Spark Streaming + Kafka 另一利器 Kafka-spark-consumer 项目
在之前的文章中,曾经提到了,如何在使用 Kafka Direct API 处理消费时,将每个Partition的offset写到Zookeeper中,并且在应用重新启动或者应用升级时,可以通过读取Zookeeper中的offset恢复之前的处理位置,进而继续工作。而本篇文章则将要介绍另外一个 Spark Streaming + Kafka 的利器 – Kafka-spark-consumer 项目
在之前的文章中,曾经提到了,如何在使用 Kafka Direct API 处理消费时,将每个Partition的offset写到Zookeeper中,并且在应用重新启动或者应用升级时,可以通过读取Zookeeper中的offset恢复之前的处理位置,进而继续工作。而本篇文章则将要介绍另外一个 Spark Streaming + Kafka 的利器 – Kafka-spark-consumer 项目。
一、项目简介
项目名称:Kafka-spark-consumer
项目地址:https://github.com/dibbhatt/kafka-spark-consumer
在项目的 README.md 中,已经对这个项目有了一个详细的介绍,此处就不对里面的内容进行详细的说明了,想了解的同学可自行去了解,总结一句话:牛。
我在这边需要强调的是:Kafka-spark-consumer 项目在运行的过程中会把 topic 的每个 partition 的 offsets 写到 Zookeeper 中,当我们对 Driver 程序进行升级 或者 需要重新启动 Driver 程序的时候,Kafka-spark-consumer 可以从Zookeeper中恢复相关内容并继续执行。
二、构建测试程序
程序的主要功能:从kafka中 kafka_direct topic 中处理消息,统计每个batch中单词出现的次数。
2.1、添加依赖jar包,此处使用的maven方式。
<dependencies>
<dependency>
<groupId>dibbhatt</groupId>
<artifactId>kafka-spark-consumer</artifactId>
<version>1.0.6</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>SparkPackagesRepo</id>
<url>http://dl.bintray.com/spark-packages/maven</url>
</repository>
</repositories>由于需要下载相关依赖的jar包,所以我在下载的时候花了很长时间。
2.2、具体测试代码,如下:
public class KafkaSparkConsumerTest{
public static JavaStreamingContext createContext(){
Properties props = new Properties();
//Kafka所使用的Zookeeper的IP地址
props.put("zookeeper.hosts", "192.168.1.151");
//Kafka所使用的Zookeeper的端口
props.put("zookeeper.port", "2181");
//Kafka在Zookeeper中,保存broker 服务器的路径
props.put("zookeeper.broker.path", "/brokers");
//配置目标 topic
props.put("kafka.topic", "kafka_direct");
//配置用来标识此程序作为consumer的编号
props.put("kafka.consumer.id", "54321");
//配置用来存储offset的Zookeeper
props.put("zookeeper.consumer.connection", "192.168.1.151:2181");
//配置存储offset的基础path
props.put("zookeeper.consumer.path", "/kafka_spark_consumer");
//********以下是可选参数 ******************/
//配置是否强制从第一条消息开始处理,默认是从当时能获取到的最后一条记录开始处理
props.put("consumer.forcefromstart", "true");
props.put("consumer.fetchsizebytes", "1048576");
props.put("consumer.fillfreqms", "250");
props.put("consumer.backpressure.enabled", "true");
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("KafkaSparkConsumerTest")
.set("spark.streaming.receiver.writeAheadLog.enable", "false");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(30));
jsc.checkpoint("/checkpoint");
/*
* 由于ReceiverLauncher.launch的返回值为JavaDStream<MessageAndMetadata>类型的,
* 而我们现在所关心的是消息中的数据,所以直接调用了 MessageAndMetadata中的
* getPayload()方法并构造为 String类型的
* 而MessageAndMetadata中包含了很多有用的内容,例如:consumer,topic,partition
* ,offset,key,payload,而具体的含义从名称上就可以看出来了。
*/
JavaDStream<String> lines = ReceiverLauncher.launch(jsc, props,3, StorageLevel.MEMORY_ONLY()).map(new Function<consumer.kafka.MessageAndMetadata, String>() {
@Override
public String call(consumer.kafka.MessageAndMetadata v1) throws Exception {
return new String( v1.getPayload());
}
});
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(
String event)
throws Exception {
return Arrays.asList(event);
}
});
JavaPairDStream<String, Integer> pairs = words
.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(
String word) throws Exception {
return new Tuple2<String, Integer>(
word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs
.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2)
throws Exception {
return v1 + v2;
}
});
wordsCount.print();
return jsc;
}
public static void main(String[] args) throws Exception{
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
public JavaStreamingContext create() {
return createContext();
}
};
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate("/checkpoint", factory);
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
2.3、准备测试环境。
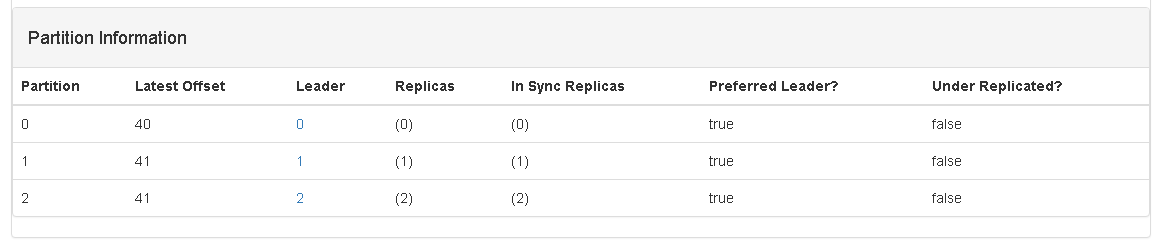
当前 kafka_direct topic 中的各个partition的offset信息:
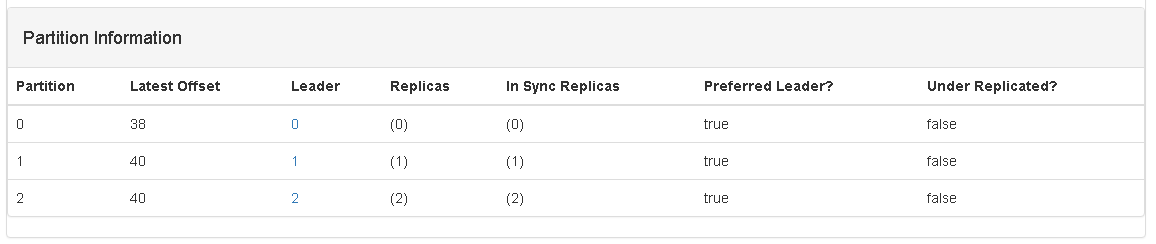
当前ZooKeeper中的path信息: 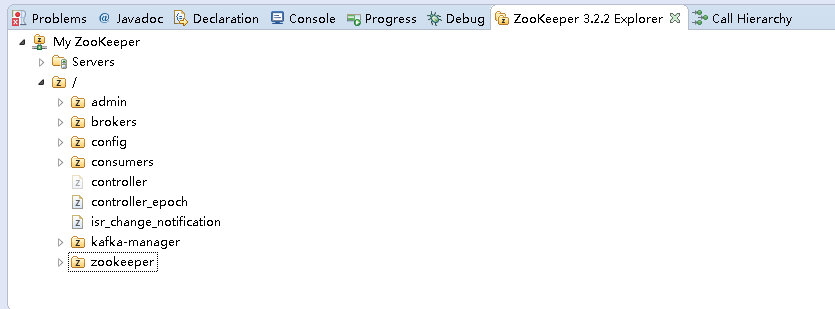
从截图中可以看到 程序中使用到的 /kafka_spark_consumer 路径目前还不存在。
2.4、运行Spark Streaming 程序,观察命令打印及Zookeeper中的变化:
Spark Streaming 程序的输出: 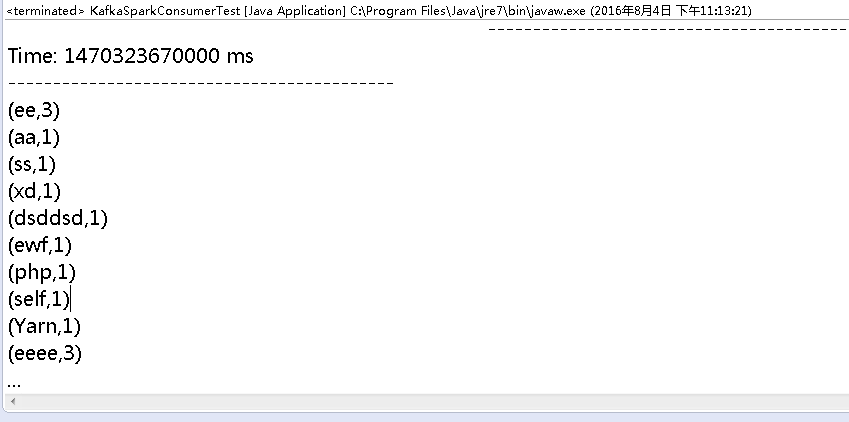
从输出中可以看到,它将我之前的测试数据一并打印了,非常符合程序中的设定 consumer.forcefromstart=true 的参数。
Zookeeper中的变化: 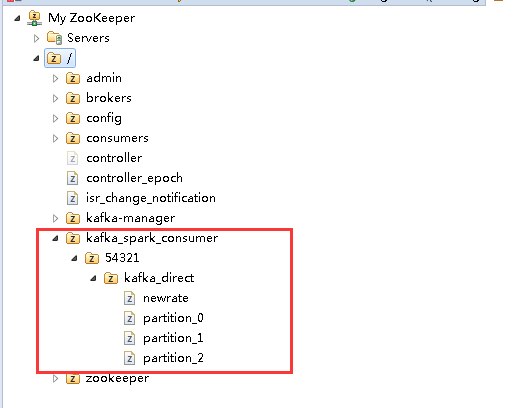
从截图中可以看到,已经将 kafka_direct 中的每个 partition 的offset 保存到了Zookeeper中了,其中最末节点的内容如下: 
这个截图中的offset的值是40,正好与准备数据中的Kafka Manager中关于每个partition的offset的值是一样的。
2.5、删除checkpoint中的数据,并向kafka_direct中增加了四条消息,如下图:
2.6、再次运程Spark Streaming ,看其是否输出了4个单词的统计结果,如下图: 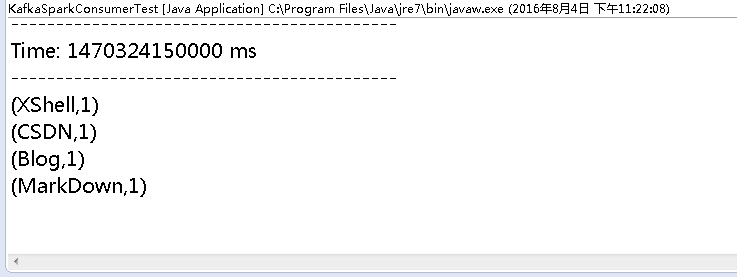
完全没有问题!!!

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)