云原生中间件RocketMQ-核心原理之消息存储结构解析
从主流的几种MQ消息队列采用的存储方式来看,主要会有三种分布式KV存储:这种存储方式对于消息读写能力要求不高的情况可以使用,比如ActiveMQ中采用的levelDB。文件系统存储:这种方案适合对于有高吞吐量要求的消息中间件,因为消息刷盘是一种高效率,高可靠、高性能的持久化方式,除非磁盘出现故障,否则一般是不会出现无法持久化的问题。常见的比如kafka、RocketMQ、RabbitMQ都是采用消
从主流的几种MQ消息队列采用的存储方式来看,主要会有三种
分布式KV存储:这种存储方式对于消息读写能力要求不高的情况可以使用,比如ActiveMQ中采用的levelDB。
文件系统存储:这种方案适合对于有高吞吐量要求的消息中间件,因为消息刷盘是一种高效率,高可靠、高性能的持久化方式,除非磁盘出现故障,否则一般是不会出现无法持久化的问题。常见的比如kafka、RocketMQ、RabbitMQ都是采用消息刷盘到所部署的机器上的文件系统来做持久化。
关系型数据库:关系型数据库在单表数据量达到千万级的情况下IO性能会出现瓶颈,比如ActiveMQ可以采用mysql作为消息存储,所以ActiveMQ并不适合于高吞吐量的消息队列场景。
总的来说,对于存储效率,文件系统要优于分布式KV存储,分布式KV存储要优于关系型数据库。

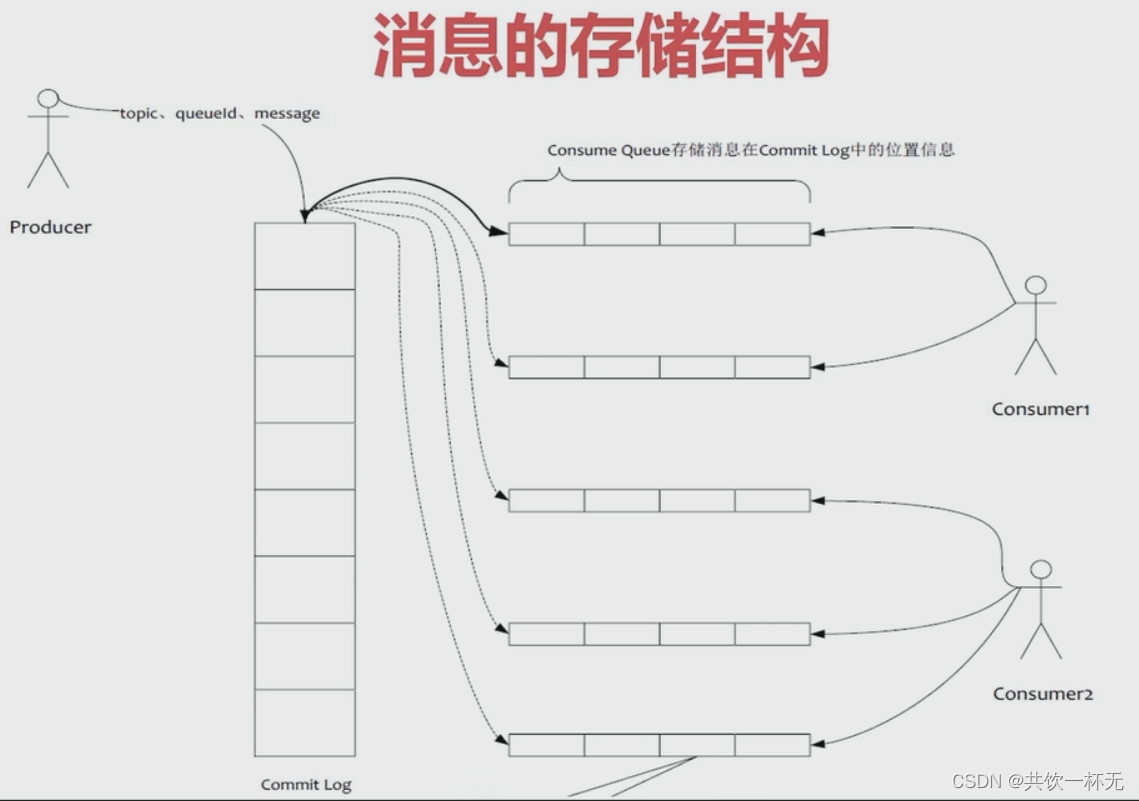
RocketMQ就是采用文件系统的方式来存储消息,消息的存储是由ConsumeQueue和CommitLog配合完成的。
CommitLog是消息真正的物理存储文件。
ConsumeQueue是消息的逻辑队列,有点类似于数据库的索引文件,里面存储的是指向CommitLog文件中消息存储的地址。
RocketMQ的存储文件默认在root/store目录下,可以看到这样一个结构的文件。

CommitLog
CommitLog是用来存放消息的物理文件,每个broker上的commitLog与当前机器上的所有 consumerQueue共享,不做任何的区分。即所有topic的数据都存在一起。
关于文件大小:
- CommitLog中的文件默认大小为1G,可以动态配置;
- 当一个文件写满以后,会生成一个新的commitlog文件。所有的Topic数据是顺序写入在CommitLog文件中的。
关于文件名:
- 文件名的长度为20位,左边补0,剩余未起始偏移量
- 比如 00000000000000000000 表示第一个文件,当第一个文件写满后,生成第二个文件 000000000001073741824 ,起始偏移量为1073741824
ConsumeQueue
consumeQueue表示消息消费的逻辑队列,这里面包含MessageQueue在commitlog中的其实物理位置偏移量offset,消息实体内容的大小和Message Tag的hash值。
关于文件大小:
- 对于实际物理存储来说, consumeQueue对应每个topic和queueid下的文件,每个consumeQueue类型的文件也是有大小,每个文件默认大小约为600W个字节,如果文件满了后会也会生成一个新的文件。
关于文件名:
- 每个Topic下的每个Message Queue都会对应一个ConsumeQueue文件,比如上图中的testCreateTopic3主题下有2个文件夹,分别代表消息队列0和1。
每个消息队列的文件地址是:root/store/consumequeue/{topicNmae}/{queueId}/{filename}
IndexFile
索引文件,如果一个消息包含Key值的话,会使用IndexFile存储消息索引。Index索引文件提供了对 CommitLog进行数据检索,提供了一种通过key或者时间区间来查找CommitLog中的消息的方法。
在物理存储中,文件名是以创建的时间戳明明,固定的单个IndexFile大小大概为400M,一个IndexFile可以保存2000W个索引
abort
broker在启动的时候会创建一个空的名为abort的文件,并在shutdown时将其删除,用于标识进程是否正常退出,如果不正常退出,会在启动时做故障恢复。
本文内容到此结束了,
如有收获欢迎点赞👍收藏💖关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问💬欢迎各位大佬指出。
主页:共饮一杯无的博客汇总👨💻保持热爱,奔赴下一场山海。🏃🏃🏃


Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)