Kafka消息消费原理
目录TopicPartitionTopic与Partition的存储消息默认分发策略消息的分区分配分区分配策略Coordinator(协调者)JoinGroup与Synchronizing Group Stateoffset分区的副本机制Topic在kafka中,topic是一个存储消息的逻辑概念,可以认为是一个消息集合。每条消息发送到kafka集群...
目录
JoinGroup与Synchronizing Group State
Topic
在kafka中,topic是一个存储消息的逻辑概念,可以认为是一个消息集合。每条消息发送到kafka集群的消息都有一个类别。物理上来说,不同的topic的消息是分开存储的,每个topic可以有多个生产者向它发送消息,也可以有多个消费者去消费其中的消息。
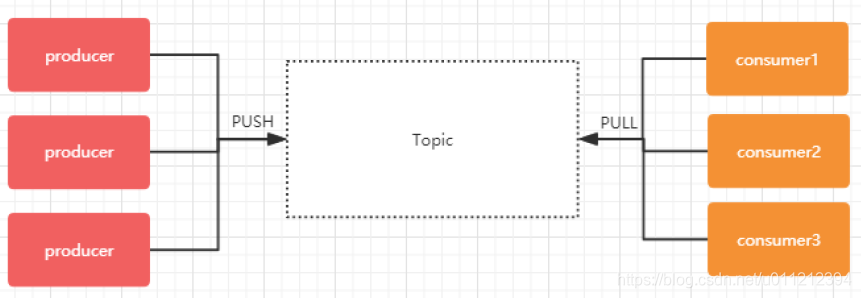
Partition
每个topic可以划分多个分区(每个Topic至少有一个分区),同一topic下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka通过offset保证消息在分区内的顺序,offset的顺序不跨分区,即kafka只保证在同一个分区内的消息是有序的。
下图中,对于名字为test的topic,做了3个分区,分别是p0、p1、p2:
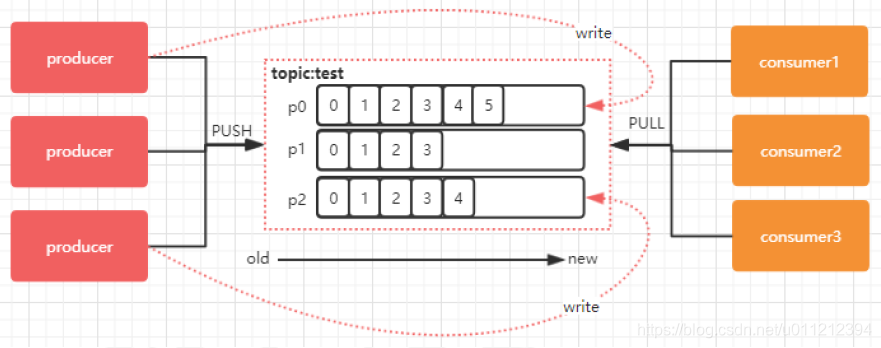
每一条消息发送到broker时,会根据partition的规则选择存储到哪一个partition。如果partition规则设置合理,那么所有的消息会均匀的分布在不同的partition中,这样就有点类似数据库的分库分表的概念,把数据做了分片处理。
Topic与Partition的存储
Partition是以文件的形式存储在文件系统中,比如创建一个名为test的topic,其中有3个partition,那么在kafka的数据目录(/tmp/kafka-log)中就有3个目录,test-0~3, 命名规则是<topic_name>-<partition_id>
消息默认分发策略
默认情况下,kafka采用的是hash取模的分区算法。如果Key为null,则会随机分配一个分区。
自定义选择分区
如果想自定义选择分区,可以实现Partitioner接口的partition方法,自定义计算分区策略。如果想实现顺序消费,可将消息指定到同一分区。
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] bytes, Object value, byte[] bytes1, Cluster cluster) {
List<PartitionInfo> list = cluster.partitionsForTopic(topic);
int partitionNum = list.size();
// 如果未指定key,则统一返回到指定分区
if (key == null) {
return 0;
} else {
// 否则根据key的hashcode取模计算分区
return Math.abs(key.hashCode()) % partitionNum;
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}在发送端添加自定义分区实现配置:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.hujy.kafkademo.MyPartitioner");消息的分区分配
在生产环境中,每个topic都会有多个partitions。多个partitions能够对 broker上的数据进行分片,有效减少了消息的容量从而提升io性能。kafka存在consumer group的概念,一个组内的所有消费者协调在一起来消费订阅topic的所有partitions,此时就需要了解消息的分区分配策略。
consumer和partition的数量建议:
如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的, 所以consumer数不要大于partition数。
如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀,最好partiton数目是 consumer数目的整数倍。
另外,consumer从多个partition读到数据,无法保证数据间的顺序性,kafka只保证在一个partition上数据是有序的。增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition也会发生变化。
例如:
3个partiton对应3个consumer:
consumer1会消费partition0分区、consumer2会消费partition1分区、consumer3会消费 partition2分区。
3个partiton对应2个consumer:
consumer1会消费partition0/partition1分区、consumer2会消费partition2分区。
3个partition对应4个或以上consumer:
仍然只有3个consumer对应3个partition,其他的consumer无法消费消息。
分区分配策略
在kafka中,存在三种分区分配策略,range(默认)、 roundrobin(轮询)、 sticky(粘性)。 在消费端中的ConsumerConfig中,通过partition.assignment.strategy属性来指定分区分配策略。
public static final String PARTITION_ASSIGNMENT_STRATEGY_CONFIG = "partition.assignment.strategy";range(范围分区)
range策略,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
假设我们有10个分区,3个消费者,排完序的分区将会是0, 1, 2, 3, 4, 5, 6, 7, 8, 9,消费者线程排完序将会是C1-0, C2-0, C3-0。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。10 / 3 = 3余1,那么消费者线程 C1-0 将会多消费一个分区。
结果:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C3-0 将消费 7, 8, 9 分区
如果有11个分区:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6, 7 分区
C3-0 将消费 8, 9, 10 分区
如果有2个topic(T1、T2),分别有10个分区:
C1-0 将消费T1的 0, 1, 2, 3 分区以及T2的 0, 1, 2, 3分区
C2-0 将消费T1的 4, 5, 6 分区以及T2的 4, 5, 6分区
C3-0 将消费T1的 7, 8, 9 分区以及T2的 7, 8, 9分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了2个分区,这就是Range strategy的一个很明显的弊端。
roundrobin(轮询分区)
轮询分区策略是把所有partition和所有consumer线程都列出来,然后按照hashcode进行排序。最后通 过轮询算法分配partition给消费线程。如果所有consumer实例的订阅是相同的,那么partition会均匀分布。
假如按照 hashCode 排序完的topic-partitions组依次为T1-5, T1-3, T1-0, T1-8, T1- 2, T1-1, T1-4, T1-7, T1-6, T1-9,消费者线程排序为C1-0, C1-1, C2-0, C2-1,最后分区分配的结果为:
C1-0 将消费 T1-5, T1-2, T1-6 分区
C1-1 将消费 T1-3, T1-1, T1-9 分区
C2-0 将消费 T1-0, T1-4 分区
C2-1 将消费 T1-8, T1-7 分区
sticky(粘滞策略)
粘滞策略主要有两个目的:
1.分区的分配尽可能的均匀;
2.分区的分配尽可能和上次分配保持相同。
假设消费组有3个消费者:C0、C1、C2,它们分别订阅了4个Topic(t0、t1、t2、t3),并且每个主题有两个分区(p0、p1),也就是说,整个消费组订阅了8个分区:t0p0 、 t0p1 、 t1p0 、 t1p1 、 t2p0 、 t2p1 、t3p0 、 t3p1,那么最终的分配场景结果为:
C0:t0p0、t1p1、t3p0
C1:t0p1、t2p0、t3p1
C2:t1p0、t2p1
这种分配方式有点类似于轮询策略,但实际上并不是,因为假设这个时候,C1这个消费者挂了,就势必会造成 重新分区(reblance),如果是轮询,那么结果应该是:
C0:t0p0、t1p0、t2p0、t3p0
C2:t0p1、t1p1、t2p1、t3p1
然而,strickyAssignor它是一种粘滞策略,所以它会满足分区的分配尽可能和上次分配保持相同,所以 分配结果应该是
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
也就是说,C0和C2保留了上一次是的分配结果,并且把原来C1的分区分配给了C0和C2。 这种策略的好处是 使得分区发生变化时,由于分区的粘性,减少了不必要的分区移动。
Coordinator(协调者)
Kafka提供了一个角色Coordinator,来执行对于consumer group的管理。Coordinator会在zookeeper上添加watcher,当消费者加入或者退出consumer group时,会修改zookeeper上保存的数据,从而触发Coordinator开始Rebalance操作。
consumer group如何确定自己的coordinator是谁呢?
消费者向kafka集群中的任意一个broker发送一个 GroupCoordinatorRequest请求,服务端会返回一个负载最小的broker节点的id,并将该broker设置为coordinator。
JoinGroup与Synchronizing Group State
在rebalance之前,需要保证Coordinator是已经确定好了的,整个rebalance的过程分为两个步骤:Join和Sync。
Join
Join表示加入到consumer group中,在这一步中,所有的成员都会向Coordinator发送joinGroup的请 求。一旦所有成员都发送了joinGroup请求,那么Coordinator会选择一个consumer担任leader角色, 并把组成员信息和订阅信息发送消费者。
leader选举算法比较简单,如果消费组内没有leader,那么第一个加入消费组的消费者就是消费者 leader,如果这个时候leader消费者退出了消费组,那么重新选举一个leader,这个选举很随意,类似于随机算法。
每个消费者都可以设置自己的分区分配策略,对于消费组而言,Coordinator会从各个消费者上报过来的分区分配策略中选举一个,具体由各个消费者投票来决定。
Sync
完成Join过程之后,就进入了Synchronizing Group State阶段。简单来说,就是leader将消费者对应的partition分配方案通过Coordinator同步给consumer group中的所有consumer。
offset
每个topic可以划分一个或多个分区,同一topic下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个 offset(偏移量),它是消息在此分区中的唯一编号,kafka通过offset保证消息在分区内的顺序,offset的顺序不跨分区,即kafka只保证在同一个分区内的消息是有序的。对于应用层的消费来说,每次消费一个消息并且提交以后,会保存当前消息到的最近的一个offset。
offset在哪里维护?
在kafka中,提供了一个consumer_offsets_* 的一个topic,把offset信息写入到这个topic中。 consumer_offsets保存了每个consumer group某一时刻提交的offset信息。 consumer_offsets 默认有50个分区,默认保存在/tmp/kafka-log路径下。
分区的副本机制
Kafka的每个topic都可以分为多个partition,并且多个partition会均匀分布在集群的各个节点下。虽然这种方式能够有效的对数据进行分片,但是对于每个partition来说,都是单点的,当其中一个partition不可用的时候,那么这部分消息就没办法消费。所以kafka为了提高partition的可靠性,提供了副本的概念,通过副本机制来实现冗余备份。
每个分区可以有多个副本,并且在副本集合中会存在一个leader的副本,所有的读写请求都是由leader 副本来进行处理。剩余的其他副本都做为follower副本,follower副本会从leader副本同步消息日志。 这个有点类似zookeeper中leader和follower的概念,但是具体的实现方式还是有比较大的差异。所以 我们可以认为,副本集会存在一主多从的关系。
一般情况下,同一个分区的多个副本会被均匀分配到集群中的不同broker上,当leader副本所在的 broker出现故障后,可以重新选举新的leader副本继续对外提供服务。通过这样的副本机制来提高 kafka集群的可用性。

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)