Spark Streaming 的原理以及应用场景介绍
什么是Spark StreamingSpark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强这两个特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用 Spark的高度抽象原语如:map、re
- 什么是Spark Streaming
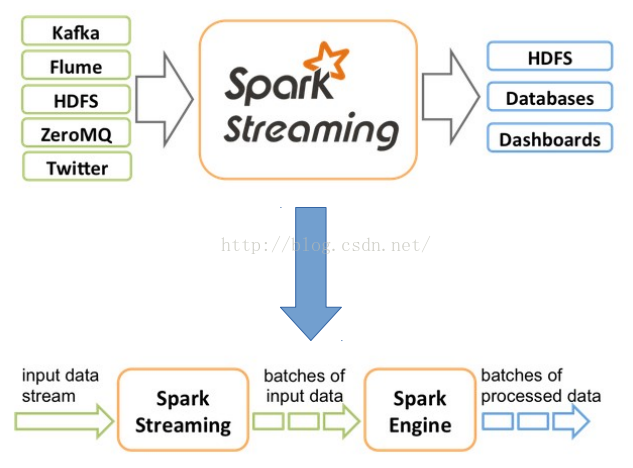
Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强这两个特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用 Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外 Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。大概架构如下:
- Spark Streaming 运行原理
Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据,基本原理图如下:
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
- SparkStreaming 支持的业务场景
目前而言SparkStreaming 主要支持以下三种业务场景- 无状态操作:只关注当前的DStream中的实时数据,例如 只对当前DStream中的数据做正确性校验
- 有状态操作:对有状态的DStream进行操作时,需要依赖之前的数据 例如 统计网站各个模块总的访问量
- 窗口操作:对指定时间段范围内的DStream数据进行操作,例如 需要统计一天之内网站各个模块的访问数量
- SparkStreaming 支持的操作
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream由连续的序列化RDD来表示。支持的操作主要包含以下几种
- Action
- 当某个Output Operations原语被调用时,stream才会开始真正的计算过程。现阶段支持的Output方式有以下几种:
- print()
- foreachRDD(func)
- saveAsObjectFiles(prefix, [suffix])
- saveAsTextFiles(prefix, [suffix])
- saveAsHadoopFiles(prefix, [suffix])
- 当某个Output Operations原语被调用时,stream才会开始真正的计算过程。现阶段支持的Output方式有以下几种:
- 常规RDD 的Transformation操作
对常规RDD使用的transformation操作,在DStream上都适用 - 有状态的Transformation
- UpdateStateByKey:使用该方法主要是使用目前的DStream数据来更新历史数据
- 窗口的 Transformation
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。如下图所示:
主要支持的操作有:
- window(windowLength, slideInterval)
- countByWindow(windowLength, slideInterval)
- reduceByWindow(func, windowLength, slideInterval)
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
- countByValueAndWindow(windowLength, slideInterval, [numTasks])
- Action
- 持久化以及容错
- 持久化
与RDD一样,DStream同样也能通过persist()方法将数据流存放在内存中,这样做的好处是遇到需要多次迭代计算的程序时,速度优势十分的明显。
而对于上文中提到的Window以及Stateful的操作,其默认的持久化策略就是保存在内存中(MEMORY_ONLY_SER)。
当数据源来自于网络时(例如通过Kafka、Flume、sockets等等),由于网络数据的不可在再现性,默认的持久化策略是MEMORY_AND_DISK_SER_2(将数据保存在两台机器上),这也是为了容错性而设计的。
关于持久化,还有一点需要注意的就是,由于数据流的持续处理,在内存的消耗上可能比较大,为了缓解内存的压力引入了checkpoint的概念,checkpoint有以下几点需要注意:
– 对于 window 和 stateful 操作必须 checkpoint
– 通过 StreamingContext 的 checkpoint 来指定目录
– 通过 DStream 的 checkpoint 指定间隔时间
– 间隔必须是 slide interval 的倍数
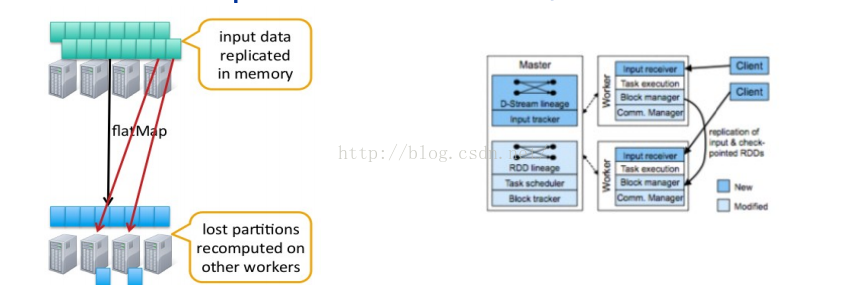
- 容错
DStream 基于 RDD 组成, RDD 的容错性依旧有效- RDD 的某些 partition 丢失了 , 可以通过 lineage 信息重新计算恢复
- 数据源来自外部文件系统 , 如 HDFS
- 一定可以通过重新读取数据来恢复 , 绝对不会有数据丢失
- 数据源来自网络
- 默认会在两个不同节点加载数据到内存 , 一个节点 fail 了 , 系统可以通过另一个节点的数 据重算
- 假设正在运行 InputReceiver 的节点 fail 了 , 可能会丢失一部分数据
- 持久化
- 优化
- 监控手段
一般来说,使用Spark自带的Web UI就能满足大部分的监控需求。对于Spark Streaming来说,以下几个度量指标尤为重要(在Batch Processing Statistics标签下):- Processing Time:处理每个batch的时间
- Scheduling Delay:每个batch在队列中等待前一个batch完成处理所等待的时间
- 若Processing Time的值一直大于Scheduling Delay,或者Scheduling Delay的值持续增长,代表系统已经无法处理这样大的数据输入量了,这时就需要考虑各种优化方法来增强系统的负载。
- 优化方式
- 利用集群资源,减少处理每个批次的数据的时间
- 控制 reduce 数量,太多的 reducer, 造成很多的小任务 , 以此产生很多启动任务的开销。太 少的 reducer, 任务执行行慢 !
- spark.streaming.blockInterval
- inputStream.repartition
- spark.default.parallelism
- 序列化
- 输入数据序列化
- RDD 序列化
- TASK 序列化
- 控制 reduce 数量,太多的 reducer, 造成很多的小任务 , 以此产生很多启动任务的开销。太 少的 reducer, 任务执行行慢 !
- 在 Standalone 及 coarse-grained 模式下的任务启动要比 fine-grained 省时
- 给每个批次的数据量的设定一个合适的大小,原则 : 要来得及消化流进系统的数据
- 内存调优
- 清理缓存的 RDD
- 在 spark.cleaner.ttl 之前缓存的 RDD 都会被清除掉
- 设置 spark.streaming.unpersis, 系统为你分忧
- 使用并发垃圾收集器
- 清理缓存的 RDD
- 利用集群资源,减少处理每个批次的数据的时间
- 监控手段



Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)