader has the nice property of allowing the follower to naturally batch together log entries they are applying to their log.
备份的单元是topic partition。在没有失败的情况下,kafka中的每个partition都只有一个leader,0个或者更多的followers。备份的总数包括leader本身。所有读写操作时leader完成的。一般来说,partitions的数目多于brokers,leaders也就分布在不同的brokers上。followers上的日志和leaders上的日志相同-所有相同topic partition都有相同的offsets和messages,并且顺序相同(然而,任意时刻来看的话,leader可能有某些消息是没有备份的)。
followers从leader消费消息,就像普通的kafka consumer一样,然后将消费的消息追加到日志中。为了让followers有良好的备份性能,允许follower可以批量获取日志并且保存日志。
As with most distributed systems automatically handling failures requires having a precise definition of what it means for a node to be "alive". For Kafka node liveness has two conditions
- A node must be able to maintain its session with ZooKeeper (via ZooKeeper's heartbeat mechanism)
- If it is a slave it must replicate the writes happening on the leader and not fall "too far" behind
1.节点必须维护同zookeeper之间的会话(通过zookeeper的心跳机制)
2.如果某个节点是slave,它必须从leader备份数据,并且不能落后leader太远
We refer to nodes satisfying these two conditions as being "in sync" to avoid the vagueness of "alive" or "failed". The leader keeps track of the set of "in sync" nodes. If a follower dies, gets stuck, or falls behind, the leader will remove it from the list of in sync replicas. The determination of stuck and lagging replicas is controlled by the replica.lag.time.max.ms configuration.
In distributed systems terminology we only attempt to handle a "fail/recover" model of failures where nodes suddenly cease working and then later recover (perhaps without knowing that they have died). Kafka does not handle so-called "Byzantine" failures in which nodes produce arbitrary or malicious responses (perhaps due to bugs or foul play).
节点必须满足这两个条件才能是出于"in sync",以避免“活着”或者“失败”的模糊性。leaders必须保持追踪“in sync”节点的集合。如果某个followers死掉了,或者阻塞了,或者落后太多日志,leader将从sync备份列表中删除这个followers。阻塞或者落后备份节点是由replica.lag.time.max.ms配置控制的。
在分布式系统中,我们只能尝试处理故障的“失败/恢复”模式,其节点突然停止工作,然后又恢复(可能不知道它们实际上已经死过了)。kafka不能处理所谓的“拜占庭”失败情况,其节点产生任意或者恶意的回应(可能由于错误或者犯规)。
A message is considered "committed" when all in sync replicas for that partition have applied it to their log. Only committed messages are ever given out to the consumer. This means that the consumer need not worry about potentially seeing a message that could be lost if the leader fails. Producers, on the other hand, have the option of either waiting for the message to be committed or not, depending on their preference for tradeoff between latency and durability. This preference is controlled by the acks setting that the producer uses.
The guarantee that Kafka offers is that a committed message will not be lost, as long as there is at least one in sync replica alive, at all times.
Kafka will remain available in the presence of node failures after a short fail-over period, but may not remain available in the presence of network partitions.
只有所有同步备份节点都已经将消息写入日志,消息才能认为是“提交了”。只有提交的消息才能发往消费者。这意味着consumer不需要担心:如果leader挂掉,消息是否会丢失。另外,Producers可以选择等待消息被提交或者不等待,这取决于在延迟与可用性之间的折衷倾向。这种倾向由producer设置的ack控制。
kafka提供的这种保证是:任意时刻,只要至少有一个in sync备份或者,提交的消息就不会丢失。
kafka在短暂的故障转移期间之后将保持可用,但是在网络分区出问题时可能无法使用。
Replicated Logs: Quorums, ISRs, and State Machines (Oh my!)
A replicated log models the process of coming into consensus on the order of a series of values (generally numbering the log entries 0, 1, 2, ...). There are many ways to implement this, but the simplest and fastest is with a leader who chooses the ordering of values provided to it. As long as the leader remains alive, all followers need to only copy the values and ordering the leader chooses.
kafka分区的核心是日志备份。备份日志是大多数分布式系统的一个基本特征,而且有很多方法实现备份。备份日志被其他系统用来作为基本特征或者以状态机的方式实现另一个分布式系统。
日志备份模拟一系列值按照顺序达成一致的过程(一般对日志进行编号)。有很多办法实现这一点,但是最简单易记最快的方法是使用leader,leader来确定这些值的顺序。只要leader一直活着,所有followers只需要按照leader的编号复制消息。
Of course if leaders didn't fail we wouldn't need followers! When the leader does die we need to choose a new leader from among the followers. But followers themselves may fall behind or crash so we must ensure we choose an up-to-date follower. The fundamental guarantee a log replication algorithm must provide is that if we tell the client a message is committed, and the leader fails, the new leader we elect must also have that message. This yields a tradeoff: if the leader waits for more followers to acknowledge a message before declaring it committed then there will be more potentially electable leaders.
If you choose the number of acknowledgements required and the number of logs that must be compared to elect a leader such that there is guaranteed to be an overlap, then this is called a Quorum.
当然,如果leaders没有失败,我们不需要followers。当leader确定死掉的时候,我们需要重新从followers之中选择一个新的leader出来。但是followers它们自己可能落后很多或者崩溃了,所以我们需要保证我们选择的是状态最新的follower。日志备份的基本保证必须提供:如果我们告诉客户端一条消息已经提交了,那么即使leader挂掉了,新的leader必须有这条消息。这就会产生折衷:如果leader等待越多的followers确认提交消息,那么就有更多的followers可以被选为新leader。
确认收到最新消息的followers范围和用来选举leader的followers范围,必须保证这两个followers范围有重叠,才能正确选出所需要的leader。
A common approach to this tradeoff is to use a majority vote for both the commit decision and the leader election. This is not what Kafka does, but let's explore it anyway to understand the tradeoffs. Let's say we have 2f+1 replicas. If f+1 replicas must receive a message prior to a commit being declared by the leader, and if we elect a new leader by electing the follower with the most complete log from at least f+1 replicas, then, with no more than f failures, the leader is guaranteed to have all committed messages. This is because among any f+1 replicas, there must be at least one replica that contains all committed messages. That replica's log will be the most complete and therefore will be selected as the new leader. There are many remaining details that each algorithm must handle (such as precisely defined what makes a log more complete, ensuring log consistency during leader failure or changing the set of servers in the replica set) but we will ignore these for now.
这种折衷的通用方法是使用大多数投票机制:在提交决议和leader选举中。这个不是kafka来做的,但是我们可以探讨它以理解这种折衷。来看一下吧,如果我们有2f+1个备份。如果leader声明消息提交决议之前,必须有f+1个备份已经收到消息,那么如果我们从至少f+1个备份的具有最完整日志follower之中选举新leader,那么故障备份数不能操作f,新leader才能保证拥有所有已经提交的消息。这是因为,在任何f+1备份节点之间,必须至少有一个备份节点有所有已经提交的消息。备份节点的日志必须是最完整的,才能被选为新leader。每个算法必须处理很多细节信息(诸如,必须定义什么叫更加完整的日志,必须保证leader失效期间日志的一致性,或者改变备份集合的servers列表),但是我们忽略了这些细节信息。
This majority vote approach has a very nice property: the latency is dependent on only the fastest servers. That is, if the replication factor is three, the latency is determined by the faster slave not the slower one.
There are a rich variety of algorithms in this family including ZooKeeper's Zab, Raft, and Viewstamped Replication. The most similar academic publication we are aware of to Kafka's actual implementation is PacificA from Microsoft.
大多数选举方法有一个非常好的特征:延迟依赖于最快的servers。即,如果备份数是3个,那么延迟取决于最快的slave而非最慢的。
选举算法相当多,包括Zookeeper的Zab算法,Raft算法,以及Viewstamped Replication。与kafka最相似的学术发表是微软的PacificA 。
The downside of majority vote is that it doesn't take many failures to leave you with no electable leaders. To tolerate one failure requires three copies of the data, and to tolerate two failures requires five copies of the data. In our experience having only enough redundancy to tolerate a single failure is not enough for a practical system, but doing every write five times, with 5x the disk space requirements and 1/5th the throughput, is not very practical for large volume data problems. This is likely why quorum algorithms more commonly appear for shared cluster configuration such as ZooKeeper but are less common for primary data storage. For example in HDFS the namenode's high-availability feature is built on a majority-vote-based journal, but this more expensive approach is not used for the data itself.
多数投票的缺点是:他不能接受太多的失败,否则没有可选的leaders。如果应对一个失败,它需要三份数据备份,要想应对两个失败,需要5份数据备份。我们的经验是,只能具有足够的数据备份冗余却仅仅应对一个失败,对于大多数实际系统来说是不够的,每次都需要写5次,需要5倍的磁盘空间,而只有1/5的吞吐量,对于大数据问题来说,是非常不实际的。这也可能是为什么仲裁算法在共享集群配置系统中例如zookeeper更加常见,而不是在数据存储系统中更常见。例如,HDFS中,namenode的高性能特征基于大多数投票算法上,但是这种开销更大的方法没有用于数据存储本身。
Kafka takes a slightly different approach to choosing its quorum set. Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted to ZooKeeper whenever it changes. Because of this, any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka's usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.
kafka在选择它的仲裁集合方面稍有不同。没有使用大多数投票,kafka动态的维护一个in-sync备份(ISR)的 集合,用来和leader保持一致。只有这个集合的成员才有权利竞选leader。直到所有in-sync的备份成员都收到消息了,这条消息才认为是提交到kafka了。这个ISR集合无论何时发生变化,都会更新到zookeeper中。因为这,ISR中的任何备份有权利竞选leader。这对kafka使用模型来说是非常重要的特征,kafka维护很多partitions并保证leader负载均衡是非常重要的。有了这个ISR模型,以及f+1个备份,kafka topic可以应对f个错误而不没有丢失提交消息风险。
For most use cases we hope to handle, we think this tradeoff is a reasonable one. In practice, to tolerate f failures, both the majority vote and the ISR approach will wait for the same number of replicas to acknowledge before committing a message (e.g. to survive one failure a majority quorum needs three replicas and one acknowledgement and the ISR approach requires two replicas and one acknowledgement). The ability to commit without the slowest servers is an advantage of the majority vote approach. However, we think it is ameliorated by allowing the client to choose whether they block on the message commit or not, and the additional throughput and disk space due to the lower required replication factor is worth it.
我们希望可以应对大多数使用场景,我们认为这种折衷是合理的。世纪钟,为了容错,大多数选举和ISR备份方法都需要在提交消息之前等待相同数量的备份发出确认消息(例如,为了应对失败情况,大多数选举仲裁需要三个备份和一个确认,ISR方法需要两个备份以及一个确认)。不受最慢服务器影响的提交能力是大多数投票方法的优势。然而,我们认为,通过允许客户端选择它们是否在提交消息时阻塞,并且备份机制所附带的吞吐量以及磁盘损耗,这是值得的。
Another important design distinction is that Kafka does not require that crashed nodes recover with all their data intact. It is not uncommon for replication algorithms in this space to depend on the existence of "stable storage" that cannot be lost in any failure-recovery scenario without potential consistency violations. There are two primary problems with this assumption. First, disk errors are the most common problem we observe in real operation of persistent data systems and they often do not leave data intact. Secondly, even if this were not a problem, we do not want to require the use of fsync on every write for our consistency guarantees as this can reduce performance by two to three orders of magnitude. Our protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
另一个重要的设计就是:kafka不要求崩溃的节点可以完好无损的恢复所有数据。这种空间下的备份算法是不常见的:依赖于“稳定存储”,即在任何失败恢复语义且没有违反潜在的一致性条件下都不会丢失。对于这种消耗来说有两个主要问题。第一,磁盘错误是持久化数据系统的实际操作中最常见的错误,一旦发生,数据基本都会丢失。第二,即使这不是问题,我们也不希望每次写入数据时都通过fsync方式(刷磁盘)保证数据持久化,因为这可能使性能降低两到三个数量级。我们的协议是:在备份节点重新加入ISR之前,必须保证,在加入之前,此备份节点必须再次完整的重新同步,即使它在崩溃中丢失了没有来得及刷磁盘的数据。
Unclean leader election: What if they all die?
However a practical system needs to do something reasonable when all the replicas die. If you are unlucky enough to have this occur, it is important to consider what will happen. There are two behaviors that could be implemented:
- Wait for a replica in the ISR to come back to life and choose this replica as the leader (hopefully it still has all its data).
- Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.
注意:Kafka的有关数据丢失的保证是至少存在一个保持同步的备份节点。如果所有备份节点都死掉了,则这种保证不再有效。
尽管实际系统需要在所有备份节点死掉时做一些合理的事情。如果不幸的发生了这种事情,重要的是考虑需要做些什么,有两种选择以供参考:
1.等待ISR中的某个备份重新活跃,然后选择这个备份节点称为新的leader(希望这个备份节点拥有完整的数据)
2.选择重新活跃的第一个备份节点(可能不在ISR中)作为leader。
This is a simple tradeoff between availability and consistency. If we wait for replicas in the ISR, then we will remain unavailable as long as those replicas are down. If such replicas were destroyed or their data was lost, then we are permanently down. If, on the other hand, a non-in-sync replica comes back to life and we allow it to become leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message. By default, Kafka chooses the second strategy and favor choosing a potentially inconsistent replica when all replicas in the ISR are dead. This behavior can be disabled using configuration property unclean.leader.election.enable, to support use cases where downtime is preferable to inconsistency.
这是可用性和一致性之间的折衷。如果我们等待ISR中的备份,则在备份节点不活跃其间需要一直等待。如果这些备份节点都损坏了或者数据丢失了,那么数据也就永久损坏了。如果,从另一方面来说,一个没有完整同步的备份重新活跃,同时我们选择它作为leader,那么它就会成为新的数据源,即使这个备份不能保证每条已经提交的消息。默认情况下,Kafka选择第二种策略,当ISR中所有备份节点都死掉的时候,支持选择潜在的非一致性备份。可以使用配置选项unclean.leader.election.enable禁用此行为,以避免宕机期间选择不一致的备份。
This dilemma is not specific to Kafka. It exists in any quorum-based scheme. For example in a majority voting scheme, if a majority of servers suffer a permanent failure, then you must either choose to lose 100% of your data or violate consistency by taking what remains on an existing server as your new source of truth.
这种困境不是kafka特有的。它存在于任何基于仲裁的机制中。例如,在一个大多数选举机制中,如果大多数servers遭受永久失败,那么你必须要么接受丢失所有数据,要么选择现有的数据作为新数据源,尽管后者破坏了一致性,那也比丢失所有数据都强。
Availability and Durability Guarantees
- Disable unclean leader election - if all replicas become unavailable, then the partition will remain unavailable until the most recent leader becomes available again. This effectively prefers unavailability over the risk of message loss. See the previous section on Unclean Leader Election for clarification.
- Specify a minimum ISR size - the partition will only accept writes if the size of the ISR is above a certain minimum, in order to prevent the loss of messages that were written to just a single replica, which subsequently becomes unavailable. This setting only takes effect if the producer uses acks=all and guarantees that the message will be acknowledged by at least this many in-sync replicas. This setting offers a trade-off between consistency and availability. A higher setting for minimum ISR size guarantees better consistency since the message is guaranteed to be written to more replicas which reduces the probability that it will be lost. However, it reduces availability since the partition will be unavailable for writes if the number of in-sync replicas drops below the minimum threshold.
当写入kafka时,producer可以选择是否等待消息确认(可以选择0,1,或者全部(-1)备份)。注意,所有备份的确认并不是保证备份集合中的所有分配的备份都需要收到这个消息。默认情况下,当acks=all时,确认只需要当前在in-sync备份列表中的备份节点收到消息即可。例如,如果一个topic只有两个备份节点,且有一个失效了(同步备份列表中只有一个了),那么指定acks=all依然会成功。然而,如果剩下的那个备份节点失效的话,这些后面的写入都会丢失。尽管这保证了partition的最大可用性,但是这种方式对于那些对持久性要求高过可用性的用户来说,可能并不可取。因此,我们提供了两个topic级别的配置选项,可以用来指定持久性优先级高于可用性。
1.禁用unclean leader election-如果所有备份节点不可用了,那么partition会一直保持不可用,直到最近选举的leader变的可用为止。这个特征可以优先选择丢失消息的风险的不可用性。查看前面有关unclean leader election的说明
2.指定最小的ISR个数-只有当ISR的个数大于某个确定的最小值时,partition才能接受写入,目的是为了避免消息写入单个备份节点而丢失,因为单个备份节点数据有可能变的不可用。这个设置只有当producer使用acks=all的配置时才有效,并且保证了消息可以被至少in-sync中备份节点确认收到。这个设置提供了一致性和可用性之间的折衷。最低ISR设置的越高,一致性保证就越强,因为消息可以被更过的备份节点写入,这样可以降低消息丢失的可能性。然而,如果in-sync中备份数降低到最低限度之下时,partition的写入就不可用了,这样也会降低可用性。
Replica Management
It is also important to optimize the leadership election process as that is the critical window of unavailability. A naive implementation of leader election would end up running an election per partition for all partitions a node hosted when that node failed. Instead, we elect one of the brokers as the "controller". This controller detects failures at the broker level and is responsible for changing the leader of all affected partitions in a failed broker. The result is that we are able to batch together many of the required leadership change notifications which makes the election process far cheaper and faster for a large number of partitions. If the controller fails, one of the surviving brokers will become the new controller.
上边有关备份日志的讨论只是覆盖了单独的日志,日历,一个topic-partition。然而,kafka集群可以管理成千上万个这样的partitions。我们在集群内部尝试采用轮询的方式对partitions进行负载均衡,以避免集群中包含大量数据的topics的所有的partitions只分布在少数节点上。同样,我们努力均衡leader的分布,这样一来,每个节点都是集群中某个partitions子集的leader。
对优化leadership选举过程非常重要的是不可用阶段的关键窗口。leader选举的一个简单实现是:为每个partition分配一个节点,当此节点不可用时,托管该节点上的所有partitions。我们选择某个broker作为“controller”。这个controller发现broker层面的失效,并负责更改所有以此失效broker为leader节点的partitions的leader。结果就是:我们能够批量处理很多有关leadership改变的需求,这可以更快的执行以及更少的消耗资源。如果此controller失效了,某个活着的broker会重新成为新的controller。
4.8 Log Compaction
So far we have described only the simpler approach to data retention where old log data is discarded after a fixed period of time or when the log reaches some predetermined size. This works well for temporal event data such as logging where each record stands alone. However an important class of data streams are the log of changes to keyed, mutable data (for example, the changes to a database table).
日志压缩保证了kafka可以在单个的topic partition日志数据中对每条消息来说都保存最少的字节数。它解决了这样的用例场景:在应用崩溃或者系统失效之后重新恢复状态,或者在操作维护期间应用重启之后的缓存重载等场景。让我们深入了解一下这些场景的更过细节并且描述如何进行压缩工作的。
到目前为止,我们只是描述了数据保存的简单方法:老的日志数据在某个固定的时间之后或者当日志达到某些预设的尺寸时,就会被删除。这对时间事件数据来说可以很好的工作,例如每条记录是单独的记录,即彼此之间没有任何关系。然而,一类非常重要的数据流是对带密钥的可变数据流(例如,某个数据库表格的改变,这样一来,某些消息都是针对某些key的操作)。
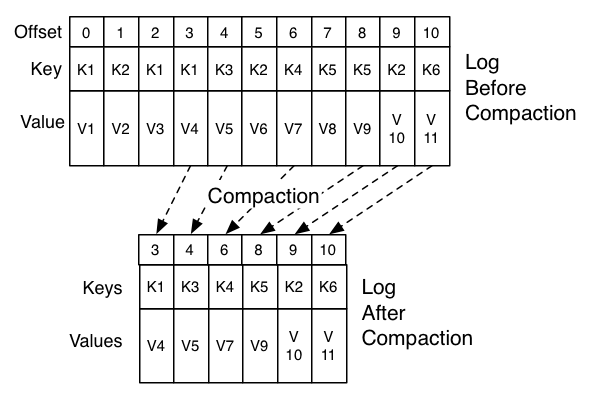
Let's discuss a concrete example of such a stream. Say we have a topic containing user email addresses; every time a user updates their email address we send a message to this topic using their user id as the primary key. Now say we send the following messages over some time period for a user with id 123, each message corresponding to a change in email address (messages for other ids are omitted):
让我们讨论一下这样的数据流的一个例子。如果说我们有一个这样的topic,里面包含用户的email地址:每次一个用户更新它们的email地址,我们就使用它们的user id作为key,发送一条消息到这个topic。现在如果说我们某段时间内发送了下面的一些消息,这些消息都是用户id 123,每条消息都是有关email地址的变化(忽略其他的用户id的消息):
123 => bill@microsoft.com
.
.
.
123 => bill@gatesfoundation.org
.
.
.
123 => bill@gmail.com
bill@gmail.com ). By doing this we guarantee that the log contains a full snapshot of the final value for every key not just keys that changed recently. This means downstream consumers can restore their own state off this topic without us having to retain a complete log of all changes.
日志压缩给予我们更细化的保留机制,我们就可以保证至少保存每个主key最后的更新(例如,bill@gmail.com)。通过这些,我们可以保证日志包含了每个key最后value的完整快照,而不是只有最近改变的key的消息。这就意味着,下游系统的consumers不需要上游系统保存所有的消息变化,就可以拥有完整的最终状态。
Let's start by looking at a few use cases where this is useful, then we'll see how it can be used.
- Database change subscription. It is often necessary to have a data set in multiple data systems, and often one of these systems is a database of some kind (either a RDBMS or perhaps a new-fangled key-value store). For example you might have a database, a cache, a search cluster, and a Hadoop cluster. Each change to the database will need to be reflected in the cache, the search cluster, and eventually in Hadoop. In the case that one is only handling the real-time updates you only need recent log. But if you want to be able to reload the cache or restore a failed search node you may need a complete data set.
- Event sourcing. This is a style of application design which co-locates query processing with application design and uses a log of changes as the primary store for the application.
- Journaling for high-availability. A process that does local computation can be made fault-tolerant by logging out changes that it makes to its local state so another process can reload these changes and carry on if it should fail. A concrete example of this is handling counts, aggregations, and other "group by"-like processing in a stream query system. Samza, a real-time stream-processing framework, uses this feature for exactly this purpose.
让我们开始看一下有用的场景,以及是如何使用的:
1.数据库改变的订阅。通常需要在多个数据系统来说拥有一个数据集合,这些系统中某个通常是某种数据库(或者是RDBMS或者可能新卷绕的key-value存储方式)。例如,你可能有一个数据库,一个缓存,一个搜索集群,以及一个Hadoop集群。对于数据库的每个变化都需要映射到缓存中、搜索集群,最终反应到Hadoop集群中。这种情况下,在一个处理实时更新的系统中,你只需要最近的日志。但是你可能想能够重新加载缓存或者重新恢复失效的搜索节点,这样你就需要一份完整的数据集合。
2.事件源头。这是一种应用设计方式,它将查询进程和应用设计共存,并使用日志变化作为应用的主要存储。
3.日志记录实现高可用性。进行本地计算的进程可以通过输出变化进行容错,这样就使得另一个进程在本地进程实效时可以重新加载本地状态以容错。具体例子是:在流查询系统中,处理计数,聚合,以及其他“逐组”处理。Samza,实时流式处理框架,使用这个特征正是为了这个目的。
In each of these cases one needs primarily to handle the real-time feed of changes, but occasionally, when a machine crashes or data needs to be re-loaded or re-processed, one needs to do a full load. Log compaction allows feeding both of these use cases off the same backing topic. This style of usage of a log is described in more detail in this blog post.
The general idea is quite simple. If we had infinite log retention, and we logged each change in the above cases, then we would have captured the state of the system at each time from when it first began. Using this complete log, we could restore to any point in time by replaying the first N records in the log. This hypothetical complete log is not very practical for systems that update a single record many times as the log will grow without bound even for a stable dataset. The simple log retention mechanism which throws away old updates will bound space but the log is no longer a way to restore the current state—now restoring from the beginning of the log no longer recreates the current state as old updates may not be captured at all.
在这些情况中每一种情况下,都需要处理实时变化的信息流,但是偶尔会出现,当机器崩溃或者数据需要重载或者重新处理时,就需要完整的加载。日志压缩允许相同的topic满足这两个应用场景。日志的这种使用方式在这片文章中有更多细节描述。
一般的想法很简单。如果可以无限存储日志,我们可以记录上述的每种变化,则从系统第一次启动之时起的所有状态都可以记录下来。使用这种完整的日志,我们可以恢复到任意时刻。这种假设的完整日志对于系统来说不是特别实际,即使对于稳定的数据集来说,频繁的更新会使日志超出限制。这种简单的日志保存机制--删除老的更新将释放空间,但是日志不再是恢复到当前状态的方式-从日志开始恢复日志状态不再能恢复到当前状态,因为老的更新已经丢弃了。
Log compaction is a mechanism to give finer-grained per-record retention, rather than the coarser-grained time-based retention. The idea is to selectively remove records where we have a more recent update with the same primary key. This way the log is guaranteed to have at least the last state for each key.
This retention policy can be set per-topic, so a single cluster can have some topics where retention is enforced by size or time and other topics where retention is enforced by compaction.
This functionality is inspired by one of LinkedIn's oldest and most successful pieces of infrastructure—a database changelog caching service called Databus. Unlike most log-structured storage systems Kafka is built for subscription and organizes data for fast linear reads and writes. Unlike Databus, Kafka acts as a source-of-truth store so it is useful even in situations where the upstream data source would not otherwise be replayable.
日志压缩是一种可以提供以每条记录为粒度的保存机制,而不是较粗的以时间为粒度的保存机制。这种想法是有选择的删除具有相同主键的更新记录。日志的这种方式保证了保存每个key的至少一条最后更新的状态。
保存策略可以每个topic都设置自己的,因此集群可以有很多topics,这样不同的topics的保存策略可能时基于尺寸或者基于时间,或者是基于压缩的。
这种功能的灵感来自于LinkedIn的最古老以及最有效的基础设施之一--一个称为Databus的数据库更新日志缓存服务。不像大多数日志存储结构系统,kafka的构建是为了订阅,数据的组织是为了快速的线性读写。不像Databus,Kafka充当真实的数据来源,即使在上游数据源不能重放数据时也是如此。
Log Compaction Basics
下图展示了kafka日志中带有offset的每个消息的逻辑结构

The head of the log is identical to a traditional Kafka log. It has dense, sequential offsets and retains all messages. Log compaction adds an option for handling the tail of the log. The picture above shows a log with a compacted tail. Note that the messages in the tail of the log retain the original offset assigned when they were first written—that never changes. Note also that all offsets remain valid positions in the log, even if the message with that offset has been compacted away; in this case this position is indistinguishable from the next highest offset that does appear in the log. For example, in the picture above the offsets 36, 37, and 38 are all equivalent positions and a read beginning at any of these offsets would return a message set beginning with 38.
日志的头和传统kafka日志相同。它具有密集的顺序的offsets,以此保存所有消息。日志压缩增加了用于处理日志尾部的选项。上图展示了带有压缩尾部的日志。注意:日志尾部的消息保留了首次写入时的原始offset--这个从来不会改。也需要注意:即使某些offset的消息已经压缩了,所有offsets依然保留在日志中正确位置。这种情况下,此位置和日志中出现的下一个最高的offset无法区分。例如,上面图片中德offsets 36,37,38都是等效位置,并且在这三个offsets中任何一个开始读取日志,都会返回从38开始的消息集。
Compaction also allows for deletes. A message with a key and a null payload will be treated as a delete from the log. This delete marker will cause any prior message with that key to be removed (as would any new message with that key), but delete markers are special in that they will themselves be cleaned out of the log after a period of time to free up space. The point in time at which deletes are no longer retained is marked as the "delete retention point" in the above diagram.
The compaction is done in the background by periodically recopying log segments. Cleaning does not block reads and can be throttled to use no more than a configurable amount of I/O throughput to avoid impacting producers and consumers. The actual process of compacting a log segment looks something like this:
压缩也允许删除。带有key和空内容的消息都将被视为日志中已经删除的消息。这个删除标记将导致删除前面的任何具有该key的消息,但是删除标记是特别的,因为他们自己将在一段时间内之后删除自己以释放空间。不再保留删除标记的时间点在上图中标记为“删除点”。
压缩在后台通过定期复制日志端来完成。清除并没有阻塞读操作,并且可以限制为使用不超过配置的I/O吞吐量,以避免影响生产者和消费者。压缩日志段的实际过程就像以下:
What guarantees does log compaction provide?
- Any consumer that stays caught-up to within the head of the log will see every message that is written; these messages will have sequential offsets. The topic's
min.compaction.lag.mscan be used to guarantee the minimum length of time must pass after a message is written before it could be compacted. I.e. it provides a lower bound on how long each message will remain in the (uncompacted) head. - Ordering of messages is always maintained. Compaction will never re-order messages, just remove some.
- The offset for a message never changes. It is the permanent identifier for a position in the log.
- Any read progressing from offset 0 will see at least the final state of all records in the order they were written. All delete markers for deleted records will be seen provided the reader reaches the head of the log in a time period less than the topic's delete.retention.ms setting (the default is 24 hours). This is important as delete marker removal happens concurrently with read (and thus it is important that we not remove any delete marker prior to the reader seeing it).
- Any consumer progressing from the start of the log will see at least the final state of all records in the order they were written. All delete markers for deleted records will be seen provided the consumer reaches the head of the log in a time period less than the topic's
delete.retention.mssetting (the default is 24 hours). This is important as delete marker removal happens concurrently with read, and thus it is important that we do not remove any delete marker prior to the consumer seeing it.
日志压缩提供了以下保证:
1.任何consumer,如果能够跟得上日志写入的速度,那么可以看到所有写入的消息;这些消息都有顺序的offsets。topic的min.compaction.lag.ms可以用来保证消息写入之后压缩之前可以停留的时间。例如,它提供了比较小的时间区间:每条消息可以在日志头部(未压缩)保留的时间。
2.消息的顺序总是不会变。压缩不会重排消息,只是会删除某些消息。
3.消息的offset从来不变。日志中的位置标记是永远不变的。
4.从offset 0的任何阅读处理都将至少看到所有写入记录的最后状态。如果consumer可以在topic的delete.retention.ms设置(默认是24小时)之内到达日志头部,则可以看到所有已删除日志的删除标记。这很重要,因为删除标记的移除和读取同时发生(这样,很重要的还有:我们在consumer没有读到消息之前没有移除任何删除标记)。
5.任何consumer从日志开始的处理都将至少所有记录的最后状态:按照他们写入的顺序。如果consumer可以在topic的delete.retention.ms设置(默认是24小时)之内到达日志头部,则可以看到所有已删除日志的删除标记。这很重要,因为删除标记的移除和读取同时发生(这样,很重要的还有:我们在consumer没有读到消息之前没有移除任何删除标记)。
Log Compaction Details
- It chooses the log that has the highest ratio of log head to log tail
- It creates a succinct summary of the last offset for each key in the head of the log
- It recopies the log from beginning to end removing keys which have a later occurrence in the log. New, clean segments are swapped into the log immediately so the additional disk space required is just one additional log segment (not a fully copy of the log).
- The summary of the log head is essentially just a space-compact hash table. It uses exactly 24 bytes per entry. As a result with 8GB of cleaner buffer one cleaner iteration can clean around 366GB of log head (assuming 1k messages).
日志压缩由日志清理器完成,是由一系列后台线程组成:重拷贝日志段文件,删除前面已经出现的key的日志。每个压缩线程像下面一样工作:
1.它选择日志头到日志尾比率最高的日志
2.它为日志中每个key创建最后状态的简明摘要
3.它重新拷贝日志:从头到尾删除相同key的老旧消息。那么,新的干净的日志段会立刻替代原有日志,因此只需要增加新日志段的磁盘空间,而不是完整日志的拷贝
4.日志头的本质只是一个空间紧凑的hash表。它每个条目使用24个字节。因此,使用8GB的清理器缓存,一个清理器可以请求366GB的日志头(假设每条消息1k)
Configuring The Log Cleaner
默认是开启日志清理器。这将启动清理器线程池。为了能够清理某个特定的topic,你需要添加特定的日志压缩特征:
log.cleanup.policy=compactThis can be done either at topic creation time or using the alter topic command.
The log cleaner can be configured to retain a minimum amount of the uncompacted "head" of the log. This is enabled by setting the compaction time lag.
也可以通过命令行在创建topic时设置或者使用alter命令改变。
日志清理器可以配置为:保存少量的未压缩的日志头。这可以通过设置压缩落后时间来设定。
log.cleaner.min.compaction.lag.msThis can be used to prevent messages newer than a minimum message age from being subject to compaction. If not set, all log segments are eligible for compaction except for the last segment, i.e. the one currently being written to. The active segment will not be compacted even if all of its messages are older than the minimum compaction time lag.
Further cleaner configurations are described here.
这可以用来避免消息在最小的消息保留时间内就被压缩。如果不设置,除了最后的日志段之外(即当前正在写入的日志段),所有日志段都会压缩。活跃日志段将不会被压缩,即使所有消息都超出了最小压缩落后时间。
更清楚的配置请看这里。
4.9 Quotas
Starting in 0.9, the Kafka cluster has the ability to enforce quotas on produce and fetch requests. Quotas are basically byte-rate thresholds defined per group of clients sharing a quota.
从0.9开始,kafka集群可以对produce和fetch请求指定指标。指标基本上是每组共享指标的客户端定义的字节率限制。
Why are quotas necessary?
It is possible for producers and consumers to produce/consume very high volumes of data and thus monopolize broker resources, cause network saturation and generally DOS other clients and the brokers themselves. Having quotas protects against these issues and is all the more important in large multi-tenant clusters where a small set of badly behaved clients can degrade user experience for the well behaved ones. In fact, when running Kafka as a service this even makes it possible to enforce API limits according to an agreed upon contract.
生产者和消费者有可能生产或者消费大量的数据,这样有可能独占broker资源,引起网络饱和以及一般的拒绝服务其他客户端或者brokers自己。拥有指标就可以避免这些问题,对于大型多租户集群来说更加重要,因为某组表现不好的客户端可能引发其他表现良好的客户端体验。实际上,当把kafka作为一个服务来看时,这甚至可以根据约定来实现API限制。
Client groups
PrincipalBuilder . Client-id is a logical grouping of clients with a meaningful name chosen by the client application. The tuple (user, client-id) defines a secure logical group of clients that share both user principal and client-id.
Quotas can be applied to (user, client-id), user or client-id groups. For a given connection, the most specific quota matching the connection is applied. All connections of a quota group share the quota configured for the group. For example, if (user="test-user", client-id="test-client") has a produce quota of 10MB/sec, this is shared across all producer instances of user "test-user" with the client-id "test-client".
kafka客户端的身份是安全集群中已认证用户的用户主体。在支持非认证客户端的的集群中,用户主体是由broker使用可配置PrincipalBuilder选择的非认证用户组。Client-id是客户端应用选择的用于对clients进行逻辑分组的有意义的名字。组(user,client-id)定义了一个安全的逻辑的用户组,由用户主体和client-id共用。限额可以用于用户或者client-id组。对于给定链接来说,将匹配最特定的限额。一个限额组的所有链接都共享此组配置好的限额。例如,如果(user="test-user", client-id="test-client")的限额是10mb/s,那么所有user"test-user"以及client-id"test-client"的所有实例都共享这个限额。
Quota Configuration
Quota configuration may be defined for (user, client-id), user and client-id groups. It is possible to override the default quota at any of the quota levels that needs a higher (or even lower) quota. The mechanism is similar to the per-topic log config overrides. User and (user, client-id) quota overrides are written to ZooKeeper under /config/users and client-id quota overrides are written under /config/clients. These overrides are read by all brokers and are effective immediately. This lets us change quotas without having to do a rolling restart of the entire cluster. See here for details. Default quotas for each group may also be updated dynamically using the same mechanism.
可以为(user,client-id),user和client-id组配置限额。如果需要更高或者更低的限额,则可以重置默认限额。这个机制类似于对每个topic都可以重置日志的配置选项。用户和(user,client-id)限额写入zookeeper中/config/users目录下,重置client-id限额可以通过/configs/clients目录设置。这些重置可以被所有brokers读到,并可以立即生效。这将使得我们不需要重启整个集群就可以改变限额。查看这里获得更多细节。每个组的默认配额也可以使用同样的机制进行动态更新。
The order of precedence for quota configuration is:
- /config/users/<user>/clients/<client-id>
- /config/users/<user>/clients/<default>
- /config/users/<user>
- /config/users/<default>/clients/<client-id>
- /config/users/<default>/clients/<default>
- /config/users/<default>
- /config/clients/<client-id>
- /config/clients/<default>
Enforcement
强制执行
By default, each unique client group receives a fixed quota in bytes/sec as configured by the cluster. This quota is defined on a per-broker basis. Each client can publish/fetch a maximum of X bytes/sec per broker before it gets throttled. We decided that defining these quotas per broker is much better than having a fixed cluster wide bandwidth per client because that would require a mechanism to share client quota usage among all the brokers. This can be harder to get right than the quota implementation itself!
How does a broker react when it detects a quota violation? In our solution, the broker does not return an error rather it attempts to slow down a client exceeding its quota. It computes the amount of delay needed to bring a guilty client under its quota and delays the response for that time. This approach keeps the quota violation transparent to clients (outside of client-side metrics). This also keeps them from having to implement any special backoff and retry behavior which can get tricky. In fact, bad client behavior (retry without backoff) can exacerbate the very problem quotas are trying to solve.
Client byte rate is measured over multiple small windows (e.g. 30 windows of 1 second each) in order to detect and correct quota violations quickly. Typically, having large measurement windows (for e.g. 10 windows of 30 seconds each) leads to large bursts of traffic followed by long delays which is not great in terms of user experience.
默认情况下,每个独一无二的客户端组都可以收到一个由集群配置的固定配额(单位为bytes/sec)。这个配额是基于每个broker自己设置的。在broker配置改变之前,每个客户端可以从某个broker都发布或者拉取某个最大值的bytes/sec。我们决定:为每个broker定义它自己的限额,要比每个客户端都有固定的集群带宽要好的多,因为后者需要所有brokers共享客户端限额的机制。这可能比限额实现本身更难。
当检测到配额违规时,broker会怎么应对。在我们的解决方案中,broker不会返回错误,而是试图减缓客户端超出限额的行为。它将计算将有罪客户端置于限额之下所需要的延迟时间,并延迟回应客户端的时间。此方法使限额对客户端保持透明(在客户端指标之外)。这也使他们不需要任何特殊的停留和重试行为,这些行为可能会使事情变得更糟糕。事实上,不好的客户端行为(没有停留的重试)可能会加剧限额正在试图解决的问题。
客户端字节率在多个小窗口上测量(每秒内30个窗口),以快速测量和校正限额。一般来说,大量的测试窗口(每30秒10个窗口)将导致大量的突发业务量,紧接着是长时间的延迟,这在用户体验方面上倒不是很大。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)